Paper Review Part 1
I understand the hard-work a researcher has to go through to get a publication or continuing research. As a researcher I take ideas from multiple sources for my own research to contribute in a effective way towards my fields. It is absolutely devilish/unacceptable to knowingly plagiarize/steal ideas from people without properly crediting them.
This blog contains review of different interesting papers for my personal interest. I have tried to cite them in a correct way all the way. Please let me know If I have mistaken to cite something in the proper way. Moreover I would be glad if somebody wants to discuss/ argue with my understandings. I am always flexible to change my understanding based on facts. {(zhasan3@umbc.edu) subject: Missed citation in proper way/ Paper discussion from blog}
Paper List
- Clevrer: Kexin et al 2019
- Style Gan- Tero Karras et al 2018
- Style transfer - Xun Huang et al 2017
- Lottery ticket hypothesis - J. Frankel et al 2018
- Temporal 3D ConvNets
- Virtual Pooling
- VitaMon
Paper1
Clevrer: Collision events for video representation and reasoning [1]
IMRAD
Missing in datasets; underlying logic, temporal and causal structure behind the reasoning process!! they study these gaps from complementary perspective.
Video reasoning models! - provide benchmark - Video dataset proposal!
Motivation: CLEVR, psychology

Figure: Sample from the dataset [1]
Analysis of various visual reasoning models on the CLEVRER.
Prior Arts
Video Understanding, VQA, Physical and Causal reasoning.
Argument and Assumption/ Context
Dataset to fill the missing domain should: Video, diagnostic annotation, temporal relation, Explanation, prediction, counterfactual. Need to match this.

Figure: Dataset Comparison [1]
Problem statement
Missing in datasets; underlying logic, temporal and causal structure behind the reasoning process!! Can we prepare a dataset covering this missing links!
contribution
Dataset
NS-DR model ??
Approach and Experiments:
Controlled environment. Offered CLEVRER dataset. CLEVRER:
- 10000, 5000, 5000 (T/V/T) - 5 seconds videos
- Object and events:
- Causal structure
- Video Generation - Simulator
- 4 types of Quesions
Evaluations
used base line models:
- Language-only models: Q-types, LSTM, weak baseline
- VQA: CNN + LSTM, TVQA,
- Compositional visual reasoning: IEP, combined with Various implementation tricks.

Figure: Evaluated models [1]
Results:
Show different model strengths.
Neuro-Symbolic Dynamic Reasoning - Model
oracle model
- Video Frame parser - Mask RCNN
- Neural Dynamic Predictor - PropNet
- Question Parser - Attention based seq2seq model
- Program Executor -
My thoughts
- Oracle Model
- How it concludes other model strengths
Key ideas & Piece of Pie
Better dataset preparation
Reference
[1] Yi, Kexin, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. “Clevrer: Collision events for video representation and reasoning.” arXiv preprint arXiv:1910.01442 (2019).
Paper2
A Style-Based Generator Architecture for Generative Adversarial Networks [2]
IMRAD
- Gap in GAN latent spaces properties understanding
- Gap in measuring factor of variation without enc-dec.
- Generator comparison!
- Motivation from style transfer literature
- No change in loss function
Prior Arts
Argument and Assumption/ Context
- AdaIN can be expanded beyond encoder-decoder settings.
- Disentanglement can be used as generator improvement measures.
Problem statement
Traditional GAN generator improvement via style learning layer by layer. Can the feature be better selected by introducing a trick before feeding to generator? Is it possible to entangle the styles and features?
contribution
- Style based generator proposal
- No change in GAN loss/ Discriminator
- Argues - intermediate latent space doesn’t have to follow the distribution of Input
- Two metrics propose - Perceptual path length and Linear separability
- FFHQ dataset
Approach and Experiments:
Style based Generator:
- Architecture:
From random vector, z, to a vector space, w, of same size (I guess loss backpropagates here too). Affine transformation learn (how?) from w to y (Get y from random vector instead of style image!). Then the AdaIN layer.
Noise (Gaussian noise) introduction cause stochastic variation in the generated images.
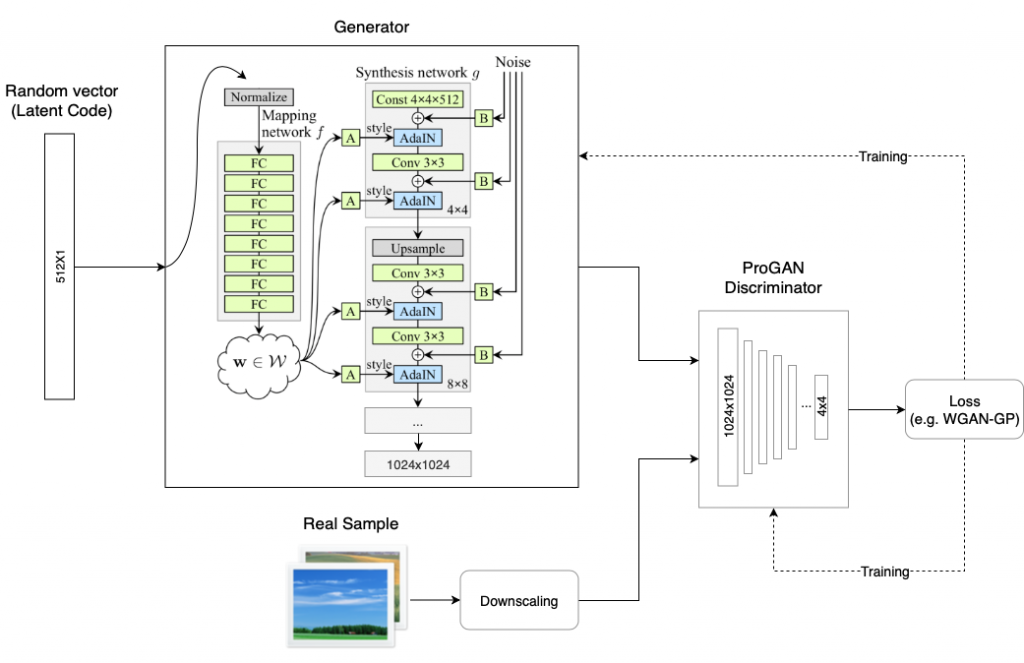
Figure: Source
Important Note about Style generator: Each layer overridden by next AdaIN operation. Each AdaIN controls one CNN. As normalization and rescaling happen after each layers.
- Style Mixing: Mixing regularization. Switch from one latent code to another at random points. Has option to add the style at different scale in the generator network. Two latent codes z1 and z1 generated for the two sets of images.
- stochastic variation: Hair line, number, eye color etc. - controlled by the noise.
- Separation of global effects from stochasticity: Pose, lightening, - controlled by the latent space.
Disentanglement studies: Latent space consists of linear subspaces each basis controls one factor of variation. Latent space W can be learned from the random vector by f(z).
- Perceptual path length: Pairwise image distance as a weighted difference between two VGG16 embeddings. The authors used R. Zhang et al 2018 metrics. A bit different from only taking layerwise distance in VGG16 layers, spherical interpolation between latent space vectors.
where,
and
-
Linear separability: Distinguished set for distinguished features. How much entropy has reduce in H(Y X); Where Y is the image label and X is the feature label.
Evaluations
Results:
- Experiment without any styles
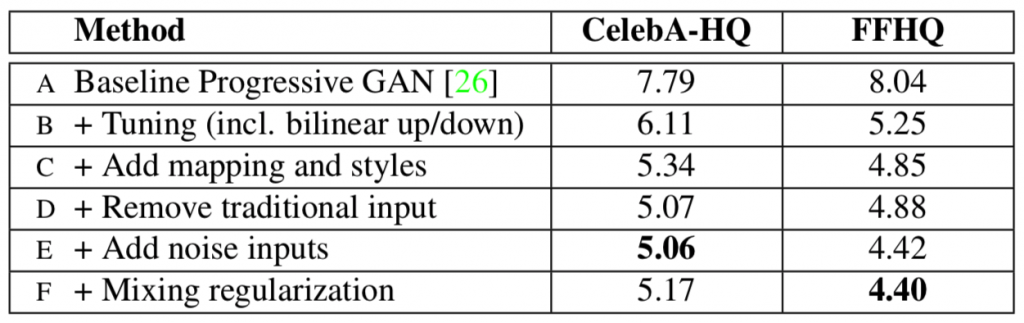
Figure: Source [2]
My thoughts
Not the traditional style transfer from one image to another. Rather a group to another. There is no image input here, only the random vector like the original GAN.
Key ideas & Piece of Pie
AdaIN in generator. Feature transform network for the latent random variables.
Reference
[2] Karras, Tero, Samuli Laine, and Timo Aila. “A style-based generator architecture for generative adversarial networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
(R. Zhang et al 2018) R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. CVPR, 2018. 6, 7
Paper3
Arbitrary Style transfer in Real-time with Adaptive Instance Normalization [3]
IMRAD
- Gap in finite styles and slower
- Motivated from Instance Normalization
- Extension of IN based on observation
-
Encoder-decoder structure (In between proposes an AdaIN layer)
- Architectural and Loss function contribution
- Conceptual difference between earlier and this method
- Directly changes statistics in feature space in One Shot - instead of pixel value manipulation
Prior Arts
- Style transfer
- Deep generative image model
Argument and Assumption/ Context
- IN performs style normalization by normalizing features stats that carries style information.
- Need to change the statistics of the contents to match the style
- Extension of IN - AdaIN
- Need something in between Encoder-Decoder
- Style transfer occurs in AdaIN layer
Problem statement
Can the generation be more depend on the statistical features instead of the pixel value itself? Can the features be transferred by statistically to match the style?
contribution (Piece of Pie)
AdaIN
- Given contents and Style AdaIN adjusts the mean, variance of contents to the styles
- Decoder to convert AdaIN output
- User control and time
- Style transfer happens here
Background
- Batch Normalization layer: Across individual feature channel
Where
and SD accordingly.
- Instance Normalization layer: The difference in computing mean and SD from the BN.
and SD accordingly.
- Conditional Instance Normalization:
Approach and Experiments:
Preprocessing
- resize, Batch size- 8, Adam
Architecture:
Encoder f, Adaptive IN layer, Decoder g
- Adaptive Instance Normalization: (AdaIN)
Features t,
And reconstructed image
uses pretrained VGG19 models

Figure: Mind the AdaIN layer in between enc-dec. [3]
Loss Function: Weighted sum of the two losses
- Content Loss: Euclidean distance between the AdaIN features and dec-enc(AdaIN features).
- Style loss: Measures the loss between the statistics of the generated image and the style image in the VGG19 Layer stages (Authors used relu 1 to 4).
Evaluations
Results:
Dataset
- MS-COCO dataset
- WikiArt
Metrics
- Quantitative Analysis
- Qualitative Analysis
- Speed analysis
Alternatives:
- Enc-AdaIn-Dec (this paper)
- Enc-concat-Dec (earlier method)
- Enc-AdaIN-BNDec (this)
- Enc-AdaIN-INDec (this)
Controls (No modify in the training) in test-time
- Content-style trade-Off:
Convex interpolation between output of encoder and the AdaIN.
Example

Figure: Source [3]
To interpolate set of K styles, the authors performs convex weighted sum of the AdaIN features for the K styles
- Style interpolation
To interpolate set of K styles, the authors performs convex weighted sum of the AdaIN features for the K styles
Example

Figure: Source [3]
- Spatial and color control: Different style in different image portions.
My thoughts
Key ideas & Piece of Pie
Reference
[3] Huang, Xun, and Serge Belongie. “Arbitrary style transfer in real-time with adaptive instance normalization.” In Proceedings of the IEEE International Conference on Computer Vision, pp. 1501-1510. 2017.
Paper4
THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS [4]
IMRAD
Train smaller network instead of prune. Pruned network hard to train. Sparse network slow learning. Smaller subnetwork!
Randomly-initialized, dense NN contains subnetwork already initialized such way - trained in isolation - it can match the test accuracy of the original network after training at most same number of iteration.
Mathematically
Initially
Finally reach, test accuracy a, validation loss l, at iteration j
And reach, test accuracy a’, validation loss l’, at iteration j’. Now according to lottery ticket hypothesis, there exist such m that j>j’, a<a’ and finally m has fewer 1.
Need appropriate initialization. Train with full network, and prune to get wining tickets. And reset to original initial values to the remaining weights.
- Pruning uncovers trainable subnrtwork
- Faster training
- propose lottery ticket hypothesis.
Implication - Improve training performance, design better network, and improve theoretical understand.
Prior Arts
Argument and Assumption/ Context
Only few weights are important (they depends on the initialization). Different initialization gives different important weights. Given same initialization the weights will reach same conclusion.
Problem statement
Can we train smaller network, not prune. - by initialization appropriately.
contribution (Piece of Pie)
Computer vision task small subnet with appropriate initialization learns the same task of the big network with parameters.
Background
Approach and Experiments:
On Fully connected
- iterative Pruning
- Random reinitialization
- One-shot pruning
Convolutional network.
- Finding wining tickets
- Random reinitialization
- Dropout More experiment on the VGG and RESNET for cifar dataset
Evaluations strengths and Weakness
Weakness: Only on image and small dataset! Learning rate dependency
Results:
Exhaustive result on 1. Pruning strategy 2. Early stopping 3. Training accuracy 4. Comparing random reinitialization and random sparsity 5. Examine winning tickets. 6. Hyperparameter exploration for fully connected networks 7. Hyperparameter exploration for CNN 8. Hyperparameter for VGG and RESNET
My thoughts
Key ideas & Piece of Pie
Different initialization gives different important weights. Given same initialization the weights will reach same conclusion.
Reference
[4] Frankle, Jonathan, and Michael Carbin. “The lottery ticket hypothesis: Finding sparse, trainable neural networks.” arXiv preprint arXiv:1803.03635 (2018).
Paper5
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification [5]
IMRAD
Problems: Conv3d fails to capture long term relationships in video frames and over-parameterized! Dependencies on the optical-flow features.
Propose net architecture (Motivated from cond2d DenseNet) for feature extraction in video action recognition. Notion of 3D temporal transition layer (TTL).
Claim to be efficient representation, computational efficient and robust. Evaluated on three dataset: HMDB51, UCF101, Kinetics. (T3D)
Additional contribution: Supervised transfer across architecture for weight initialization. (student teacher knowledge distillation).
Prior Arts
Three related line of research: Video classification, temporal convNets, transfer learning.
Argument and Assumption/ Context
Problem statement
contribution (Piece of Pie)
Conv3D DenseNet with TTL for video AR. Cross architecture Knowledge distillation initialization for the AR from Image net. End2End training.
Background
Conv2D DenseNet, google Net,
Approach and Experiments:
Architecture:
 Figure: Overall architecture [5] TTL with multiple temporal consideration. Denseblock is similar to 2d ConvNet but for 3D convnet.
Figure: Overall architecture [5] TTL with multiple temporal consideration. Denseblock is similar to 2d ConvNet but for 3D convnet.
Transfer Leraning:
- Pretrained imagenet and random initialized conv3D net layers.
- Pass the considered frames throught imagenet and find average of 1024 points
- Pass the frames through conv3D architecture.
- 1 if the conv2D and Conv3d features are from same video frames else 0 (Different video frames) (matching pair): Unsupervised setting
- Train only the 3D convNet
 Figure: Knowledge transfer from 2D Dense pre-trained imagenet to activity recognition. [5]
Figure: Knowledge transfer from 2D Dense pre-trained imagenet to activity recognition. [5]
Model depth increases accuracy!
Experiments with multi frame resolutions.
Pytorch and GPU implementation. Experiments with both the supervised transfer and train from scratch (Kinetics dataset).
Comparison with 3D convnet based on inception and ResNet.
Evaluations strengths and Weakness
Results:
State of the art performance using supervised pretraining.
My thoughts
Cross domain transfer! How long to pretrain! Parameters claim validation! Ablation study description! Frame rate and size dependency.
Key ideas & Piece of Pie
Cross domain transfer prtraining.
Reference
[5] Diba, Ali, Mohsen Fayyaz, Vivek Sharma, Amir Hossein Karami, Mohammad Mahdi Arzani, Rahman Yousefzadeh, and Luc Van Gool. “Temporal 3d convnets: New architecture and transfer learning for video classification.” arXiv preprint arXiv:1711.08200 (2017).
Paper6
ViP: Virtual Pooling for Accelerating CNN-based Image Classification and Object Detection [6]
IMRAD
New pooling method. Computes only some of the filtered activation layers and interpolate the rest. Can be added with existing network. Provide error bound by taking the ViP layer.
Prior Arts
CNN acceleration:
- Model compression
- CNN binarization or quantization
- Low rank approximation
- PerforatedCNNs (closest)
Argument and Assumption/ Context
Redundancy in spatial can be removed by taking some intermediate values and interpolating the rest. So less compute for the closest values. Compute values in fixed interval and interpolate the missing points in each filter output for each channel.
Problem statement
Improve PerforatedCNNs by removing data dependency. Can we leverage the spatial Redundancy in CNN channel?
contribution (Piece of Pie)
CNN computation reduction. Find only some intermediate values and linear interpolate the rest.
Background
Approach and Experiments:
Algorithm for the ViP
Experimented on
- CNN models: VGG, ResNet, All-CNN, Faster RCNN with VGG-16
- Three dataset
- Two hardware: Mobile and desktop
- Two visual learning tasks
Evaluations strengths and Weakness
So basically dropping one value after another. Does it work on smaller resolution when information in one line! Or low pass filtering over the masked channel!
Results:
Accuracy drops little and computational speed increases significantly.
My thoughts
Key ideas & Piece of Pie
Low pass filter over masked ConV output channel works!
Reference
[6] Chen, Zhuo, Jiyuan Zhang, Ruizhou Ding, and Diana Marculescu. “Vip: Virtual pooling for accelerating cnn-based image classification and object detection.” In The IEEE Winter Conference on Applications of Computer Vision, pp. 1180-1189. 2020.