Trending Topics
So far In this writing I have covered
- Representation
- Region based object detectors
- Region based Convolutional networks
- Deep learning for object detection P2
- Neural Networks Pruning
- Graph Neural Network
- Energy Based Learning
- Video activity recognition
- Multi-task Learning
- Matrix Factorization
1. Representation Learning
Representation learning: A review and new perspective - (Bengio, Y. et al. 2014)
Review paper on unsupervised learning covering probabilistic model, auto-encoders, manifold learning, and deep networks to learn the data Representation.
Representation learning; learning data Representation that make it easier to extract useful information when building classifiers and other predictors.
Application:
- Speech recognition and signal processing
- Object recognition
- NLP
- Multi-Task and transfer learning, Domain Adaptation.
What makes Representation good?
- Priors for Representation Learning in AI
- Smoothness:
- Multiple explanatory factors
- Hierarchical organization of explanatory factors
- Semi-supervised Learning
- Shared factors across task - MT, DA, TL
- Manifolds
- Natural clustering
- Temporal and spatial coherence
- Sparsity
- Simplicity of Factor Dependencies
- Smoothness and the curse of dimensionality
- Distributed representations
- Depth and abstraction - this paper
- Feature re-use
- abstraction and invariance
- Disentangling factors of Variation: information preserving and disentangle factors simultaneously.
- Good criteria for learning representations:
Building Deep Representations
Greedy layerwise unsupervised pre-training- Resulting deep features used as input to another standard classifier. Another approach is greedy layerwise supervised pre-training. Layerwise stacking often leads better representations.
- Stack pre-trained RBM into DBN (wake sleep algorithm)
- Combine RBM parameters into DBM
- Stack RBMs or auto-encoders into a deep auto-encoders.
- Encoder-decoder block
- composition of encoder:
- Decoder block:
- Encoder-decoder block
- Iterative construction of free energy function
single-layer learning modules
Two approaches
- probabilistic graphical model
- Neural networks
PCA connected to probabilistic models, Encoder-decoder, Manifolds
Probabilistic Model
Learning joint distribution and posterior distribution
, where h is the latent variables for x.
1. Directed Graphical Models
Probabilistic interpretation of PCA
Prior;
And the likelihood
Sparse Coding
Clever equation regarding the prior and likelihood. A variation of sparse coding leads to Spike-and-slab sparse coding (S3C). S3C outperforms sparse coding shown by Goodfellow et al.
2. Undirected Graphical Models
Markov random fields. Expressed joint probability as the multiplication of clique potentials. A spacial form of markov random field is Boltzmann distribution with positive clique potentials. Here comes the notion of energy function.
Restricted Boltzmann machines (RBMs)
A little modification in energy function in Boltzmann machines leads to Restricted Boltzmann machines.
Generalizations of the RBM to real-valued data
Directly Learning A parametric Map from input to Representation
Graphical models are intractable for multiple layers.
- Learn a direct encoding; a parametric map from input to their Representation
1. Auto-encoders
encoder
For each data instances
Decoder
Now the objective function to minimize
2. Regularized Auto-encoders
Use a bottleneck by forcing latent space dimension lower than the input space dimention.
Sparse auto-encoders
Applying the sparsity regularization to force the latent representation to be close to zero.
Representation learning as Manifold Learning
May be I will add later.
Connection between probabilistic and Directed encoding Models
Global training in Deep Models
Building in invariance
Generating transformed Examples
Convolution and pooling
Temporal coherence and Slow features
Algorithms to disentangle factors of Variation
2. Region based Object Detectors
3 Parts:
- Faster R-CNN, R-FCN, FPN
- SSD, YOLO, FPN and Focal loss
- Design choices, Lessons learned, and trend for object detection
Sliding-window Detectors
For window in windows
patch = get_patch(image, window)
results = detector(patch)
Selective Search (SS)
This is a very good point to look back and talk about region proposal methods. This is alternative and better version of sliding window detectors. In opencv tutorial there are several proposal methods
- Objectness
- Constrained parametric min-cuts for automatic object segmentation
- Category independent object proposals
- Randomized Prim
- Selective Search
As things stand, among these methods selective search in the most commonly used.
What Fast and high recall. Computing Hierarchical grouping of similar region based on color, texture, size and shape.
- Start by graph based segmentation method. Over segmentation as seed.
- Add bounding box for region proposals
- Group adjacent segments based on similarity
- continue to graph based segmentation.
- similarity
- color similarity is the closeness of the histogram
- Similar for texture similarity (color instead of texture in the previous line)
- Size similarity
targets to smaller region merge early.
- Shape compatibility measures how well they fit in each other.
- color similarity is the closeness of the histogram
Final equation stands, weighted sum of previous four findings.
Region proposal method to find Region of interest (ROIs).
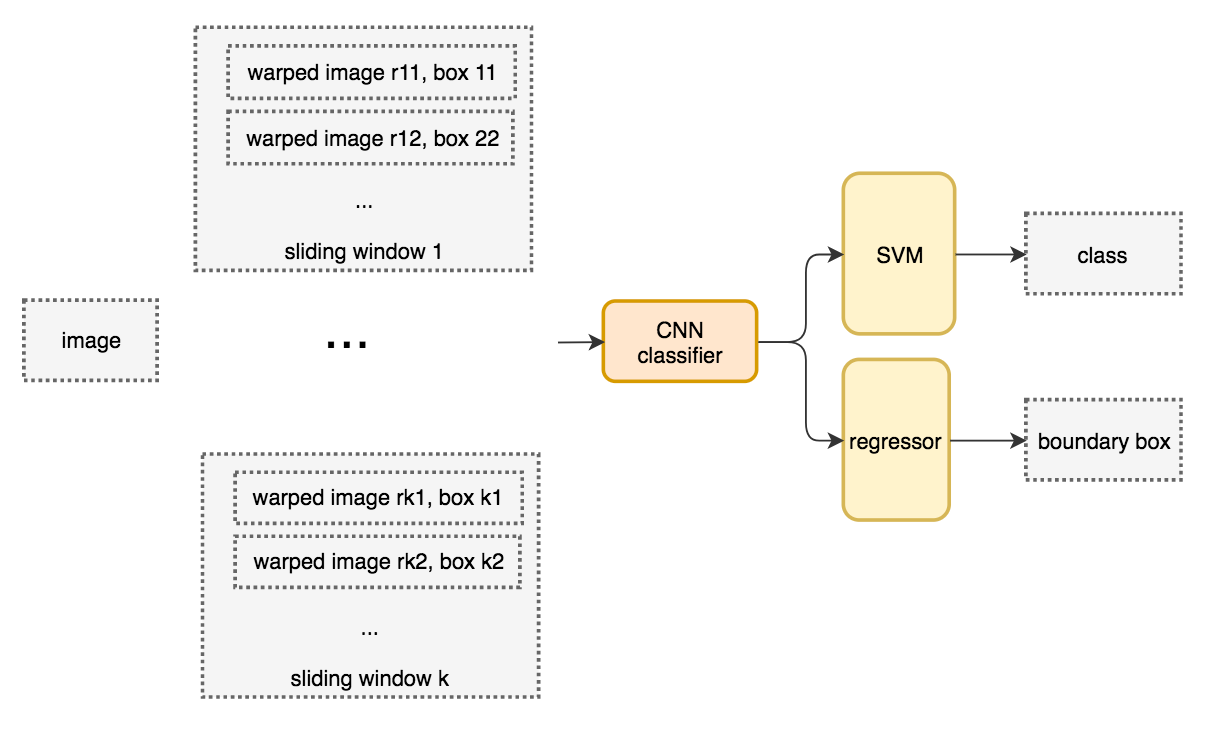
R-CNN
Cares about 2000 ROIs by using a region proposal method. The regions are warped into fixed size images and feed into a CNN network individually. Then followed by fully connected layers to classify and refine the boundary box.
The system flow
Pseudocode
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = detector(patch)
Boundary box regressor
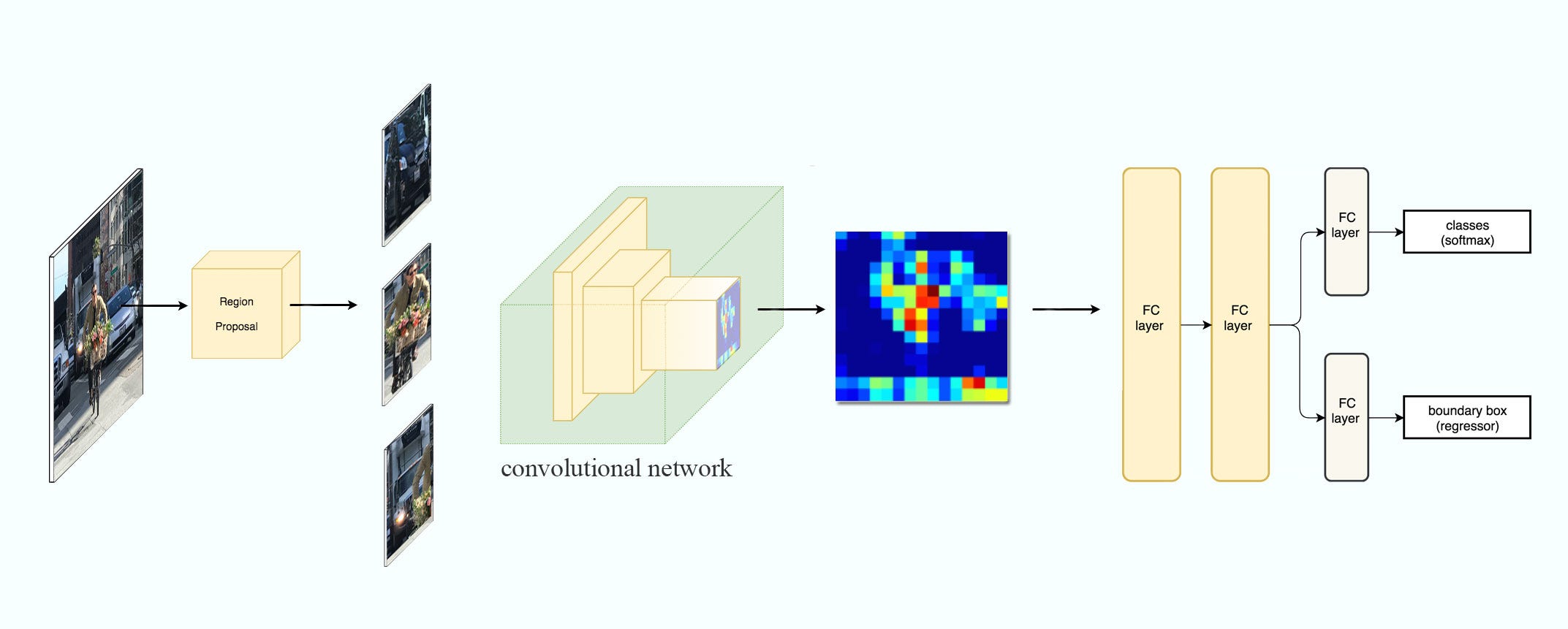
Fast R-CNN
R-CNN is slow. Instead use feature extraction for whole image. It proposes a feature extractor and region proposal method.
Network flow:
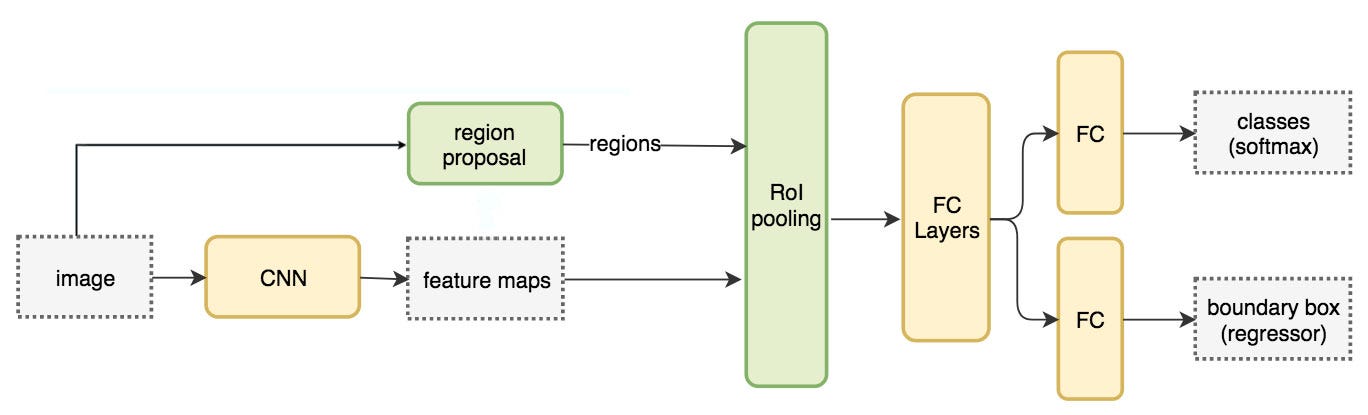
Pseudocode
feature_maps = process(image)
ROIs = region_proposal(image)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
Here comes the multitask loss (Classification and localization loss)
Faster R-CNN
feature_maps = process(image)
ROIs = region_proposal(image) # Expensive!
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
Network flow
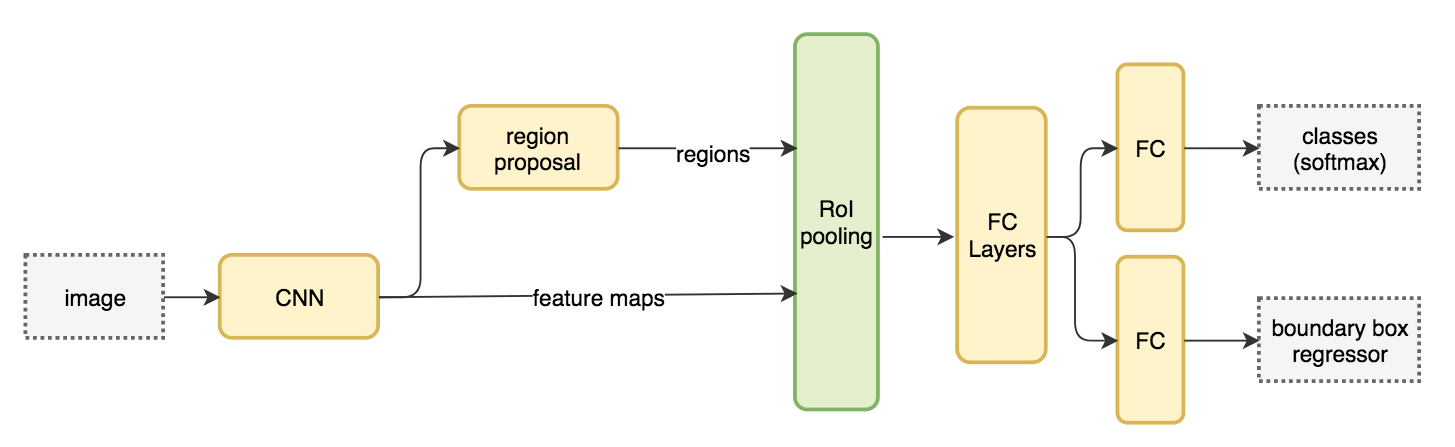
The region proposal is replaced by a Region Proposal network (convolutional network)
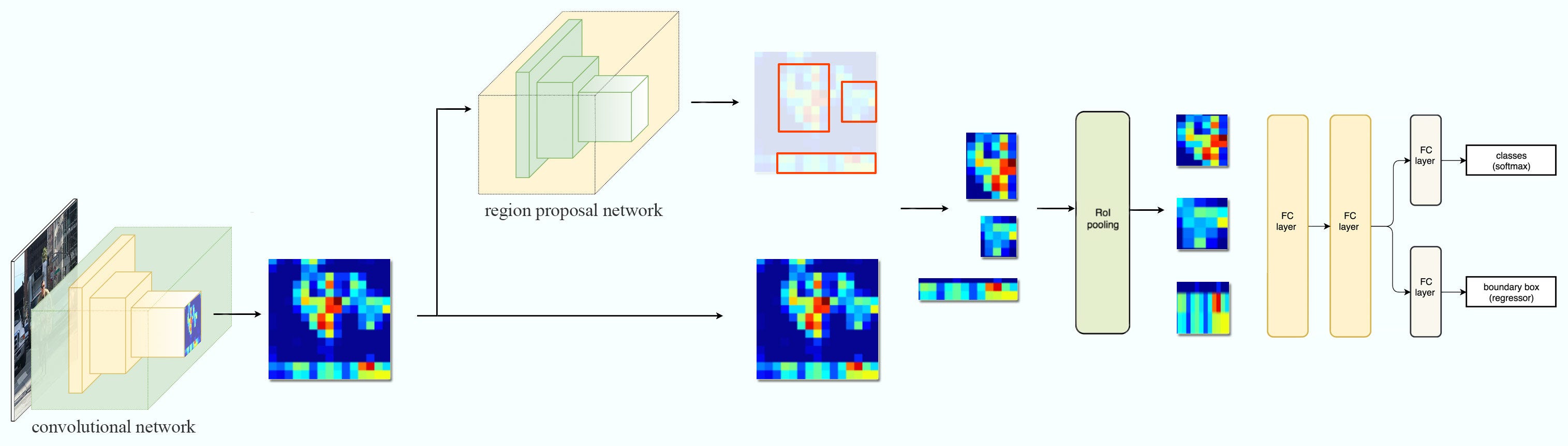
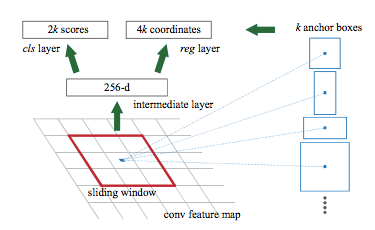
Region Proposal network
ZF networks structure
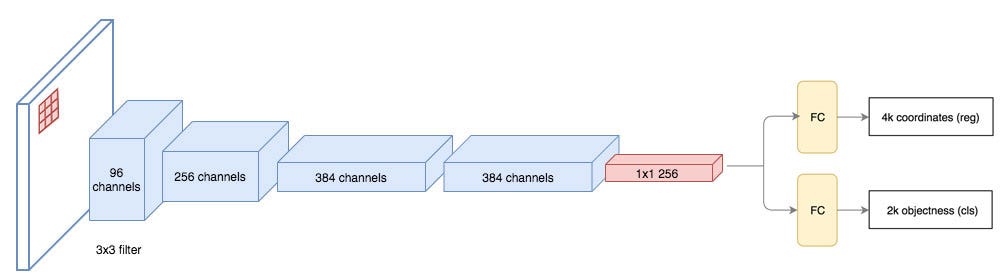
Overcome the problems of the computational complexity of the selective search by offering region proposal after the CNN layer instead of the original image. Three key steps
- Anchor boxes Needs anchor point in feature maps. This is generated by the CNN network. From point we get boxes by defining aspect ratio and width (Determines number of boxes (no of AR* no of Width)). The boxes needs to be scaled with the original images. As we can see above picture network shrink the features. We can counted this by using stride in the original image. EX. if Feats are downsampled by 4 then from the anchor point use 4 stride in the original image.
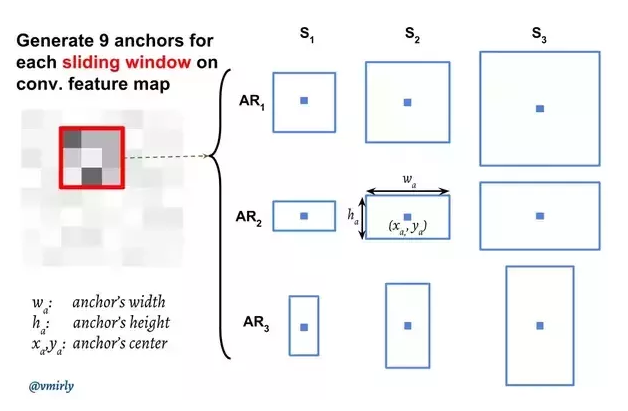
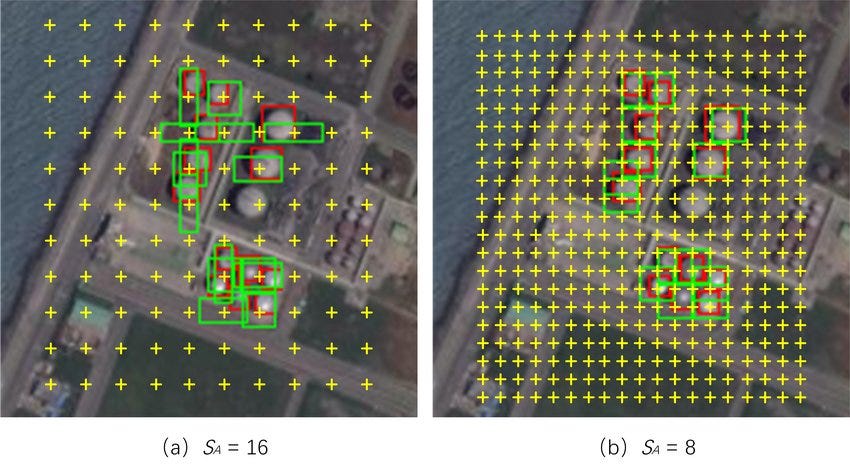
Figure: Source
- Classify the anchor boxes After defining the boxes we need the information about the box contents (background or foreground). The boxes also need to be fixed for the original objects. Again CNN comes to rescue with two output for both class score and boxes point.
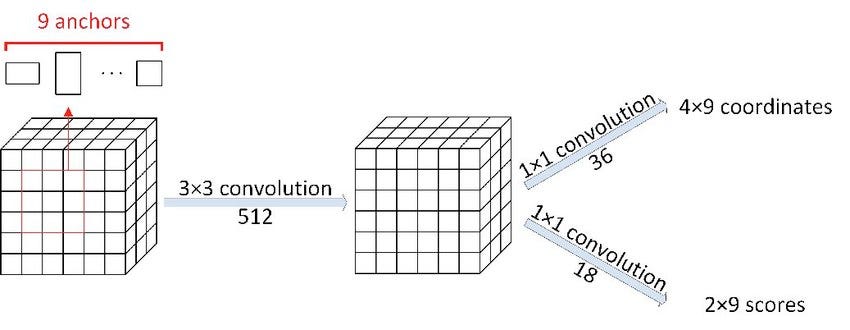
Figure: Source
- Offset for the anchor box to bound the objects We still need to learn the size of the box from the anchor points. This is a regression problem with the true boxes by maximizing IoU with the ground truth. It learns the offset to get the actual boxes (kind of fix the mistake by the backbone CNN). This post processing is named Proposal Generation.
Region-based Fully convolutional Networks (R-FCN)
Faster R-CNN
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
class_scores, box = detector(patch) # Expensive!
class_probabilities = softmax(class_scores)
R-FCN
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
score_maps = compute_score_map(feature_maps)
for ROI in ROIs
V = region_roi_pool(score_maps, ROI)
class_scores, box = average(V) # Much simpler!
class_probabilities = softmax(class_scores)
Networks
SSD
Inspired by blog
SSD eliminates the necessary for the region proposal networks.
- Faster in time (better FPS)
- Accuracy in lower resolution images
- Multiscale features and default boxes
2 parts
- Extract feature maps (VGG16)
- Apply CNN filter to detect objects (4 object predictions) - Each prediction composes of all score + no_object score.
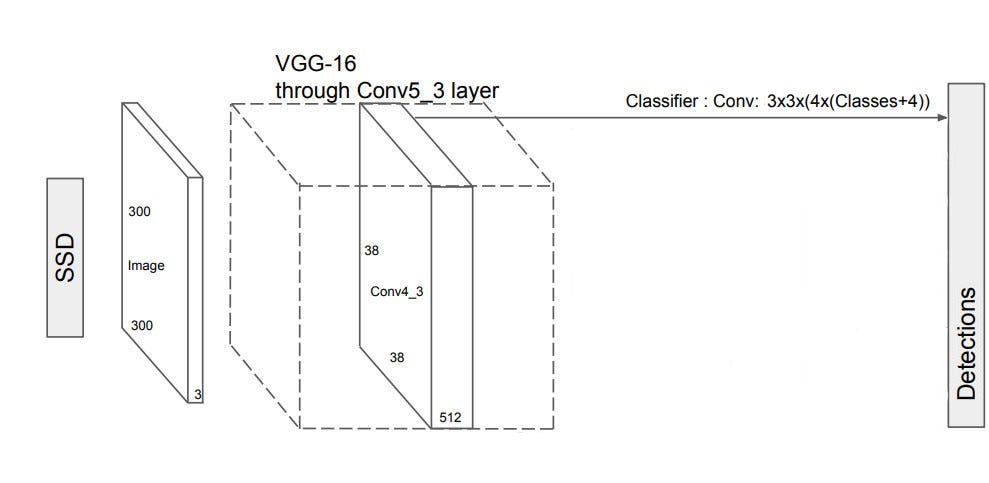
Figure: source (38x38x512 to 38x38x4x(21+4)) The addition 4 are because of the box coordinates.
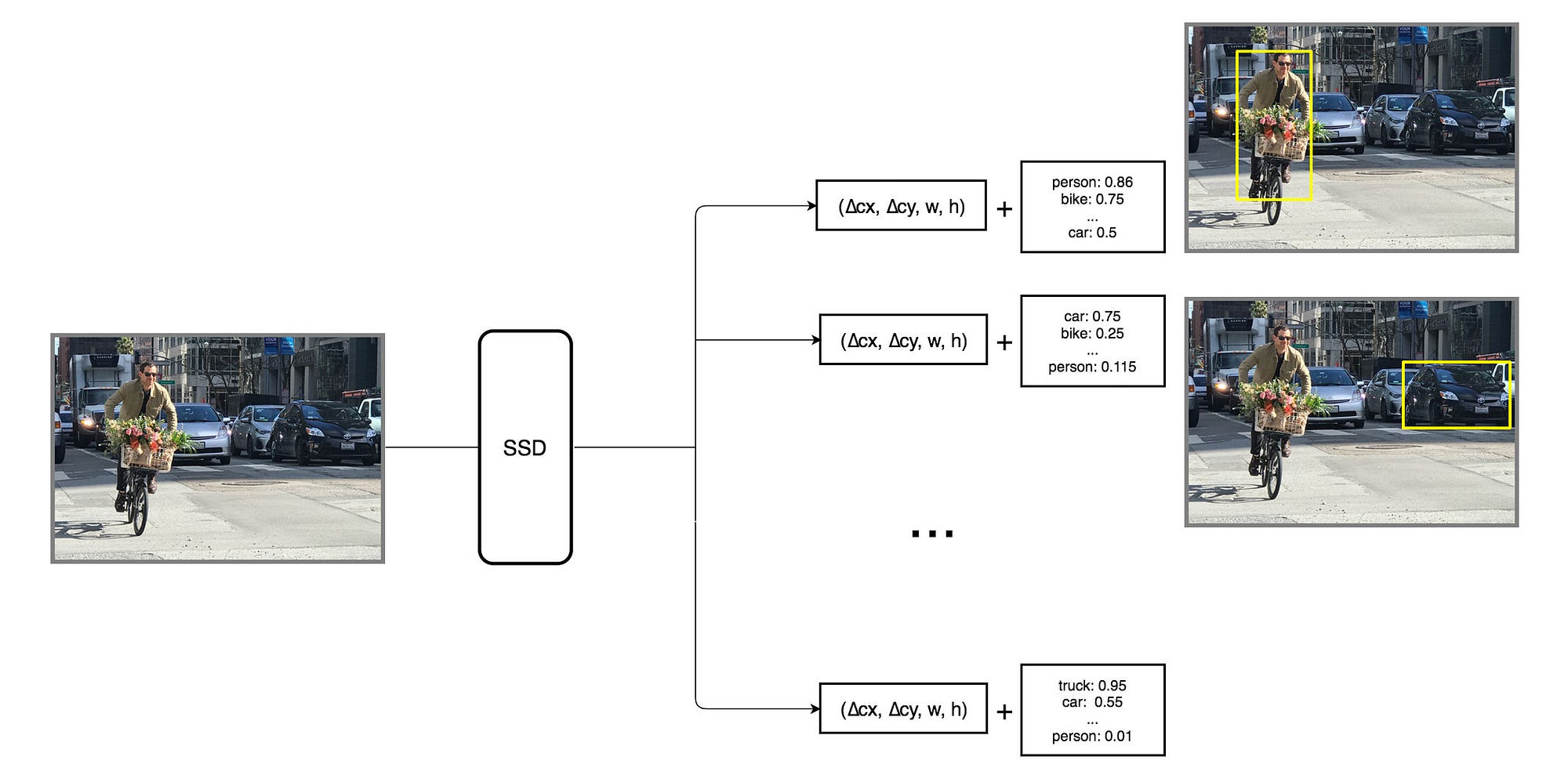
Figure: source
Multibox: Making multiple prediction containing boundary boxes with class score. (4 boxes each with class score)
The core advantages of SSD are the multiscale features.
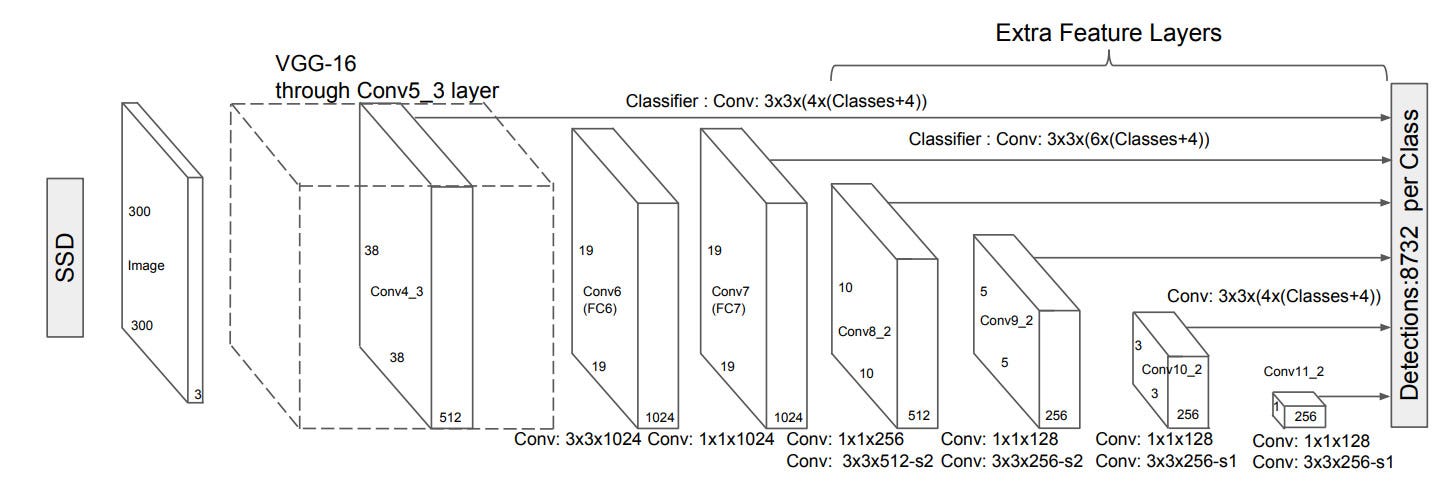
Figure: source paper (At some auxiliary stage SSD takes 6 box predictions)
Default boundary box are similar ideas like anchors in Faster R-CNN. This is the hard part. For this task the model needs to predict different type of boxes shapes. The boundary boxes are chosen manually.
To boxes are annotated as positive/negative based on the IoU of matching boxes with the ground truth.
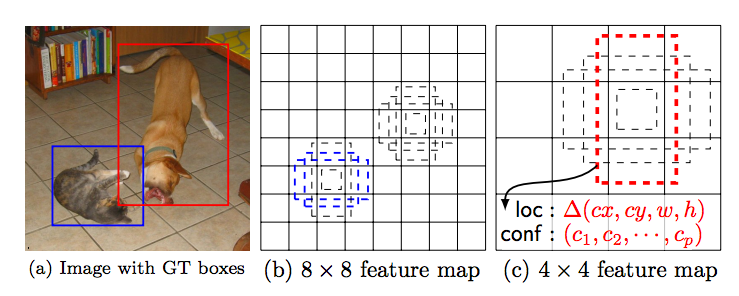
Figure: source Multiscale features and default boundary boxes. Higher resolution maps can detect small objects.
- SSD performs badly for small objects
Loss Function: sum of localization (mismatch between gt and predicted positive matches) loss and confidence loss (Classification loss).

- data mining for negative match as the background selectors. Select a moderate negative example to balance between class imbalances.
- Data augmentation
3. Region based Fully Convolutional networks (R-FCN)
Two stage detection
- Generate region proposals (ROIs)
- Make Classification and localization predictions from ROIs
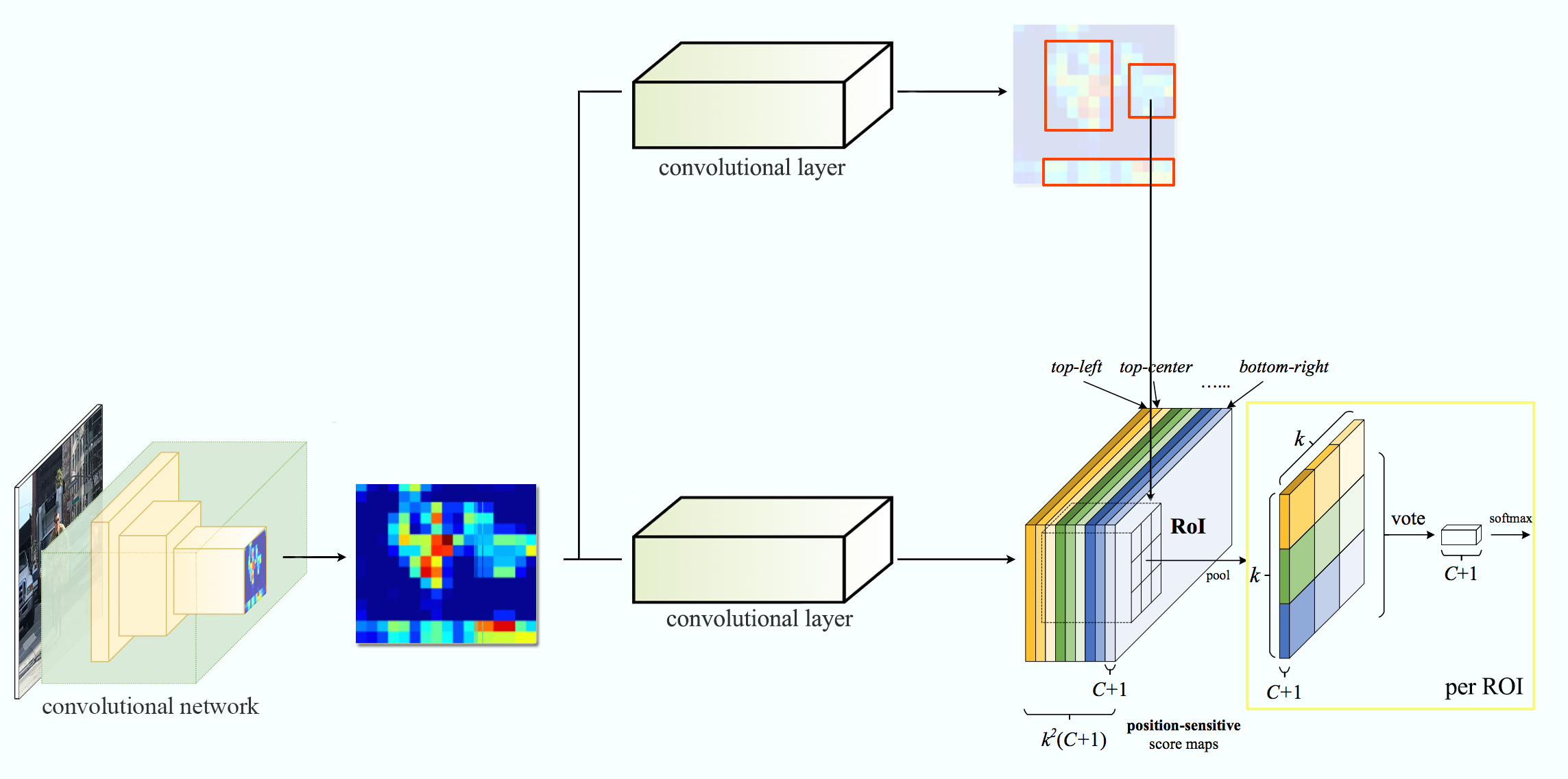
There is a notion of position, leads to position sensitive score maps. Example: For 9 nine features we get nine feature maps.

Now we take map from each feature map depending on the position. From each 9 feature maps we get select one box per feature map and select if for voting.
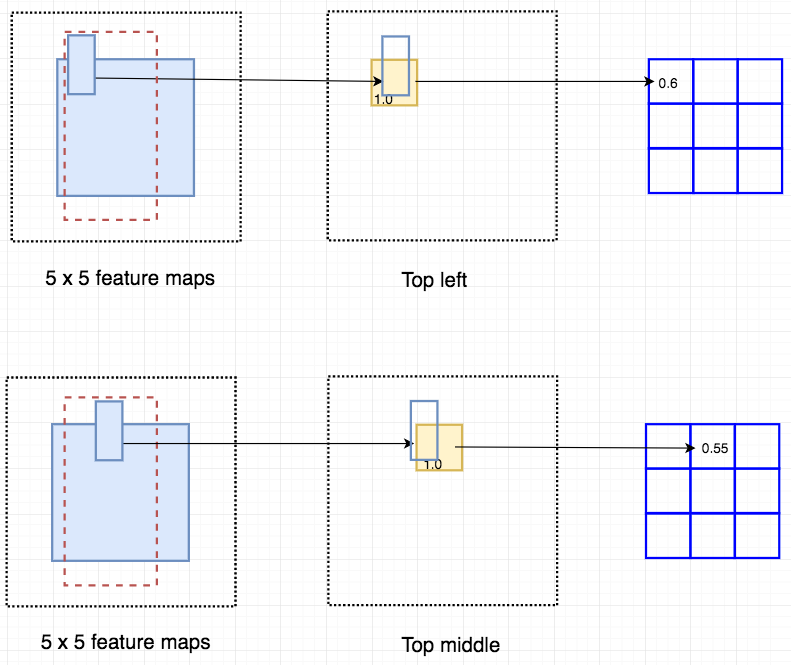
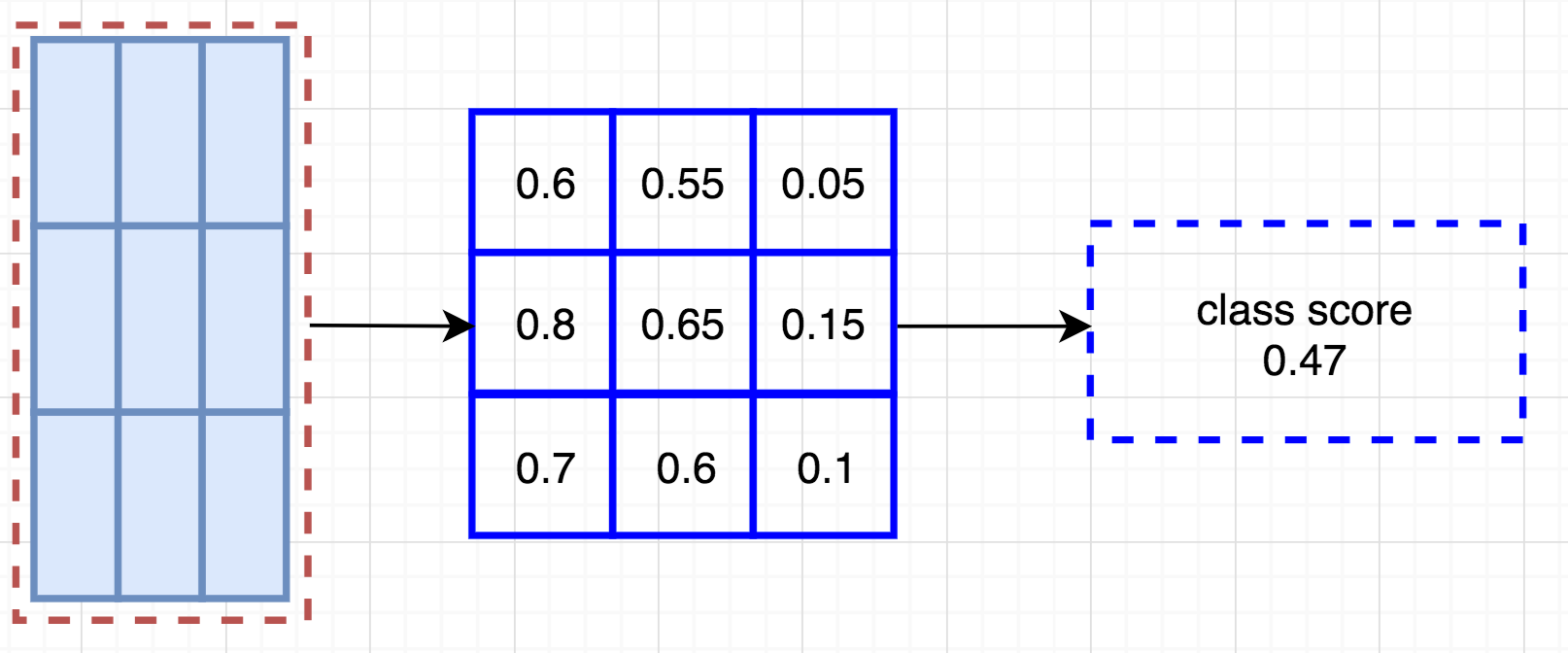
The creates total (C+1)x3x3 score maps. Further example: Person detectors. Total 9 features leads to 9 feature maps. And we select 9 feature maps and get one box from each map to get the voting.

The image of network R-FCN showed above and the following is network followed
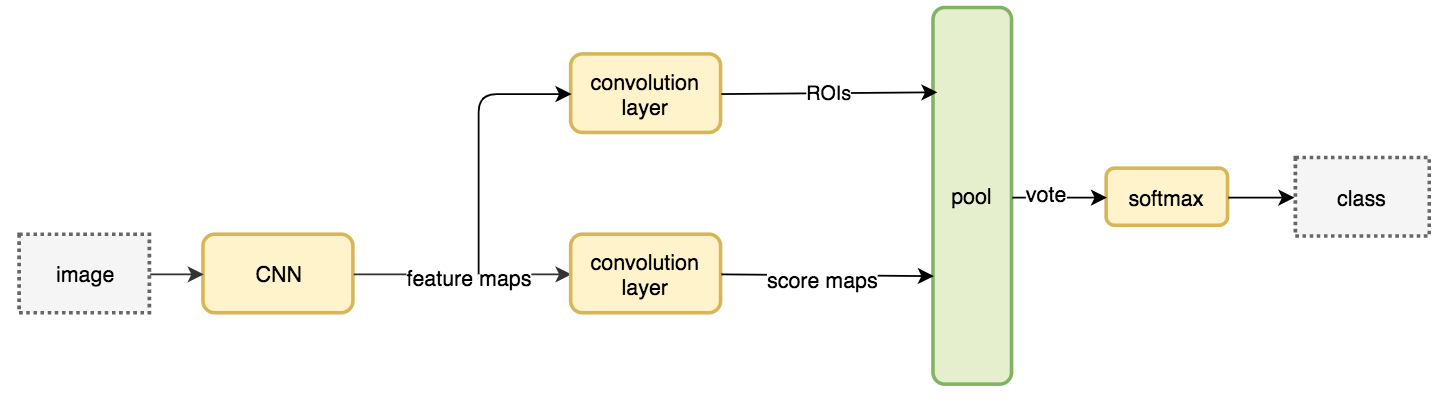
Boundary Box Regression
Convolutional filter creates kxkx(C+1) scope maps. Another convolutional filter to create 4xkxk maps from same features maps. We apply the position based ROI pool to compute KxK array with each element containing boundary box and finally average them.
Region Proposal Network (RPN) - Backbone of Faster R-CNN
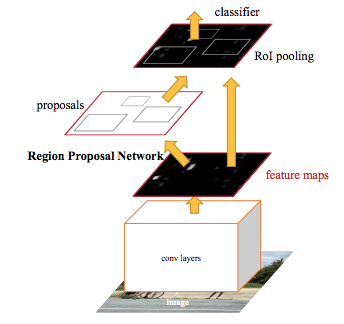
Feature Pyramid Networks (FPN)
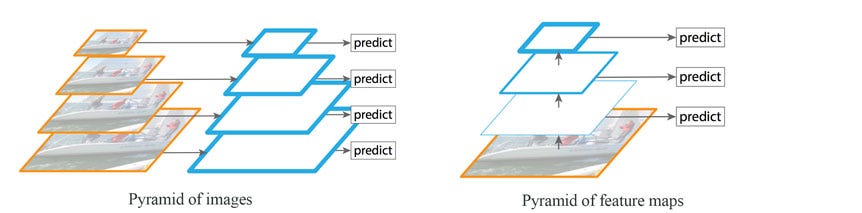
Key Idea: Multi-scale Feature map
Top-down and bottom up data structure:
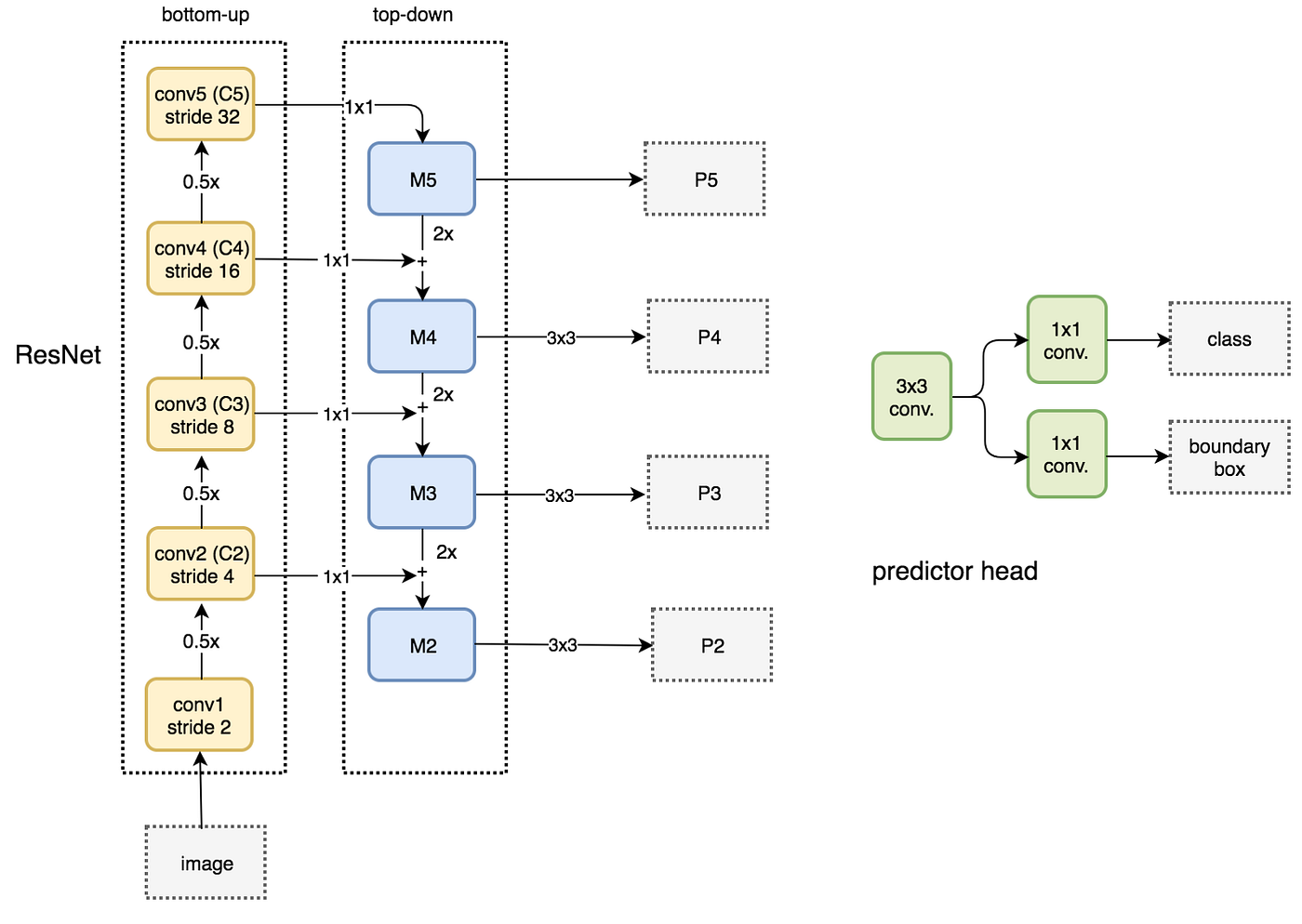 Figure: FPN with RPN (3x3 and 1x1 conv are RPN Head)
Figure: FPN with RPN (3x3 and 1x1 conv are RPN Head)
Total structure
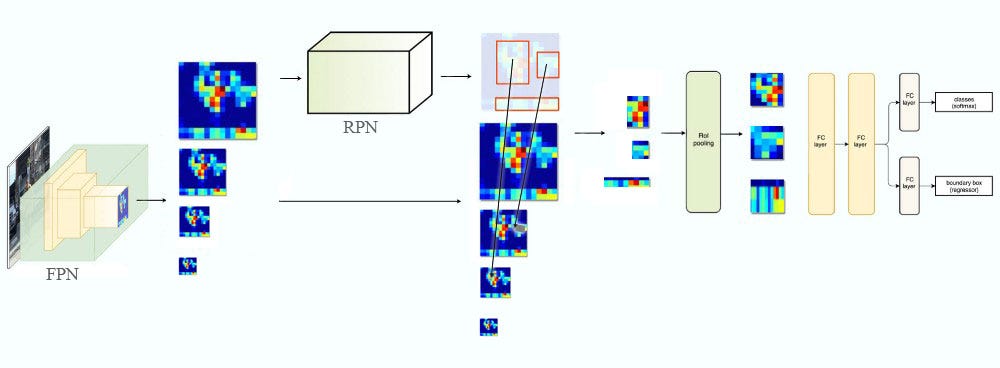
4. Deep learning for object Detection P2
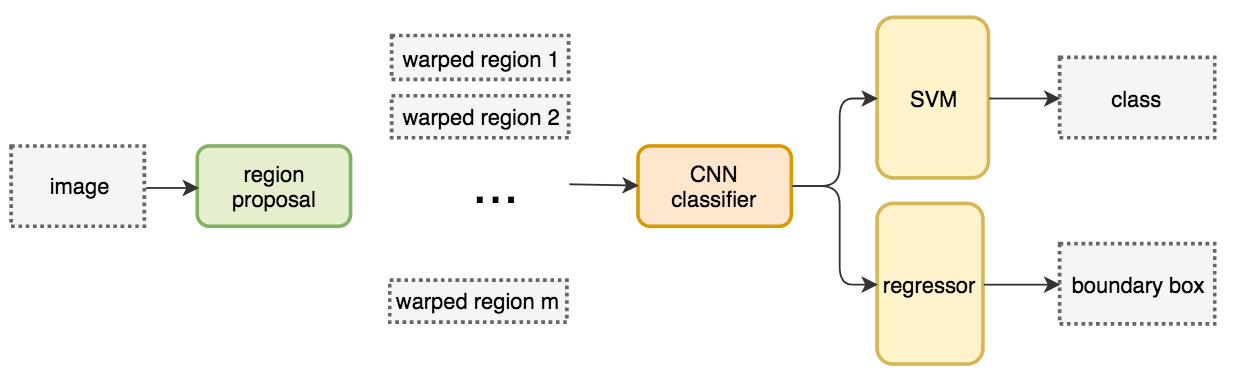
R-CNN and Fast R-CNN
 Figure: R-CNN modules
Figure: R-CNN modules
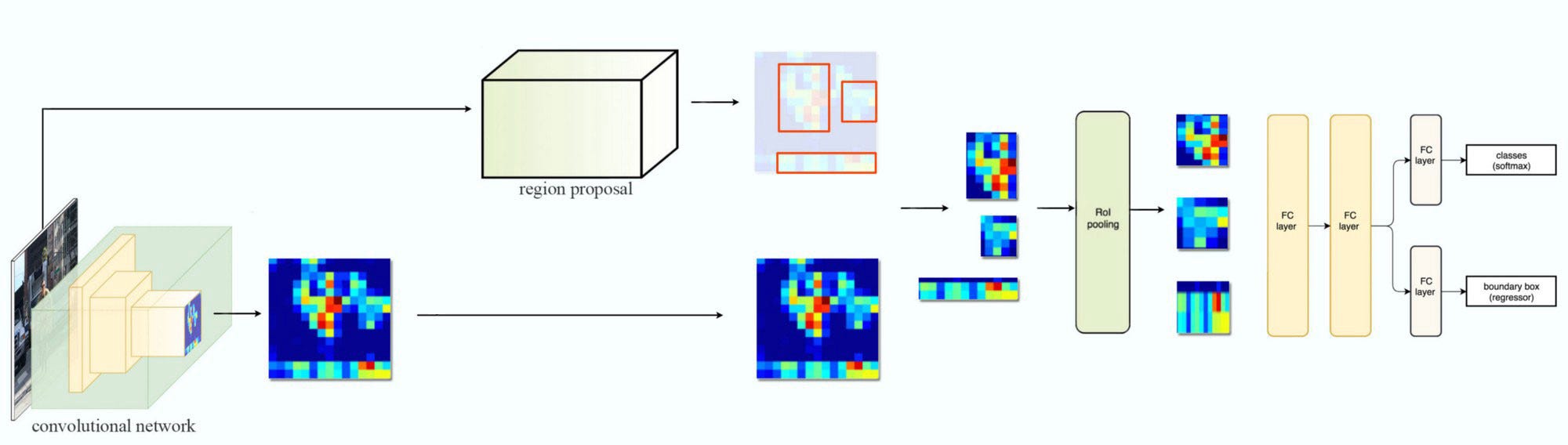
 Figure: Fast R-CNN module
Figure: Fast R-CNN module
Faster R-CNN Architecture
- Region Proposal network
- Feature extraction using CNN
- ROI pooling layer - (Key part)
- Classification and localization
 Figure: Building blocks of Fast R-CNN
Figure: Building blocks of Fast R-CNN
Spatial Pyramid pooling
- Pyramid Representation
- Bag-of-words
 Figure: network with Spatial pyramid pooling layer
Figure: network with Spatial pyramid pooling layer
Fixed size constraint comes only in the fully connected layers.

ROI pooling layer
interesting blog
 ROI vs SPP
ROI vs SPP
 Zooming into the network
Zooming into the network
ROI (Region of interest) converts proposal networks into a fixed shape required for the fully connected layers in classification.
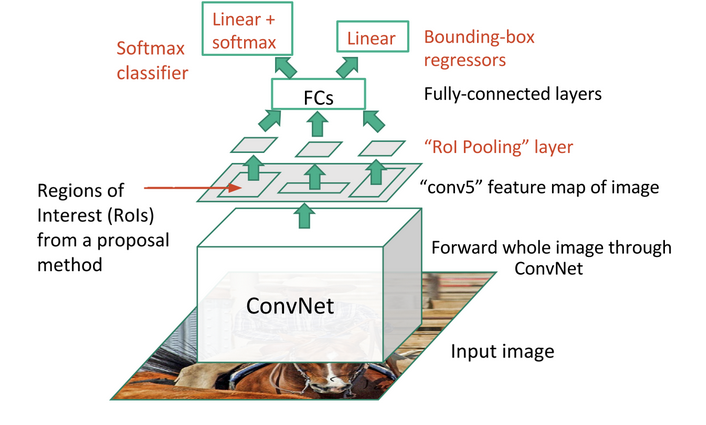 Figure: Source
Figure: Source
ROI takes two inputs
- Feature map from CNN and pooling layers
- It takes indexes and corresponding coordinates for proposal of RPN
ROI pooling layers converts each ROI (regardless of the input feature map or proposal sizes) into a fixed dimension map.
NN prune
detail TL-DR: original inspiration comes from biological synaptic pruning. In neural network, rank the individual weights and drop p% by setting smaller p’s to zero. This is weight pruning. The neurons can also be dropped by dropping the neuron itself. This is done by deleting a whole column of weight matrix based on their L2 norms.
detail TL-DR: Old ideas from Yan Lecun’s. The main point concerns about ranking the neurons. The ranking is usually done by L1/L2 norm of weights, activation, or zero occurance of neuron in validation time, etc. After pruning the NN performance drops which is recovered by retraining iteratively.
Not Popular yet because pain of implemenation, Unstability of ranking method and some genius people’s unwillingness to share.
Some keypoints with reference
-
For CNN the deeper the layer the more it gets pruned paper from Nvidia. Pruning the entire filter. Pruning in each filter or remove some filters entirely. Pruning works better in case of transfer learning.
-
Prune the entire convolutional filter. The following layers also need to be cared. The paper used L1 for ranking and removed the lowest m filters and following layers. Hao Li. et al, UMD and labs america
-
The idea is similar to above but the ranking is complex. The validation set performance of the neurons are considered for the ranking assignment for pruning. paper
-
Formalize the combinatorial optimization problem.
. Where B is subset of weights. This introduces the notion of loss function in pruning to provide more stable results. paper from NVIDIA
- Oracle Pruning: Consider removing each filter and observe the effect. They come up with a Ranking method based on first order Taylor expansion of the cost function. Two subsequent point differ by presence of a filter. The ranking of a particular filer h can be expressed as
and
. This would provide the rank of the layer after L2 norm.
Another way to reduce memory is the Network quantization. more. Two general steps
- Group similar weight values and assign centroid value to all of them
- Group their gradients and put a common value then update the group weights.
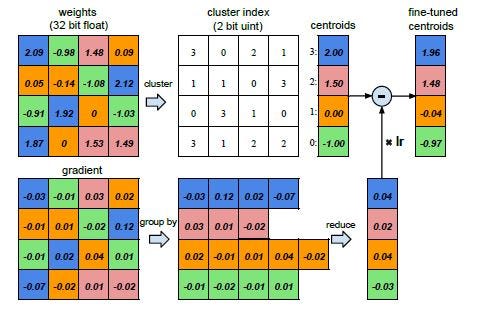
Figure: Quantization simplified. Source.
- Oracle Pruning: Consider removing each filter and observe the effect. They come up with a Ranking method based on first order Taylor expansion of the cost function. Two subsequent point differ by presence of a filter. The ranking of a particular filer h can be expressed as
GraphNN
Very nice survey
Motivation
- CNN
- Graph Embedding
- Non Euclidean
Models: -
Energy Based learning
Introduction
- Capture Dependencies between variables
- Associate scalar energy (measure of capability) to each variable configuration.
- Interferce: Finding remain variables values based on given observed variables to minimize energy Function
- Learning: Associate low energies to correct values of remaining variables.
- Loss function: measure the quality of energy function.
- Unification between probabilitics and non-probabilitic methods.
- Compute energy for all possible Y!
- Energy function has many possible Form
- Appropriate Question
- Which Y most compatible with X
- is Y_1 or Y_2 more compatible with X
- is Y compatible with X
- what is conditional prob. dist. over space of Y given X.
- Cares only about lower energy for correct answer! problem with combining other variables. So, energy to probabilities again!
; beta akin to inverser temrature, Gibbs distribution.
training
Same old parameters, can be parameters to NN
-
So the target becomes
Where S is the total dataset. Can be expanded to traditional instance based formula.
- IN summary Four components
- Architecture: E(W,Y,X)
- Interference algorithm: Method of finding Y to minimize the E(W,X,Y)
- Loss function: Measure the quality of energy function based on the training data
- Learning algorithm: fining W that minimize the loss from a family of energy functions
- Loss function
- Energy loss - Value of E(X_i, Y_i, W)
- Generalized Perceptron Loss - E(X_i, Y_i, W) - min_y E(W, Y, X_i)
- Hinge loss - max(0, m + E(X_i, Y_i, W) - min_{Y_j/=Y_i}E(X_i, Y_i, W))
- Log loss - log(1+ e^{E(X_i, Y_i, W - min_{Y_j/=Y_i}E(X_i, Y_i, W))}
- MCE loss = f(E(X_i, Y_i, W - min_{Y_j/=Y_i}E(X_i, Y_i, W))) - f may be step function
- Square - Square Loss function:
- Square exponential loss =
- Simple Architecture:
- regressor
- two class classifiers
- Multiclass classifier
- Implicit regression
- Latent Variable Architecture
- Analysis of Loss function for EBM
- Architecture and loss function connection: Some loss works with some architecture… Contrastive terms (hinge, log and MCE) helps in complicated architecture.
-
Sufficient condition for Good Loss functions
- conditions on the Energy
Y bar is the minimum energy among the non GT solution.
- Existance of a point where energy for all other non GT solution are smaller than all the points outside the margin. (sufficient condition - without mentioning maths)

- Efficient Interference
Video Activity recognition
informative resource blog post
Approaches
- Pre-deep Learning
- Local features: HOG and Histogram of optical flow
- Trajectory based: Motion boundary histogram
- Feature aggregation: Bag of visual wordd and fisher vectors
- Representing motion: Optical Flow and trajectory stacking
- 3 key steps:
- Local high dimensional feature, combine features, SVM classifiers
- Deep Learning
- Fuse features from multiple frames: Single frame, late fusion, early fusion, slow fusion.
- Single stream network: Single frame, late fusion, early fusion, slow fusion.
- problem with Motion
- Detailed features for the diverse dataset
- Two stream Networks
- Hypothesis: Video = Appearance + Motion
- Special fusion, temporal fusion
- Problems with long range features
- Precomputed optical flow!
- Multi resolution: High res fovea stream and low-res image context stream
- CNN+RNN
- Video as sequence
- Design choice: Modality (RGB and flow), features (CNN or hand crafted), Temporal aggregation (temporal pooling and RNN)
- global discriminator
- 3D convolution
- Spatio temporal features
Contemporary works based on single and two stream papers
- LRCN (long term recurrent Convolutional network for visual recognition and description, Donahue et al 2014)
- Contribution
- Based on RNN (not stream)
- Encoder-decoder for video presentation
- End2End training (but use flow!)
- Contribution
- C3D (Learning spatiotemporal features with convolutional networks (Du tran et al 2014)
- Contributions
- 3D CNN as feature extractors
- Extensive search for best 3D cnn kernel and architecture.
- Using deconvolutional layers for interpretation.
- Factorized Spatio-temporal CN
- Contributions
- Conv3D and attention (Yao et al, 2015)
- Contributions
- Novel 3D CNN-RNN encoder-decoder for spatiotemporal
- Use of attention within CNN-RNN encoder decoder frameworks.
- Not actually action recognition but cnn+lstm ..
- Contributions
- TwoStreamFusion (Feichtenhofer et al. 2016)
- Contribution
- Long range temporal modeling and better long range losses
- Multi-level fuses architecture
- Contribution
- TSN (Temporal segment Networks: Wang et al 2016)
- Contribution
- Long range temporal Modeling
- Bath norm, dropout and pretrained
- Contribution
- ActionVLAD (Girdhar et al 2017)
- Contributions:
- learnable video level aggregation of features (!) - Pooling from different regions
- End2end training
- Contributions:
- HiddenTwoStream (Zhu et al 2017)
- Contributions
- Novel architecture for optical flow input using separate network
- Spatial stream CNN, parallel with MotionNet (for optical flow) and Temporal Stream CNN then late fusion.
- Contributions
- I3D (Carreira et al. 2017)
- Contributions
- 3D based model into two stream architecture
- New dataset
- Extension from C3D (2.)
- Contributions
- T3D (Diba et al. 2017)
- Contributions
- Combining temporal information across variable depth
- Supervised transfer learning
Some Dataset
- Video classification
- UCF101
- Sports-1M
- Youtube 8M
- Atomic action
- Charades
- Atomic Visual Actions
- Moments in Time
- Movie Querying
- M-VAD and MPII-MD
- Large scale movie description Challenges (LSMDC)
Multitask Learning
Motivation:
- Representation sharing among multiple related task or interdependent task
- Multiple objective and act as regularization, provide better generalization (domain specific information in related task. )
Two major ways:
- Hard parameter sharing
- Use shared hidden layers (usually conv) and task specific layers
- Soft parameter sharing
- Uses some distance loss between two layers of two different tasks.
Benefits:
- Implicit Data augmentations
- Attention focusing: In case of noisy data
- Eavesdropping: Learn one task to perform another implicitly
- Bias for Representation
- regularization
Two main line of focus
- MTL in non-neural models
- Block sparse regularization: Apply some constraint on the task parameters. Usually form a matrix (each column- parameters for a task) and apply regularization on the parameters.
-
Learning task relationship: Cluster the columns of the matrix earlier. And apply constraints/ regularization on the parameters.
- Deep Learning
- Deep relational network (Conv layers shared and FC are task specific). IBM, link
- Fully adaptive feature sharing: Evolving layers (good way to initialize). Baidu link
- Cross stitch network: Linear combination of layers from two task and follow on. CMU, link
- Low supervision: Focus on task hierarchies in NLP
- Joint Multi-task model: Built on top of low supervision ideas. link
- Weighting losses with uncertainty: Shared and then orthogonal tasks, weight the loss of multiple tasks together. link
- Tensor factorization, interesting. link
- Sluice Network: combination of different mentioned method earlier. By S. ruder et al.
Auxiliary tasks:
- Related task: Most MTL does it. Work of object detection of R. Girshick.
- Adversarial task!: Unsupervised domain adaptation, link
- Hint: In NLP
- Focusing Attention: Classical by Caruana, 1998.
- Quantization Smoothing
- Predicting input
- Future to present
- Representation learning
Matrix Factorization
As the name suggests, the MF is expressing metrix as multiplication of matrixes. R = PQT
Interesting understanding begins with the multiply of P and Q-transpose. Each row of R, rj is the projection of each row over the rows of the Q []. Means, transforming each row of the P matrix by the row of the Q matrix to new projection on the row of the Q matrix.
The object of MF is straightforward, to reconstruct the original matrix. Sometimes the objective is modified with regularization and weighting loss on reconstruction. As we get two matrix its connected with the embedding concept. So basically P and Q are embedding of row and columns of the original matrix R. link
Way to find P or Q matrix. link
- Gradient descent and update the values.
- Weighted Alternating least squares.