Semi-Supervised
2023
- Mittal, Sudhanshu, Joshua Niemeijer, Jörg P. Schäfer, and Thomas Brox. “Revisiting Deep Active Learning for Semantic Segmentation.” arXiv preprint arXiv:2302.04075 (2023).
- investigates the various types of existing active learning methods for SS under diverse conditions across three dimensions data distribution
- different redundancy levels, integration of semi-supervised learning, and different labeling budgets.
- three underlying factors are decisive for the selection of the best active learning approach
- provide a comprehensive usage guide to obtain the best performance for each case
- propose an exemplary evaluation task for driving scenarios (data redundancy)
- uncertainty measurement: entropy, consistency (dropout, data augmentation), pixel-wise MI,
- TP: Diverse datasets need a single-sample method and redundant datasets need a batch-based method.
- Redundant datasets favour the integration of batchbased active learning and semi-supervised learning
2022
- Tan, C., Gao, Z., Wu, L., Li, S., & Li, S. Z. (2022). Hyperspherical consistency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7244-7255).
- Utilize both contrastive learning and supervised learning
- Proposes an kind of consistency loss for prediction heads (HCR) Hyperspherical consistency regularization.
- Maximize agreement between classification and projection layer for two samples
- BCE setting to maximize their agreement (Eq 3).
- Joint optimization with other losses
- Maximize agreement between classification and projection layer for two samples
- Theory: connection of euclidean distance distribution of the uniformly selected samples in the hypersphere.
- Yang, F., Wu, K., Zhang, S., Jiang, G., Liu, Y., Zheng, F., … & Zeng, L. (2022). Class-aware contrastive semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14421-14430).
- Confirmation Bias of Pseudo-labeling based approaches and worsening by out-of-distribution data
- TP: Joint optimization for three losses (sup, modified pseudo-label and modified CL)
- TP: Class-aware Contrastive Semi-Supervised Learning (CCSSL): a drop-in helper to improve the pseudo-label quality and robustness
- separately handles reliable ID data with class-wise clustering (downstream tasks) and noisy OOD data with instance contrastive
- applying target re-weighting to emphasize clean label learning and simultaneously reduce noisy label learning
- The confidence values between two examples is the weight.
- Threshold based data selection for the re-training
- Framework: Data Augmentation, Encoder, Semi-Supervised Module (Pseudo-label based approach), Class-Aware CL
- Class-aware CL: SCL and reweight.
- Key modification in equation 8: takes multiple positives from the same-class set and high confidency unlabeled data.
- Class-aware CL: SCL and reweight.
- Verma, V., Kawaguchi, K., Lamb, A., Kannala, J., Solin, A., Bengio, Y., & Lopez-Paz, D. (2022). Interpolation consistency training for semi-supervised learning. Neural Networks, 145, 90-106.
- Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for semi-supervised learning
- encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points.
- MixUp for the unlabeled data!!
- Figure 2 summarizes the approaches.
- Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for semi-supervised learning
- Xia, J., Tan, C., Wu, L., Xu, Y., & Li, S. Z. (2022, May). OT Cleaner: Label Correction as Optimal Transport. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 3953-3957). IEEE.
- methods to fix the noisy label problem
- Finds the clean labels and re-configure the labels with low confidences.
- matches the distribution via SK algorithm
- methods to fix the noisy label problem
- Xu, Y., Wei, F., Sun, X., Yang, C., Shen, Y., Dai, B., … & Lin, S. (2022). Cross-model pseudo-labeling for semi-supervised action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2959-2968).
- Swapped prediciton approaches utilizing two network primary (F) and auxiliary (A)
- Very easy setting and loss [equation 6]
- Two different augmentation and swapped prediction using two different network
- Supervised loss for the labeled components
- Unsupervised loss as shown in the figure below for the unlabeled counter parts
- Pseudo-labeling using two different network and swapped prediction.

2021
-
Wei, C., Sohn, K., Mellina, C., Yuille, A., & Yang, F. (2021). Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10857-10866).
- CReST iteratively retrains a baseline SSL model with a labeled set expanded by adding pseudolabeled samples from an unlabeled set, where pseudolabeled samples from minority classes are selected more frequently according to an estimated class distribution.
- propose a progressive distribution alignment to adaptively adjust the rebalancing strength dubbed CReST+.
- Pseudo-label, balance the samples by selecting more the tail pseudo-labels.
- Ratio by equation 1
- exploit the high precision of minority classes to alleviate their recall degradation
-
Englesson, E., & Azizpour, H. (2021). Consistency Regularization Can Improve Robustness to Label Noise. arXiv preprint arXiv:2110.01242.
- consistency loss propose in Equation 1
- Weighted sum of
- JS divergence between two prediction of two augmentation of same image
- JS divergence of true prediction and average prediction for the augmented images.
- Weighted sum of
- consistency loss propose in Equation 1
- Tai, K. S., Bailis, P. D., & Valiant, G. (2021, July). Sinkhorn label allocation: Semi-supervised classification via annealed self-training. In International Conference on Machine Learning (pp. 10065-10075). PMLR.
- Self-training: learner’s own predictions on unlabeled data are used as supervision during training (iterative bootstrapping)
- Provides a formulation to facilitate a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class
- Related work: FixMatch (th for selecting pseudo-label)
- TP: Sinkhorn label allocation (SLA).
- Minimal computational overhead in the inner loop for label assignment.

- Label annealing strategies where the labeled set is slowly grown over time
- Provide fast approximation: the typical solution we see. (algorithm 1 and 2)
-
Tai, K. S., Bailis, P. D., & Valiant, G. (2021, July). Sinkhorn label allocation: Semi-supervised classification via annealed self-training. In International Conference on Machine Learning (pp. 10065-10075). PMLR.
-
Assran, Mahmoud, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Armand Joulin, Nicolas Ballas, and Michael Rabbat. “Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments with Support Samples.” arXiv preprint arXiv:2104.13963 (2021).
-
PAWS (Predicting view assignments with support samples)
-
Minimize a consistency loss!! different view to get same pseudo labels
-
RQ: can we leverage the labeled data throughout training while also building on advances in self-supervised learning?
-
How it is different than augmentation (may be using some unlabeled co unterparts)
-
How the heck the distance between view representation and labeled representation is used to provide weights over class labels (why is makes sense, and what benefits it offers??)
-
Related works: Semi-supervised learning, few shot learning, and self-supervised learning
-
Interesting ways to stop the collapse [sharpening functions] (section 3.2)
-
2020
-
Yang, Y., & Xu, Z. (2020). Rethinking the value of labels for improving class-imbalanced learning. Advances in neural information processing systems, 33, 19290-19301.
- Idea to SSL pretraining by abandoning label initially and later use them. (semi-sup and self-sup training helps the tailed classes. )
-
Wang, Y., Guo, J., Song, S., & Huang, G. (2020). Meta-semi: A meta-learning approach for semi-supervised learning. arXiv preprint arXiv:2007.02394.
- section 2: methods contain the gist.
-
Yu, Q., Ikami, D., Irie, G., & Aizawa, K. (2020). Multi-task curriculum framework for open-set semi-supervised learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16 (pp. 438-454). Springer International Publishing.
- Assumption: Labeled data and unlabeled data, some common classes in unlabeled data and rest is from novel classes (GCD setting)
- Instead of training an OOD detector and SSL separately, TP propose a multitask curriculum learning framework
- OOD detection: estimate the probability of the sample belonging to OOD
- a joint optimization framework, which updates the network parameters and the OOD score alternately
- to improve performance on the classification (ID) data, TP select ID samples in unlabeled data having small OOD scores, and retrain training the deep neural networks to classify ID samples in a semi-supervised manner.
- Key assumption: that a network trained with a high learning rate is less likely to overfit to noisy labels
- train OOD detection and hope that the noisy samples will be filtered automatically.
- As simple as heck: Select only top confidence sample from the unlabeled data for retraining the labeled classifier. (curriculum)
- Algorithm 1 and 2
-
Guo, L. Z., Zhang, Z. Y., Jiang, Y., Li, Y. F., & Zhou, Z. H. (2020, November). Safe deep semi-supervised learning for unseen-class unlabeled data. In International Conference on Machine Learning (pp. 3897-3906). PMLR.
- unlabeled data contains some classes not seen in the labeled data. - TP: proposes a simple and effective safe deep SSL method to alleviate the harm caused by it
- Kinda NCD formulation
- Proposes instance to weight weighting funciton!! multiplied with consistency regularization.
- What and how and why, is that scalable?? how to do it for image?
- Vague one, safely ignore the paper!
- Safe (!)
- Bi-level optimization problem
- supervised and consistency loss regularization
-
Arazo, E., Ortego, D., Albert, P., O’Connor, N. E., & McGuinness, K. (2020, July). Pseudo-labeling and confirmation bias in deep semi-supervised learning. In 2020 International Joint Conference on Neural Networks (IJCNN) (pp. 1-8). IEEE.
- Soft pseudo-label (with correct setting can outperform consistency regularization: Noise Accumulation!)
- TP: Tries to eliminate the CB without Consistency regularization
- Drop-out and data augmentation can eliminate CB
- Naive pseudo-label overfits to incorrect one due to confirmation bias (how to measure CB).
- Mixup and setting a minimum number of labeled samples per mini-batch are effective regularization techniques reduces confirmation bias
- They utilize external KL matching.
- label smoothing alleviate the overconfidence problem.
- Mixup data augmentation alone is insufficient to deal with CB when few labeled examples are provided
- TP: Tries to eliminate the CB without Consistency regularization
- Sum of three losses: Entropy loss (enforce single decision), distribution (removing collapse) matching and mixup (counter CB) loss
- Relative weight between them matters
- Soft pseudo-label (with correct setting can outperform consistency regularization: Noise Accumulation!)
-
Van Gansbeke, W., Vandenhende, S., Georgoulis, S., Proesmans, M., & Van Gool, L. (2020, August). Scan: Learning to classify images without labels. In European conference on computer vision (pp. 268-285). Springer, Cham.
- advocate a two-step approach where feature learning and clustering are decoupled
- SSL and SSL prior for learnable clustering.
- remove the ability for cluster learning to depend on low-level features (current end-to-end learning approaches.)
-
Representation learning leads to imbalanced clusters and there is no guarantee that the learned clusters aligns with the semantic classes
- end-to-end learning pipelines combine feature learning with clustering.
- leverage the architecture of CNNs as a prior to cluster images (DEC)
- learn a clustering function by maximizing the mutual information between an image and its augmentations
- sensitive to initialization or prone to degenerate solutions
- since the cluster learning depends on the network initialization, they are likely to latch onto low-level features
-
- leaverage advantage of both representation learning and end-end learning
- encourage invariance w.r.t. the nearest neighbors, and not solely w.r.t. augmentations
- end-to-end learning pipelines combine feature learning with clustering.
- Methods summary: 1. Representation learning for semantic clustering,
- Contrastive learning (loss function 2) with entropy regularizer.
- Fine-tuning through self-labeling
- Contrastive learning (loss function 2) with entropy regularizer.
- advocate a two-step approach where feature learning and clustering are decoupled
- Sohn, Kihyuk, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. “Fixmatch: Simplifying semi-supervised learning with consistency and confidence.” arXiv preprint arXiv:2001.07685 (2020).
- FixMatch: a significant simplification of existing SSL methods
- Generates pseudo-labels using the model’s predictions on weakly augmented unlabeled images
- Retained if confidence is high.
- Utilize the retained label to train strongly-augmented (via Cutout, CTAugment, RandAugment) version of same image.
- Consistency Regularization and Pseudo-labeling
- Generates pseudo-labels using the model’s predictions on weakly augmented unlabeled images
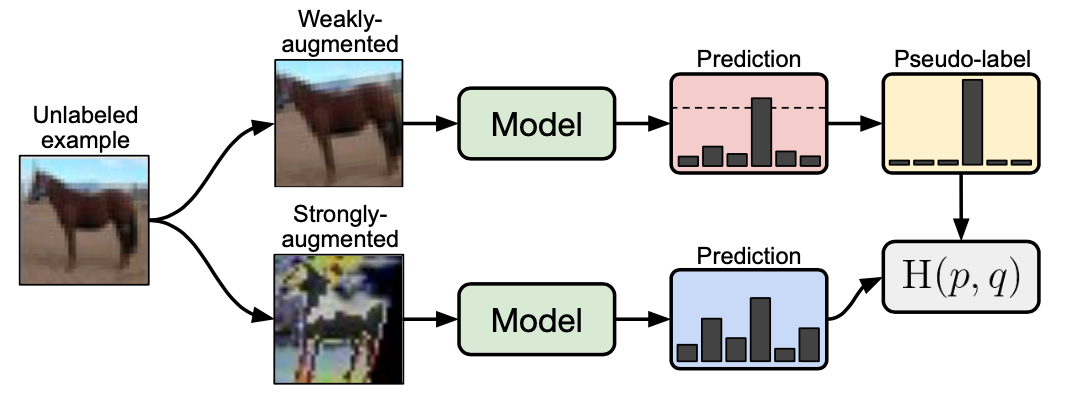
- Simple setup- retraining with the good predictions with consistency losses.
- FixMatch: a significant simplification of existing SSL methods
-
Pham, Hieu, Zihang Dai, Qizhe Xie, Minh-Thang Luong, and Quoc V. Le. “Meta pseudo labels.” arXiv preprint arXiv:2003.10580 (2020).
-
semi supervised learning (should cover the labeled and unlabeled at the beginning)
- teacher network - to generate - pseudo labels [extension of pseudo label work]
- TP: Contrary to the Pseudo label work: The teacher network is not fixed and constantly adapting [claim: teacher learn better pseudo labels]
- Connected to Pseudo Labels/self-training (semi-supervised)
- Issues with the confirmation bias of pseudo label? does TP solve this??
- correct the confirmation bias using a systematic mechanism!!! (how pseudo-label affect the student network) [figure 1]
- Parallel training [student’s learning feedback goes to teacher]!! (dynamic target!)
- assumption: Pseudo label of teacher can be adjusted
- However, extremely complication optimization as it requires to unroll everything!
- Sampling hard pseudo labels (modified version of REINFORCE algorithm!)
- Nice experiment section: Dataset, network, and baseline
- teacher network - to generate - pseudo labels [extension of pseudo label work]
-
-
Li, Junnan, Richard Socher, and Steven CH Hoi. “Dividemix: Learning with noisy labels as semi-supervised learning.” arXiv preprint arXiv:2002.07394 (2020).
-
TP: divide the training data into a labeled set with clean samples and an unlabeled set with noisy samples (co-training two networks), and trains the model on both data (?). Improved MixMatch
-
TP: Two diverged network (avoid confirmation bias of self-training) use each others data! GMM to find labeled and unlabeled (too much noisy) data. Ensemble for the unlabeled.
-
Related strategy: MixUp (noisy sample contribute less to loss!), co-teaching? Loss correction approach? Semi-supervised learning, MixMatch (unifies SSL and LNL [consistency regularization, entropy minimization, and MixUp])
-
Application: Data with noisy label (social media image with tag!) may result poor generalization (as may overfit)!
-
Hypothesis: DNNs tend to learn simple patterns first before fitting label noise Therefore, many methods treat samples with small loss as clean ones (discards the sample labels that are highly likely to be noisy! and leverages them as unlabeled data)
-
Algorithm is nice to work with
-
-
Xie, Qizhe, Minh-Thang Luong, Eduard Hovy, and Quoc V. Le. “Self-training with noisy student improves imagenet classification.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687-10698. 2020.
-
Interesting way to improve the Classifier
-
(labeled data) -> Build classifier (T) -> (predict unlabeled data) -> Train Student using both labeled + model predicted unlabeled data. Repeat.. [algo 1]
-
Introduce noise for both T and S.
- Data noise, model noise (dropout)
-
2019
- Berthelot, D., Carlini, N., Cubuk, E. D., Kurakin, A., Sohn, K., Zhang, H., & Raffel, C. (2019). Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv preprint arXiv:1911.09785.
- improve mixmatch by two contributions
- Distribution alignment encourages the marginal distribution of predictions on unlabeled data to be close to the marginal distribution of groundtruth labels.
- Augmentation anchoring feeds multiple strongly augmented versions of an input into the model and encourages each output to be close to the prediction for a weakly-augmented version of the same input (AutoAugment)
- improve mixmatch by two contributions
- Sarfraz, S., Sharma, V., & Stiefelhagen, R. (2019). Efficient parameter-free clustering using first neighbor relations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8934-8943).
- FINCH methods: equation 1 is the key
- Cluster by nearest 1 neighborhood
- Hierarchical clustering: first the 1-nearest neighbor then merge them to form new points and then again clustering (easy-pesy)
- Euclidean distance based clustering.
- FINCH methods: equation 1 is the key
- Zhai, Xiaohua, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. “S4l: Self-supervised semi-supervised learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1476-1485. 2019.
- Pretext task of rotation angle prediction!!
- Rotation, invariant across augmentation
- Baseline: vitrural adversarial training [inject noise with the original images], EntMin
- EntMin is bad: because the model can easily become extremely confident by increasing the weights of the last layer
- Pretext task of rotation angle prediction!!
- Gupta, Divam, Ramachandran Ramjee, Nipun Kwatra, and Muthian Sivathanu. “Unsupervised Clustering using Pseudo-semi-supervised Learning.” In International Conference on Learning Representations. 2019.
-
Berthelot, David, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. “Mixmatch: A holistic approach to semi-supervised learning.” arXiv preprint arXiv:1905.02249 (2019).
-
TP: guesses low-entropy labels for data-augmented unlabeled examples and mixes labeled and unlabeled data using MixUp (Algorithm 1)
-
Related works: Consistency Regularization, Entropy Minimization
-
2018 and earlier
-
Qiao, S., Shen, W., Zhang, Z., Wang, B., & Yuille, A. (2018). Deep co-training for semi-supervised image recognition. In Proceedings of the european conference on computer vision (eccv) (pp. 135-152).
- Joint optimization of three losses in semi-supervised setting
- Utilize two different network for co-training (DCT)
- Cross entropy loss for labeled data
- JS divergence minimization for two views prediction from of two network
- Swapped prediction using adversarial examples utilizing two different network.
-
Tanaka, D., Ikami, D., Yamasaki, T., & Aizawa, K. (2018). Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5552-5560)
- Alternative optimization: generate pseudo-label and update network, repeat…
- Suggests high learning rate
- Issues with CB
- reinforces the findings of Arpit et al. [1] that suggest that DNNs first learns simple patterns and subsequently memorize noisy data
- Alternative optimization: generate pseudo-label and update network, repeat…
-
Chang, J., Wang, L., Meng, G., Xiang, S., & Pan, C. (2017). Deep adaptive image clustering. In Proceedings of the IEEE international conference on computer vision (pp. 5879-5887).
- adopts a binary pairwise classification framework for image clustering [DAC]
- learned label features tend to be one-hot vectors (constraint into DAC)
- single-stage named Adaptive Learning algorithm to streamline the learning procedure for image clustering
- dynamically learn the threshold for pairwise label selection [section 3.3]
- single-stage named Adaptive Learning algorithm to streamline the learning procedure for image clustering
- learned label features tend to be one-hot vectors (constraint into DAC)
- summary: chose two adaptive th for pairwise labels. iterative fix the network and th to reduce number of unlabeled images.
- metrics: Adjusted Rand Index (ARI), Normalized Mutual Information (NMI) and clustering Accuracy (ACC).
- adopts a binary pairwise classification framework for image clustering [DAC]
-
Rasmus, A., Berglund, M., Honkala, M., Valpola, H., & Raiko, T. (2015). Semi-supervised learning with ladder networks. Advances in neural information processing systems, 28.
- trained to simultaneously minimize the sum of sup and unsup cost functions by backpropagation, avoiding the need for layer-wise pre-training
- builds on top of the Ladder network [bit out of my interest for now]
- trained to simultaneously minimize the sum of sup and unsup cost functions by backpropagation, avoiding the need for layer-wise pre-training
- Blum, Avrim, and Tom Mitchell. “Combining labeled and unlabeled data with co-training.” In Proceedings of the eleventh annual conference on Computational learning theory, pp. 92-100. 1998.
- Early semi-supervised learning (mathematical framework with graph setting)
- Web page (and its augmentation)
- Early semi-supervised learning (mathematical framework with graph setting)
-
Grandvalet, Yves, and Yoshua Bengio. “Semi-supervised learning by entropy minimization.” In CAP, pp. 281-296. 2005.
- Semi-supervised learning by minimum entropy regularization!
- result compared with mixture models ! (entropy methods are better)
- Connected to cluster assumption and manifold learning
- Motivation behind supervised training for unlabeled data
- Exhaustive generative search
- More parameters to be estimation that leads to more uncertainty
- Exhaustive generative search
- Semi-supervised learning by minimum entropy regularization!
-
Tarvainen, Antti, and Harri Valpola. “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.” arXiv preprint arXiv:1703.01780 (2017).
- Improves Temporal Ensemble by average model weights (usual practice now!) instead of label prediction (WOW!)
- Temporal and Pi model suffers from confirmation bias (requires better target) as self-teacher!
-
Two ways to improve: chose careful perturbation or chose careful teacher model
-
Result: Mean teacher is better! faster converge and higher accuracy
-
Importance of good architecture (TP: Residual networks):
- TP: how to form better teacher model from students.
- TP: Large batch, large dataset, on-line learning.
- Improves Temporal Ensemble by average model weights (usual practice now!) instead of label prediction (WOW!)
- Laine, Samuli, and Timo Aila. “Temporal ensembling for semi-supervised learning.” arXiv preprint arXiv:1610.02242 (2016).
- A form of consistency regularization.
- Self-ensemble (Exponential moving average), consensus prediction of unknown labels!!
- Ensemble Utilization of outputs of different network-in-training (same network: different epochs, different regularization!!, and input augmentations) to predict unlabeled data.
- The predicted unlabeled data can be used to train another network
- One point to put a distinction between semi-supervised learning and representation learning-fine tuning. In Semi-sup the methods uses the label from the beginning.
- Importance on the Data Augmentation and Regularization.
- TP: Two self-ensemble methods: pi-model and temporal ensemble (Figure 1) based on consistency losses.
- Pi Model: Forces the embedding to be together (Contrastive parts is in the softmax portion; prevents collapse)
- Pi vs Temporal model:
- (Benefit of temporal) Temporal model is faster.In case of temporal, training target is less noisy.
- (Downside of temporal) Store auxiliary data! Memory mapped file.
- Pi vs Temporal model:
- Self-ensemble (Exponential moving average), consensus prediction of unknown labels!!
- A form of consistency regularization.
-
Miyato, Takeru, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. “Virtual adversarial training: a regularization method for supervised and semi-supervised learning.” IEEE transactions on pattern analysis and machine intelligence 41, no. 8 (2018): 1979-1993.
- Find the distortion in allowed range for a given input to maximize the loss. (gradient ascent for the input spaces)
- Network trains to minimize the loss on the distorted input. (Gradient descent in the network parameter spaces)
- Find the distortion in allowed range for a given input to maximize the loss. (gradient ascent for the input spaces)