Open-Set Recognition problem (OSR)
Here, we will review papers regarding novel class detection (NCD), Out of distribution detection (OOD) mostly in computer vision.
- L for labeled
- cl for contrastive learning
- u for unlabeled or unknown
- gt - ground truth
Out-of-Distribution (OOD)
2023
- Ulmer, D., Hardmeier, C., & Frellsen, J. (2023). Prior and posterior networks: A survey on evidential deep learning methods for uncertainty estimation. Transactions on Machine Learning Research.
- EDL: aim to admit “what they don’t know”, and fall back onto a prior belief
- Rastegar, S., Doughty, H., & Snoek, C. G. (2023). Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery. arXiv preprint arXiv:2310.19776.
- conceptualize a category through the lens of optimization, viewing it as an optimal solution to a well-defined problem!!
- efficient and self-supervised method capable of discovering previously unknown categories at test time.
- assignment of minimum length category codes to individual data instances, which encapsulates the implicit category hierarchy prevalent in real-world datasets.
- Enhanced control over category granularity, thereby equipping our model to handle fine-grained categories adeptly
- reframing the concept of a category as the solution to an optimization problem. We argue that categories serve to describe input data and that there is not a singular correct category but a sequence of descriptions that span different levels of abstraction.
- Why category happens:
- One theory is categorization was a survival necessity that the human brain developed to retrieve data as fast and as accurately as possible
- a trade-off between retrieval speed and accuracy of prediction
- frequent categories can be recognized in a shorter time, with more time needed to recognize fine-grained nested subcategories
- propose categorization as an optimization problem with analogous goals to the human brain. We hypothesize that we can do the category assignment to encode objects hierarchically to retrieve them as accurately and quickly as possible
- Joint Optimization rules
- Gawlikowski, J., Tassi, C. R. N., Ali, M., Lee, J., Humt, M., Feng, J., … & Zhu, X. X. (2023). A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 1-77.
- basic NN do not deliver certainty estimates or suffer from over- or under-confidence, i.e. are badly calibrated.
- gives a comprehensive overview of uncertainty estimation in NN, recent advances in the field, highlights current challenges, and identifies potential research opportunities
- modeling of these uncertainties based on deterministic neural networks, Bayesian neural networks (BNNs), ensemble of neural networks, and test-time data augmentation approaches
- discuss different measures of uncertainty, approaches for calibrating neural networks, and give an overview of existing baselines and available implementations.
- Source of Uncertainty in DL
- the data acquisition
- Factor I: Variability in real world situations (distribution shift)
- Factor II: Error and noise in measurement systems (aleatoric uncertainty)
- Deep neural network design and training
- Factor III: Errors in the model structure
- Factor IV: Errors in the training procedure
- Inference: Factor V: Errors caused by Unknown data
- Predictive Uncertainty Model
- Uncertainty Classification: In-domain Uncertainty, Domain Shift uncertainty, and Out-of-domain uncertainty.
- the data acquisition
- Uncertainty using single deterministic methods
- Internal Uncertainty: prior network, evidential DL, interval NN.
- External Uncertainty
- Bayesian NN to measure Uncertainty: Sampling methods, variational inferences, Laplace approximation.
- Ensemble Methods:
- Measuring Uncertainty:
- In classification:
- data uncertainty -maximal prob, entropy
- Model uncertainty: MI and KL between mean prediction and single prediction
- Distributional Uncertainty:
- Regression tasks and Semantic segmentation tasks.
- In classification:
- Calibration: Regularization methods, post-processing methods, NN uncertainty estimation.
- Pu, N., Zhong, Z., Ji, X., & Sebe, N. (2023). Federated Generalized Category Discovery. arXiv preprint arXiv:2305.14107.
- Explored GCD in federated setting: data class variation across clients (not shareable)
- Fed-GCD: train a generic GCD model by client collaboration under the privacy-protected constraint
- propose a novel Associated Gaussian Contrastive Learning (AGCL) framework based on learnable GMMs,
- consists of a Client Semantics Association (CSA) and a global-local GMM Contrastive Learning (GCL)??
- On the server, CSA aggregates the heterogeneous categories of local-client GMMs to generate a global GMM containing more comprehensive category knowledge: global GCL encourages the model to produce more discriminative representatio
- On each client, GCL builds class-level CL with both local and global GMMs. local GCL learns robust representation with limited local data.
- AGCL unifies the discriminative representation learning on the limited local data & heterogeneous category aggregation on the central server
- Benchmark: Fed Avg-based baseline.
- Ming, Y., Sun, Y., Dia, O., & Li, Y. (2022). How to Exploit Hyperspherical Embeddings for Out-of-Distribution Detection?. arXiv preprint arXiv:2203.04450.
- prior methods applies CL that suffice for classifying ID samples (not optimally designed when test inputs contain OOD samples)
- CIDER, a novel representation learning framework that exploits hyperspherical embeddings for OOD detection
- jointly optimizes two losses to promote strong ID-OOD separability
- dispersion loss: promotes large angular distances among different class prototypes
- compactness loss: encourages samples to be close to their class prototypes.
- related works: Distance based approaches: SSD+, KNN+
- motivated by the desirable properties of hyperspherical embeddings: naturally modeled by the von Mises-Fisher (vMF) distribution.
- Straight forward loss function: Equation 1 -7
- Troisemaine, C., Lemaire, V., Gosselin, S., Reiffers-Masson, A., Flocon-Cholet, J., & Vaton, S. (2023). Novel Class Discovery: an Introduction and Key Concepts. arXiv preprint arXiv:2302.12028.
- Two Stage Methods:
- Learned similarity based: CCN and MCL (BCE Loss)
- Latent-space-based: DTC, Meta discovery with MAML
- One-stage methods
- AutoNovel, Class discovery kernel network with expansion, OpenMIX, NCL
- Related works: Unsupervised Clustering, Semi-supervised learning, transfer learning, Open world learning, Anomaly detection, Novelty detection, open set recognition, out-of-distribution detection, outlier detection.
- Two Stage Methods:
- Wang, L., Zhang, X., Su, H., & Zhu, J. (2023). A Comprehensive Survey of Continual Learning: Theory, Method and Application. arXiv preprint arXiv:2302.00487.

- growing and widespread interest in this direction demonstrates its realistic significance as well as complexity.
- TP: basic settings, theoretical foundations, representative methods, and practical applications
- trade-off between learning plasticity and memory stability
- Five major groups
- adding regularization terms with reference to the old model (regularization-based approach)
- approximating and recovering the old data distributions (replay-based approach);
- explicitly manipulating the optimization programs (optimization-based approach);
- learning robust and well-generalized representations (representation-based approach);
- constructing task-adaptive parameters with a properly-designed architecture (architecture-based approach)
- these methods are closely connected, e.g., regularization and replay ultimately act to rectify the gradient directions in optimization
- highly synergistic, e.g., the efficacy of replay can be facilitated by distilling knowledge from the old model.
- types
- Instance-Incremental Learning (IIL): All training samples belong to the same task and arrive in batches.
- Domain-Incremental Learning (DIL): Tasks have the same data label space but different input distributions. Task identities are not required.
- Task-Incremental Learning (TIL): Tasks have disjoint data label spaces. Task identities are provided in both training and testing.
- Class-Incremental Learning (CIL): Tasks have disjoint data label spaces. Task identities are only provided in training.
- Task-Free Continual Learning (TFCL): Tasks have disjoint data label spaces. Task identities are not provided in either training or testing
- Online Continual Learning (OCL): Tasks have disjoint data label spaces. Training samples for different tasks arrive as an one-pass data stream.
- Blurred Boundary Continual Learning (BBCL): Task boundaries are blurred, characterized by distinct but overlapping data label spaces.
- Continual Pre-training (CPT): Pre-training data arrives in sequence. The goal is to improve the performance of learning a downstream task.
- Further related to many other tasks like NCD, ZSL, FSL, Noisy labels, SSL, hierarchical granularity learning, Long-tailed distrib. etc.
- Evaluation metrics
- Overall Performance: Average accuracy (AA) and average incremental accuracy (AIA)
- Memory stability: Forgetting measurement (FM) and backward transfer (BWT)
- Learning plasticity: Intransience Measure (IM) and Forward transfer (FWT)
2022
- Jung, M. C., Zhao, H., Dipnall, J., Gabbe, B., & Du, L. (2022). Uncertainty estimation for multi-view data: The power of seeing the whole picture. Advances in Neural Information Processing Systems, 35, 6517-6530.
- Dong, J., Wang, L., Fang, Z., Sun, G., Xu, S., Wang, X., & Zhu, Q. (2022). Federated class-incremental learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10164-10173).
- RG: Local and global forgetting under the incremental learning for federated setting.
- Proposes a novel Global-Local Forgetting Compensation (GLFC) model, to learn a global class-incremental model for alleviating the catastrophic forgetting from both local and global perspectives
- address local forgetting at local clients (caused by class imbalance at the local clients) by designing
- a class-aware gradient compensation loss and [equation 4: gradient scaling]
- a class-semantic relation distillation loss [equation 5: elasticity with earlier performance]
- To tackle the global forgetting (by the non-i.i.d class imbalance across clients) TP propose a proxy server that selects the best old global model to assist the local relation distillation.
- A bit complex part
- a prototype gradient-based communication mechanism is developed to protect the privacy
- Zhang, L., Qi, L., Yang, X., Qiao, H., Yang, M. H., & Liu, Z. (2022). Automatically Discovering Novel Visual Categories with Self-supervised Prototype Learning. arXiv preprint arXiv:2208.00979.
- leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue with missing annotations of novel classes
- propose a novel adaptive prototype learning method consisting of two main stages:
- prototypical representation learning: obtain a robust feature extractor for all images (instance and category discrimination): boosted by self-supervised learning and adaptive prototypes. [DINO+Online prototype learning (OPL)]
- OPL: maintain adaptive prototypes for novel categories, allowing online updates and then assigning class-level pseudo labels on-the-fly
- prototypical self-training: utilize the prototypes again to rectify offline pseudo labels and train parametric classifier for category clustering
- Pseudo labelling, prototypical pseudo label rectification, and joint optimization
- prototypical representation learning: obtain a robust feature extractor for all images (instance and category discrimination): boosted by self-supervised learning and adaptive prototypes. [DINO+Online prototype learning (OPL)]
- present a new data augmentation strategy named restricted rotation for multi-view construction of symbolic data (e.g., shape and character).
- Zang, Z., Shang, L., Yang, S., Sun, B., & Li, S. Z. (2022). Boosting Novel Category Discovery Over Domains with Soft Contrastive Learning and All-in-One Classifier. arXiv preprint arXiv:2211.11262.
- propose Soft-contrastive All-in-one Network (SAN) for ODA and UNDA tasks
- SAN includes a novel data-augmentation-based CL loss and a more human-intuitive classifier to improve the new class discovery capability.
- soft contrastive learning (SCL) loss weaken the adverse effects of the data-augmentation label noise problem (amplified in domain transfer)
- addresses the view-noise problem by incorporating the idea of self-distillation
- All-in-One (AIO) classifier overcomes the overconfidence problem of the current closed-set classifier and open-set classifier in a more human-intuitive way.
- UNDA (universal) account for the uncertainty about the category shift.
- The assumption is that the label distributions of labeled and unlabeled data can differ, but we do not know the difference in advance.
- Problem 1: The view-noise problem in data augmentation affects the pre-training of the backbone
- Problem 2: Overconfident classifiers (closed-set classifier and open-set classifier) affect novel category recognition performance
- An all-in-one (AIO) classifier is designed to replace the closed-set classifier and open-set classifier.
- Assumption: identifying a sample as belonging to a novel category requires determining that it does not belong to all known classes.
- Figure 1(b) - b4 summarizes the idea.
- Math heavy paper!!
- propose Soft-contrastive All-in-one Network (SAN) for ODA and UNDA tasks
-
Caccia, Lucas, and Joelle Pineau. “Special: Self-supervised pretraining for continual learning.” Continual Semi-Supervised Learning: First International Workshop, CSSL 2021, Virtual Event, August 19–20, 2021, Revised Selected Papers. Cham: Springer International Publishing, 2022.
- for unsupervised pretraining of representations amenable to continual learning
- efficiently reuses past computations, reducing its computational and memory footprint??? (How)
- Experimenation with FSL objectives.
- Related works: Self-supervised learning, continual learning, meta-learning (meta-continual learning!!, Unsup. meta learning)
-
Zhang, S., Khan, S., Shen, Z., Naseer, M., Chen, G., & Khan, F. (2022). PromptCAL: Contrastive Affinity Learning via Auxiliary Prompts for Generalized Novel Category Discovery. arXiv preprint arXiv:2212.05590.
- a two-stage Contrastive Affinity Learning method with auxiliary visual Prompt (PromptCAL)
- Discovers reliable pairwise sample affinities to learn better semantic clustering of both known and novel classes for the class token and visual prompt
- propose a discriminative prompt regularization loss: reinforce semantic discriminativeness of prompt-adapted pre-trained ViT for refined affinity relationship
- propose contrastive affinity learning to calibrate semantic representations based on iterative semi-supervised affinity graph generation method for semantically-enhanced supervision
- a two-stage Contrastive Affinity Learning method with auxiliary visual Prompt (PromptCAL)
-
Yu, L., Twardowski, B., Liu, X., Herranz, L., Wang, K., Cheng, Y., … & Weijer, J. V. D. (2020). Semantic drift compensation for class-incremental learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6982-6991).
- Key Idea: Embedding networks have the advantage that new classes can be naturally included into the network without adding new weights
- Estimate drifts and compensate for them to avoid indirect forgetting.
- propose a new method to estimate the drift, called semantic drift, of features and compensate for it without the need of any exemplars!!
- show that embedding networks suffer significantly less from catastrophic forgetting than classification networks.
- Proposes Semantic Drift Compensation (SDC)
- Section 4.1: nice set of equation 8-13
- measures semantic drift by proxy task
- experiments on fine-grained datasets, CIFAR100 and ImageNetSubset.
- previous works all study continual learning in classification networks : TP works with embedding network (prototype: Embedding mean)
- Key Idea: Embedding networks have the advantage that new classes can be naturally included into the network without adding new weights
-
Yu, L., Weng, Z., Wang, Y., & Zhu, Y. (2022). Multi-Teacher Knowledge Distillation for Incremental Implicitly-Refined Classification. arXiv preprint arXiv:2202.11384.
- TP: Solution Incremental Implicitly-Refined Classification (IIRC)
- Superclass to subclasses
- Method overview ( why & how?) Oh really??
- preserve the subclass knowledge by using the last model (!) as a general teacher to distill the previous knowledge for the student model.
- preserve the superclass knowledge by using the initial model (!) as a superclass teacher to distill the superclass knowledge as the initial model contains abundant superclass knowledge.
- KD from two teacher models could result in the student model making some redundant predictions: propose a post-processing mechanism, called as Top-k prediction restriction to reduce the redundant predictions.
- Dataset: IIRC-Imagenet120, IIRC-Cifar100
- Combination of three losses: Figure 3
- well the final layer is softmax?? How does it make sense????
- Instead of should have been in the representation layer
- Increasing neuron numbers in the representation layer.
- TP: Solution Incremental Implicitly-Refined Classification (IIRC)
- Fang, Z., Li, Y., Lu, J., Dong, J., Han, B., & Liu, F. (2022). Is Out-of-Distribution Detection Learnable?. arXiv preprint arXiv:2210.14707.
- investigate the probably approximately correct (PAC) learning theory of OOD detection
- find a necessary condition for the learnability of OOD detection.
- prove several impossibility theorems for the learnability of OOD detection under some scenarios
- impossibility theorems are frustrating, tp finds some conditions of these impossibility theorems may not hold in some practical scenarios.
- give several necessary and sufficient conditions to characterize the learnability of OOD detection
- offer theoretical supports for several representative OOD detection works based on our OOD theory
- Constraints on domain space and hypothesis space.
- discover that OOD detection is learnable only if the domain space and the hypothesis space satisfy some special condition
- RQ: Given hypothesis spaces and several representative domain spaces, what are the conditions to ensure the learnability of OOD detection? If possible, we hope that these conditions are necessary and sufficient in some scenarios.
- overlap between ID and OOD data may result in that the necessary condition does not hold
- TP covers: all OOD data be allocated to one big OOD class (unknown class k=1)
- Unknown class k>1, falls in unsupervised clustering.
- TP: Assumes no earlier available of OOD data, contrast with GCD, unsup cluster setting.
- investigate the probably approximately correct (PAC) learning theory of OOD detection
- Deng, Jieren, Jianhua Hu, Haojian Zhang, and Yunkuan Wang. “Incremental Prototype Prompt-tuning with Pre-trained Representation for Class Incremental Learning.” arXiv preprint arXiv:2204.03410 (2022).
- parameter-additional-tuning (PAT): only changes very few parameters to learn new visual concepts
- e.g. linear probing, prompt tuning, and adapter
- PAT based CIL avoids fighting against forgetting by replaying or distilling like most of the existing methods.
- PAT: aims to alias the pre-training and downstream tasks by adjusting the additional task-specific parameters (fix the the pre-trained model) - Gap: PAT-based CIL still faces serious semantic drift (high-level forgetting caused by classifier learning bias at different learning phases)
- propose Incremental Prototype Tuning (IPT) (tunes category prototypes for classification and learning prototypes to counter semantic drift)
- Stores several prototypes (instead of the samples)
- Propose a new metric called category drift rate (CDR) to measure semantic drift??
- new maximum similarity loss (MSL) is designed to maintain the diversity of example prototypes?? - Experiment: ViT and PAT methods. Dataset: Cifar, ImageNet - Motivation from the L2P (difference?)
- IPT chooses to learn category prototypes as the input for the classifier and servers a plug-in module for all PAT methods - Related works: Class incremental learning (one of the three IL task IL, domain IL, and class IL)
- CIL: replay-based, regularization-based, and parameter-isolation-based
- PAT: adapter-based (injects small-scale NN modules (adapters) connected to the transformer layer), and prompt-based (L2P) - Semantic drift is a higher-level forgetting problem, it is less obvious to see the semantic drift when the representation model is not frozen because it is mixed with a lower level of forgetting (representation forgetting).???? - Kinda Vague approach: Better read L2P that this.
- Du, X., Gozum, G., Ming, Y., & Li, Y. (2022). Siren: Shaping representations for detecting out-of-distribution objects. In Advances in Neural Information Processing Systems.
- distance-based OOD detection methods remain largely unexplored in object-level OOD detection
- proposing a distance based framework for detecting OOD objects (model-agnostic representation space both CNN and Tx)
- TP explore test-time OOD detection by leveraging the optimized embeddings in a parametric or non-parametric way
- a trainable loss function to shape the representations into a mixture of von Mises-Fisher (vMF) distributions on the unit hypersphere!!
- ShapIng the RepresENtations into a desired parametric form: model the representations by the von Mises-Fisher (vMF) distribution (classic probability distribution in directional statistics for hyperspherical data with the unit norm) - vMF avoids estimating large covariance matrices for high-dimensional data (that is costly and unstable in Gaussian case)
- encourages the normalized embedding to be aligned with its class prototype and shapes the overall representations into compact class clusters
- whats the motivation and hypothesis.
- a test-time OOD detection score leveraging the learned vMF distributions in a parametric or non-parametric way
- proposing a distance based framework for detecting OOD objects (model-agnostic representation space both CNN and Tx)
- Benchmark: AUROC metrics
- Taken the idea of distance-based OOD from image classification and applied to object detection.
- Experimented on both transformer-based and CNN-based models.
- Joint optimization for multiple targets (figure 2)
- Similar to other prototypical approaches 11. Azizmalayeri, M., Moakhar, A. S., Zarei, A., Zohrabi, R., Manzuri, M. T., & Rohban, M. H. (2022). Your Out-of-Distribution Detection Method is Not Robust!. arXiv preprint arXiv:2209.15246.
- Challenges earlier adversarial methods based OOD prevention mechanism and proposes a new one.
- Adopt generative OOD based methods. (OpenGAN as baseline)
- Proposes ATD (adversarial trained discriminator) [simple overview in figure 3]
- utilizes a pre-trained robust model to extract robust features, and a generator model to create OOD samples 11. Wenzel, F., Dittadi, A., Gehler, P. V., Simon-Gabriel, C. J., Horn, M., Zietlow, D., … & Locatello, F. (2022). Assaying out-of-distribution generalization in transfer learning. arXiv preprint arXiv:2207.09239.
- Empirically unified view of previous work (calibration, adversarial robustness, algorithmic corruption, invariance across shift), highlighting message discrepancies, providing recommendations on how to measure the robustness of a model and how to improve it.
- A lot of experimentation: Massive datasets, a lot of models.
- ID and OOD accuracies tend to increase jointly, but their relation is largely dataset-dependent, more nuanced and more complex than posited by previous, smaller scale studies
- kind of overview paer, many nice takeaways
-
Chang, W., Shi, Y., Tuan, H. D., & Wang, J. (2022). Unified Optimal Transport Framework for Universal Domain Adaptation. arXiv preprint arXiv:2210.17067. NeuralIPS2022
- RG: Most existing methods require manually threshold values to detect common samples and hard to extend to UniDA as the diverse ratios of common classes and fail to categories target-private (novel) samples (treated as a whole)
- TP: propose to use Optimal Transport (OT) to handle these issues under a unified framework (UniOT)
- OT-based partial alignment with adaptive filling to detect common classes without any predefined threshold values for realistic UniDA!
- automatically discover the difference between common and private classes using the statistical information of the assignment matrix
- OT-based target representation learning that encourages both global discrimination and local consistency to avoid source over-reliance
- Proposes a novel metric!!
- What are the required assumption??
- TP: propose to use Optimal Transport (OT) to handle these issues under a unified framework (UniOT)
-
Interesting relevant works related to OT based methods (provide benefits in global mapping, avoid degenerate solution)
-
OT can be extended towards unbalanced class distribution (generalized sinkhorn algo)
- wow got the idea!: Instead of softmax base P matrix they go for prototype based model.
- Joint optimization of global loss (inter-domain: Prototype based) and local loss (intra-domain: swapped prediction)
- finding common classes similar to ranking stat CCD
- row sum and column sum for a point to detect CCD
- Joint optimization of global loss (inter-domain: Prototype based) and local loss (intra-domain: swapped prediction)
- RG: Most existing methods require manually threshold values to detect common samples and hard to extend to UniDA as the diverse ratios of common classes and fail to categories target-private (novel) samples (treated as a whole)
-
Zhang, X., Jiang, J., Feng, Y., Wu, Z. F., Zhao, X., Wan, H., … & Gao, Y. (2022). Grow and Merge: A Unified Framework for Continuous Categories Discovery. arXiv preprint arXiv:2210.04174 (NeuralIPS-2022).
- Continuous Category discovery (CCD)- a dynamic setting (Figure 1)
-
What is the different between class incremental continual learning!!! (I think this time the new examples are unlabeled and novel??)
- different sets of features are needed for classification and category discovery:
- class discriminative features are preferred for classification, while rich and diverse features are more suitable for new category mining.
- more severe challenges for dynamic setting as the system is asked to deliver good performance for known classes over time, and at the same time continuously discover new classes from unlabeled data.
- TP: [network architectural modification] Grow and Merge (GM) methods: alternate between Grow! and Merge!
- Grow: increases the diversity of features through a continuous self-supervised learning for effective category mining!!
- related to pairwise similarity, ranking statistics, knowledge distillation (lwf) idea.
- Merge: merges the grown model with a static one to ensure satisfying performance for known classes
- Momentum encoder update!
- Category unification and branch unification.
- Federated Setting!!!
- Grow: increases the diversity of features through a continuous self-supervised learning for effective category mining!!
- What assumption are available regarding the new setting? do we know how many novel classes and their distribution??
- The number of novel class is given. [eq 1]
- different sets of features are needed for classification and category discovery:
-
-
Overview approaches: Figure 3
-
Proposes two metrics: Intelligent usages of ACC metrics at different time-step.
- Continuous Category discovery (CCD)- a dynamic setting (Figure 1)
-
Zhuang, J., Chen, Z., Wei, P., Li, G., & Lin, L. (2022). Open Set Domain Adaptation By Novel Class Discovery. arXiv preprint arXiv:2203.03329.
- Key ideas: Dynamic/Adaptive (restructuring) class nodes (iterative) [OSDA]
- Two stages (Bi-level optimization)
- Better writing is expected but should not be an option!!
- Interesting reference section to read through
- Key ideas: Dynamic/Adaptive (restructuring) class nodes (iterative) [OSDA]
-
Rizve, M. N., Kardan, N., Khan, S., Shahbaz Khan, F., & Shah, M. (2022). Openldn: Learning to discover novel classes for open-world semi-supervised learning. In European Conference on Computer Vision (pp. 382-401). Springer, Cham.
- pairwise similarity loss to discover novel classes.
- bi-level optimization rule this pairwise similarity loss exploits the information available in the labeled set to implicitly cluster novel class samples, while simultaneously recognizing samples from known classes (without pretraining!)
- after NCD, OpenLDN tx the open-world SSL into a standard SSL setting to achieve additional performance gains using existing SSL methods
- iterative pseudo-labeling: a simple and efficient method to handle noisy pseudo-labels of novel classes
- Kind of swapped prediction setting!!
- Key is the optimization procedure: multistage sequential alternative optimization (first feature then pairwiseSim and repeat)
- how the heck they determine a novel class sample???? Vague description
- Generate Pseudo-labels: Generate from one image and set it as the target for its augmented version and vice-versa
- Further swapped prediction
- Generate Pseudo-labels: Generate from one image and set it as the target for its augmented version and vice-versa
-
Li, Z., Otholt, J., Dai, B., Meinel, C., & Yang, H. (2022). A Closer Look at Novel Class Discovery from the Labeled Set. arXiv preprint arXiv:2209.09120.
- Existing research focuses on methodological level, with less emphasis on the analysis of the labeled set itself.
- TP: closer look at NCD from the labeled set and focus on two questions:
- Given a specific unlabeled set, what kind of labeled set can best support novel class discovery?
- Substantiate the hypothesis that NCD benefit more from a L with a large degree of semantic similarity to U
- A fundamental premise of NCD is that the labeled set must be related to the unlabeled set, but how can we measure this relation?
- introduce a mathematical definition for quantifying the semantic similarity between L and U: Transfer Leakage
- Given a specific unlabeled set, what kind of labeled set can best support novel class discovery?
- Findings: Labeled information may lead to sub-optimal results
- Two Solutions
- (i) pseudo transfer leakage, a practical reference for what sort of data we intend to employ
- (ii) A straightforward method, which smoothly combines supervised and self-supervised knowledge from the labeled set
- Too much theoretical paper:
- UNO worked best even under class notion mismatch!
-
Yu, Q., Ikami, D., Irie, G., & Aizawa, K. (2022). Self-Labeling Framework for Novel Category Discovery over Domains.
-
Open-set DA
-
Kind of noisy writing. However, here’s what we got
-
Only entropy loss over the target domain novel classes
-
Prototypical based learning
-
The KEY equation to cover the NCD problem that performs equipartition is EQUATION 11 (the best we need from here)
-
Two things in Equation 11: (i) Increase the network entropy [uniformly equipartition] (ii) Reduce entropy for each samples [unique decision making]
-
-
-
Equation 12 and 13 to realize/calculate the components of equation 11 (statistics of neuron to match uniformity)
- \[I(Y;X_t) = \mathcal{H}(\mathbb{E}_{x_t}[p_e(y|x_t)]) - \mathbb{E}_{x_t}[\mathcal{H}(p_e(y|x_t)]\]
-
-
Kalb, T., Roschani, M., Ruf, M., & Beyerer, J. (2021, July). Continual learning for class-and domain-incremental semantic segmentation. In 2021 IEEE Intelligent Vehicles Symposium (IV) (pp. 1345-1351). IEEE.
-
Previous approaches: Form of KD
-
evaluate and adapt established solutions for continual object recognition to the task of semantic segmentation
-
provide baseline methods and evaluation protocols for the task of continual semantic segmentation.
- Avoid Catastrophic Forgetting/Inference: in class-incremental learning KD and in domain-incremental learning replay methods are the most effective method.
-
Continual Learning Related Works: replay-based methods, regularization-based methods (prior-focused and data-focused methods.) and parameter isolation methods
- Data-focused: KD
- Prior-focused: vary the plasticity of individual weights based on an estimated importance of the weight in previous tasks (L2 weight loss)
-
- \[Input: x\in \mathcal{X} = \mathbb{N}^{H\times W\times 3} \text{ with label} y\in\{0,1\}^{H\times W\times |C|} \\ \text{Aim: Learn} f_\theta:\mathcal{X} \rightarrow \mathbb{R}^{H\times W\times |C|} \\ l_{ce} = -\frac{1}{H.W}\sum_{i\in I}\sum_{c\in C} y_{i,c} \log (\hat{y}_{i,c}) \\ \text{Domain Incremental } P(X_1)\neq P(X_2) \\ \text{Class Incremental } P(Y_1) \neq P(Y_2) \\ l_{kd} = -\frac{1}{|I|}\sum_{i\in I}\sum_{c\in C} \bar{y}_{i,c} \log (\hat{y}_{i,c}) \\ l_{lwf} = l_{ce}(y, \bar{y}) + \lambda l_{kd}(\hat{y}, \bar{y}) \\ l_{reg} = l_{ce}(y, \bar{y}) + \lambda \Omega_i(\theta_i, \bar(\theta)_i) \\\]
-
-
Li, W., Fan, Z., Huo, J., & Gao, Y. (2022). Modeling Inter-Class and Intra-Class Constraints in Novel Class Discovery. arXiv preprint arXiv:2210.03591.
-
Single stage joint optimization approach (Relatively Simple)
-
Increase KL divergence between labeled and unlabeled classes (inter-class)
-
Decrease KL divergence between both labeled and unlabeled classes (Intra-class)
-
Figure with the following set of equation form the overall system
-
\[\mathcal{L} = \mathcal{L}_{CE} - \alpha\mathcal{L}_{intra-class} + \beta \mathcal{L}_{inter-clas} \\
\mathcal{L}_{intra-class} = \mathcal{L}_{sKLD}^u + \mathcal{L}_{sKLD}^l \\
\mathcal{L}_{sKLD}^l = \frac{1}{2}D_{KL}(p^l_{ih}||\hat{p}^l_{ih}) + \frac{1}{2}D_{KL}(\hat{p}^l_{ih}||p^l_{ih})\\
\mathcal{L}_{inter-class} = \frac{1}{2}D_{KL}(p^l_{i}||p^u_{j}) + \frac{1}{2}D_{KL}(p^u_{j}||p^l_{i})\\\]
- Experimented with CIFAR Dataset.
-
-
Liu, Y., & Tuytelaars, T. (2022). Residual tuning: Toward novel category discovery without labels. IEEE Transactions on Neural Networks and Learning Systems.
- Optimization between Feature Preservation and Feature Adaptation in traditional TL
- tp: residual-tuning (ResTune): estimates a new residual feature from the pretrained network and adds it with a previous basic feature to compute the clustering objective together.
- builds a potentially appropriate bridge between NCD and continual learning.
- disentangled representation (More of a hierarchical representation): new residual feature from the pretrained network and then add it with a previous basic feature?
- basic and residual features alleviates the interference between the old and new knowledge
- adjust visual representations for unlabeled images and overcoming forgetting old knowledge acquired from labeled images without replaying the labeled images
- Three objectives: clustering, KD, pairwise labeling
- tp: residual-tuning (ResTune): estimates a new residual feature from the pretrained network and adds it with a previous basic feature to compute the clustering objective together.
-
Overcome problems with two-stage training
- Assumption: Sequential data (first labeled then unlabeled)
- Solution to how to avoid catastrophic forgetting due to semantic shift
- Layer Freezing causes rigidity
- a unified representation hits a bottleneck between feature preservation on L and feature adaptation on U (stability-plasticity tradeoff in continual learning)
- Assumption: Sequential data (first labeled then unlabeled)
-
Evolution: ACC
- Optimization between Feature Preservation and Feature Adaptation in traditional TL
-
Roy, S., Liu, M., Zhong, Z., Sebe, N., & Ricci, E. (2022). Class-incremental Novel Class Discovery. arXiv preprint arXiv:2207.08605.
-
problem of NCD in an unlabelled data set by leveraging a pre-trained model (trained on a labelled data set containing disjoint yet related categories)
-
TP: Frost: Inspired by rehearsal-based incremental learning methods!!!
- Proposes class-iNCD (New learning scheme): prevents forgetting of past information about the base classes by jointly exploiting
- base class feature prototypes
- feature-level knowledge distillation (avoid catastrophic forgetting, ResTune paper)
- Two step setting: We have a trained net, not the data
- Learn the supervision first
- Clustering objective (BCE) for Novel classes
- Prevent forgetting (feature distillation and feature-replay) for base classes
- Joint classifier (self-training)
- Proposes class-iNCD (New learning scheme): prevents forgetting of past information about the base classes by jointly exploiting
-
propose to store the base class feature prototypes from the previous task as exemplars, instead of raw images (to replay)
- Related work: NCD and incremental learning
- IL: model is trained on a sequence of tasks such that data from only the current task is available for training (evaluated on all)
- Regularization-base, Exemplar-based and Task-recency bias!
- Assumption:
- Old class-prototypes and variances are stored
- Related work: NCD and incremental learning
-
-
Chi, H., Liu, F., Yang, W., Lan, L., Liu, T., Han, B., … & Sugiyama, M. (2021). Demystifying Assumptions in Learning to Discover Novel Classes. arXiv preprint arXiv:2102.04002.
-
demystify assumptions behind NCD and find that high-level semantic features should be shared among the seen and unseen classes.
- NCD is theoretically solvable under certain assumptions and linked to meta-learning (similar assumption as NCD)
- When is solvable: Figure 1 explains all: Requires sampling in causality not the labeling in causality.
- Sampling in causality: From class label to sample: Specify the novel classes
- Labeling in causality: Unlabeled sample to class
- When is solvable: Figure 1 explains all: Requires sampling in causality not the labeling in causality.
- Care about clustering rule: Figure 3
-
-
Zhang, L., Qi, L., Yang, X., Qiao, H., Yang, M. H., & Liu, Z. (2022). Automatically Discovering Novel Visual Categories with Self-supervised Prototype Learning. arXiv preprint arXiv:2208.00979.
- leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue with missing annotations of novel classes
- propose a novel adaptive prototype learning method consisting of two main stages:
- Prototype representation learning: ability of instance and category discrimination of the feature extractor is boosted by self-supervised learning and adaptive prototypes (non parametric classification via clustering)
- Dino+Online prototype learning
- Prototype self-training: rectify offline pseudo labels and train a final parametric classifier for category clustering. (parametric classifier and self-training)
- pseudo labelling, prototypical pseudo label rectification, and joint optimization.
- Prototype representation learning: ability of instance and category discrimination of the feature extractor is boosted by self-supervised learning and adaptive prototypes (non parametric classification via clustering)
- propose a novel adaptive prototype learning method consisting of two main stages:
-
Claim: label and “pseudo-label” of unlabelled data, can recognize new categories without forgetting the old ones.
-
Related works: Semi-supervised (consistency regularization and Self-labeling), non contrastive self-supervision, and Transfer clustering (MCL, KCL, DEC)
- Methodology:
- Contextual augmentation: Crop doesn’t make sense in symbol
- Restricted rotation to understand the symbol concept.
- error at describing eq 5 (p_c,i should be binary and y_c,i should be Probability value)
- Contextual augmentation: Crop doesn’t make sense in symbol
- leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue with missing annotations of novel classes
-
Fei, Y., Zhao, Z., Yang, S., & Zhao, B. (2022). XCon: Learning with Experts for Fine-grained Category Discovery. arXiv preprint arXiv:2208.01898.
- ViT architecture
- Really bad notation [eq 2]
- propose a fine graining loss (modified GCD, CL loss) after data partitioning.
-
Sun, Y., & Li, Y. (2022). Open-world Contrastive Learning. arXiv preprint arXiv:2208.02764.
-
OpenCon learns compact representations for both known and novel classes
-
leverage the prototype vectors to separate known vs. novel classes in unlabeled data - prototype-based learning can be rigorously interpreted from an Expectation-Maximization (EM) algorithm perspective. - Utilize protoype based solution instead of sinkhorn-knopp approach of clustering novel classes. - Kinda SupCon setting for the CL setting (generalized one).
- Randomly initialized prototype and update them
- Great IDEA, power of randomized learning.
- K prototyes initialization for the k classes (randomization avoids the class collapse)
- Contrast based on the prototypes based classification of the unlabeled instances (self-labeling)
- For both the L and U set.
- Avoid sink-horn knopp (N examples to k classes)
- Great IDEA, power of randomized learning.
-
-
-
Zhang, C., Hu, C., Xu, R., Gao, Z., He, Q., & He, X. (2022). Mutual Information-guided Knowledge Transfer for Novel Class Discovery. arXiv preprint arXiv:2206.12063.
-
propose a principle and general method to transfer semantic knowledge between seen and unseen classes
-
insight: MI measures the relation between seen and unseen classes in a restricted label space and maximizing MI promotes transferring semantic knowledge.
-
Well there are some vague formulation!!!!
-
-
Joseph, K. J., Paul, S., Aggarwal, G., Biswas, S., Rai, P., Han, K., & Balasubramanian, V. N. (2022). Novel Class Discovery without Forgetting. arXiv preprint arXiv:2207.10659.
-
identify and formulate a new, pragmatic problem setting of NCDwF: Novel Class Discovery without Forgetting
-
propose 1) a method to generate pseudo-latent representations for previously available L to alleviate forgetting 2) a MI based regularizer to enhance unsupervised NCD, and 3) a simple Known Class Identifier for generalized inference form L and U.
-
Related works: Incremental learning: to alleviate the catastrophic forgetting of model when learning across a sequence of tasks (requires all labels) by some regularization, memory based approaches, dynamically expanding and parameter isolation.
-
TP: labeled data can’t be accessed during NCD time
-
-
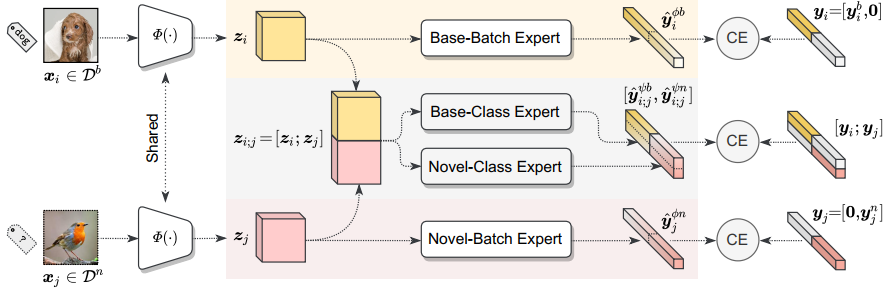
Yang, M., Zhu, Y., Yu, J., Wu, A., & Deng, C. (2022). Divide and Conquer: Compositional Experts for Generalized Novel Class Discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14268-14277).
-
focus on this generalized setting of NCD (GNCD) by challenging two-step setup for L and U.
-
propose to divide and conquer it with two groups of Compositional Experts (ComEx).
-
propose to strengthen ComEx with global-to-local and local-to-local regularization.
-
Unsup clustering enforce neighborhood consistency and average entropy maximization: achieve clustering and avoid collapse.
-
two group of experts (lol: final layers MTL)! batch and class-wise
-
-
-
Zheng, J., Li, W., Hong, J., Petersson, L., & Barnes, N. (2022). Towards Open-Set Object Detection and Discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3961-3970).
- present a new task, namely Open-Set Object Detection and Discovery (OSODD)
- propose a two-stage method that first uses an open-set object detector to predict both known and unknown objects
- propose a category discovery method using domain-agnostic augmentation, CL and semi-supervised clustering.
- approach: Open-set object detector with memory module, object category discovery with representation learning,
- present a new task, namely Open-Set Object Detection and Discovery (OSODD)
-
Joseph, K. J., Paul, S., Aggarwal, G., Biswas, S., Rai, P., Han, K., & Balasubramanian, V. N. (2022). Spacing Loss for Discovering Novel Categories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3761-3766).
- Spacing loss that enforces separability in the latent space using cues from multi-dimensional scaling
-
an either operate as a standalone method or can be plugged into existing methods to enhance them
- characterize existing NCD approaches into single-stage and two-stage methods based on if they require access to L and U data together while discovering NC
- Single-stage NCD models can access L and U together
- common NCD methodologies: learn a feature extractor using the L and use clustering, psuedo-labelling or CL
-
Experiment with CIFAR dataset
-
Two characteristics: 1) the ability to transport similar samples to locations equidistant from other dissimilar samples in the latent manifold, 2) the datapoints to refresh their associativity to a group as the learning progresses
-
- Spacing loss summary: i) finding equidistant point
- characterize existing NCD approaches into single-stage and two-stage methods based on if they require access to L and U data together while discovering NC
-
- Spacing loss that enforces separability in the latent space using cues from multi-dimensional scaling
-
Zhao, Y., Zhong, Z., Sebe, N., & Lee, G. H. (2022). Novel Class Discovery in Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4340-4349).
- Three stage learning.
- LABELED data, Saliency map (another model dependent), ranking based MA training.
-
Vaze, S., Han, K., Vedaldi, A., & Zisserman, A. (2022). Generalized Category Discovery. arXiv preprint arXiv:2201.02609.
- Related works: Semi-supervised, OSR,
-
how that existing NCD methods are prone to overfit the labelled classes in this generalized setting
-
CL and a semi-supervised k-means clustering to recognize images without a parametric classifier
- Approach overview:
- CL pretraining (ViT, DiNo pretrained) [kinda SCL setup]
- Label assignment with semi-supervised k-means (use a non-parametric method)
- Appendices [figure 4]
- utilization of k++ for smart initialization and clustering methods. [elbow for finding K?]
- Approach overview:
-
-
leverages the CL trained vision transformers to assign labels directly through clustering.
- Existing recognition methods have several restrictive assumptions,
- the unlabelled instances only coming from known — or unknown
- classes and the number of unknown classes being known a-priori.
- TP: Challenges these and propose GCD. (improved NCD)
- Approaches: Baseline, ViT, CL, Semi-supervised setup.
- Dataset: CIFAR10, CIFAR100 and ImageNet-100
- Existing recognition methods have several restrictive assumptions,
- OSR: aims detect test-time images which do not belong to one of the labeled classes, does not require any further classification
- NCD: aim to discover new classes in the unlabelled set, prone to overfit.
- key insight is to leverage the strong ‘NN’ classification property of vision transformers along with CL
- TP: use of contrastive training and a semi-supervised k-means clustering
- key insight is to leverage the strong ‘NN’ classification property of vision transformers along with CL
- NCD: aim to discover new classes in the unlabelled set, prone to overfit.
- Related works: Semi-supervised, OSR,
- Three stage learning.
-
TP: estimating the number of categories in unlabelled dataYang, H. M., Zhang, X. Y., Yin, F., Yang, Q., & Liu, C. L. (2020). Convolutional prototype network for open set recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence.
- CNN for representation learning but replaces the closed-world assumed softmax with an open-world oriented prototype model. [CPN]
- design several discriminative losses [OVA loss]
- propose a generative loss (maximizing the log-likelihood) to act as a latent regularization. [is that as vague as their earlier paper??] - Nice but very easy: It bounds the class distance by some distance (eventually increases the log(distance) increases log likelihood) - Discusses two rejection rules (distance based and probability based) - Pretty straight forward
- CNN for representation learning but replaces the closed-world assumed softmax with an open-world oriented prototype model. [CPN]
-
Zhou, Y., Liu, P., & Qiu, X. (2022, May). KNN-Contrastive Learning for Out-of-Domain Intent Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 5129-5141).
- Modified contrastive loss KNN-CL (T)
- NLP works
- KNN clustering and contrastive learning.
- apply loss in different labels.
- Modified contrastive loss KNN-CL (T)
-
Dietterich, Thomas G., and Alexander Guyer. “The Familiarity Hypothesis: Explaining the Behavior of Deep Open Set Methods.” arXiv preprint arXiv:2203.02486 (2022).
- Claim: computer vision systems should master two functions: (a) detecting when an object belongs to a new category [TP] (b) learning to recognize that new category
-
The Familiarity Hypothesis (FH): The standard model succeeds by detecting the absence of familiar features in an image rather than by detecting the presence of novel features in the image.
-
interesting ways to find feature activation [validity!!]
-
Discussion section is a gem!!
-
Research GAP: Detecting such “novel category” objects is formulated as an anomaly detection problem
- TP demonstrate: the Familiarity Hypothesis that these methods succeed because they are detecting the absence of familiar learned features rather than the presence of novelty
- reviews evidence from the literature (how to show them!!) and presents additional evidence and suggest some promising research directions.
- Looked into the penultimate layer activation norm (low for unseen classes): as Network was not activated enough [no feature found!!]
- TP demonstrate: the Familiarity Hypothesis that these methods succeed because they are detecting the absence of familiar learned features rather than the presence of novelty
-
- Claim: computer vision systems should master two functions: (a) detecting when an object belongs to a new category [TP] (b) learning to recognize that new category
2021
-
Hüllermeier, Eyke, and Willem Waegeman. “Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods.” Machine Learning 110 (2021): 457-506.
- introduction to the topic of uncertainty in machine learning as well as an overview of attempts so far at handling uncertainty in general and formalizing this distinction in particular.
- Distinguish between aleatoric and epistemic uncertainty.
- introduction to the topic of uncertainty in machine learning as well as an overview of attempts so far at handling uncertainty in general and formalizing this distinction in particular.
-
Bao, W., Yu, Q., & Kong, Y. (2021). Evidential deep learning for open set action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 13349-13358).
- performs novel evidential learning to support open set action recognition with principled and efficient uncertainty evaluation.
- Evidential Uncertainty Calibration (EUC: Equation 3) and Contrastive Evidential Debiasing (CED) modules effectively mitigate over-confident predictions and static bias problems, respectively.
-
Saito, K., & Saenko, K. (2021). Ovanet: One-vs-all network for universal domain adaptation. In Proceedings of the ieee/cvf international conference on computer vision (pp. 9000-9009).
- Universal Domain Adaptation (UNDA) aims to handle both domain-shift and category-shift between two datasets
- RG: Existing methods manually set a threshold to reject ”unknown” samples based on a pre-defined ratio of unknown samples
- propose a method to learn the threshold using source samples and to adapt it to the target domain.
- train a one-vs-all classifier for each class using labeled source data.
- adapt the open-set classifier to the target domain by minimizing class entropy.
- resulting framework is the simplest of all baselines of UNDA and is insensitive to the value of a hyper-parameter, yet outperforms others.
- OVANet: (figure 4)
- Hard Negative Classifier Sampling (modified one-vs-all classifier)
- Open-set entropy minimization
- Utilize both open-set and close-set classifier. [equation 2, 3]
-
Abdelsalam, M., Faramarzi, M., Sodhani, S., & Chandar, S. (2021). Iirc: Incremental implicitly-refined classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 11038-11047).
- introduce the “IIRC” setup, an extension to the class incremental learning where incoming batches of classes have two granularity levels.
- each sample could have a highlevel (coarse) label like “bear” and a low-level (fine) label like “polar bear” [figure ]
- This is a hard problem as the assumption (granularity) behind the decision changes in between
- We are calling it error because not matching with human sense
- The human sense is contextual and kind of can be formalized to any notion.
- For DL model the question remain always same: What are the digits, What object in the image, bounding box the object, what actions etc.
- e.g. with a bear image human can decide many thing and provide support for the answer
- Semantic segmentation more through answar.
- e.g. with a bear image human can decide many thing and provide support for the answer
- Benchmark to evaluate IIRC
- conclusion: Distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image
- Metric: Jaccard Similarity (intersection over union)
- introduce the “IIRC” setup, an extension to the class incremental learning where incoming batches of classes have two granularity levels.
-
Zhu, F., Zhang, X. Y., Wang, C., Yin, F., & Liu, C. L. (2021). Prototype augmentation and self-supervision for incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5871-5880).
- simple non-exemplar based method, PASS, to address the catastrophic forgetting problem in incremental learning.
- propose to memorize one class-representative prototype for each old class and adopt prototype augmentation (protoAug) in the deep feature space to maintain the decision boundary of previous tasks: Maintain decision boundary
- Which one to remember?: typically the class mean in the deep feature space
- How to use the prototypes?
- investigate the value of simple Gaussian noise based augmentation
- Which one to remember?: typically the class mean in the deep feature space
- employ self-supervised learning (SSL) to learn more generalizable and transferable features for other tasks, which demonstrates the effectiveness of SSL in incremental learning
- to learn task-agnostic and transferable representations & avoid overfit
- Rotation similarity
- propose to memorize one class-representative prototype for each old class and adopt prototype augmentation (protoAug) in the deep feature space to maintain the decision boundary of previous tasks: Maintain decision boundary
- Compare with only non-exemplar based methods!
- What ensures that the model still project the earlier example to the old prototype location after weight update????
- the previous model, which mainly carries taskspecific features, might be a bad initialization for current task [figure 1]
- kind of momentum based weight update approaches [figure 2]
- Vague in implementation details
- Key ideas: Figure 2 but back to the question posed above.
- simple non-exemplar based method, PASS, to address the catastrophic forgetting problem in incremental learning.
-
Mai, Z., Li, R., Kim, H., & Sanner, S. (2021). Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3589-3599).
- Recency Bias!! of continual learning: The latest class has the most impact on the network.
- TP: Instead of softmax classification proposes nearest class mean classifier (prototype-based)
- Memory bank approaches for the continual setting
- Softmax Deficiency: New class (architecture modification)?? Decouple representation and classification, Task-recency bias
- Proposes class prototype based learning.
-
Sehwag, V., Chiang, M., & Mittal, P. (2021). Ssd: A unified framework for self-supervised outlier detection. arXiv preprint arXiv:2103.12051.
- TP asks what training information is required to design an effective outlier/out-of-distribution (OOD) detector
- TP: use self-supervised representation learning followed by a Mahalanobis distance based detection in the feature space
- Two possible extension to i) few-shot and ii) additional training labeled data!
- Scaling with eigenvalues removes the bias, making Mahalnobis distance effective for outlier detection in the feature space
- Equation 3 is hard to calculated
- how to cover the OOD mean variance? how to make sure they fall under different region (not zero or overlap with each other)
- Class clustering and cluster centric OOD detector (my thoughts: probabilistic decision?? using neuron statistics)
- requires to make sure the neuron statistics behaves accordingly
- computational expensive to find the mean and variance for all the classes!
-
Wang, J., Ma, Z., Nie, F., & Li, X. (2021). Progressive self-supervised clustering with novel category discovery. IEEE Transactions on Cybernetics.
- Graph clustering perspective
- a novel clustering approach referred to as the progressive self-supervised clustering method with NCD (PSSCNCD),
-
De Lange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., … & Tuytelaars, T. (2021). A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence, 44(7), 3366-3385.
- Focus on task incremental classification (TP)
- a taxonomy and extensive overview of the state-of-the-art
- a novel framework to continually determine the stability-plasticity trade-off of the continual learner
- a comprehensive experimental comparison of 11 state-of-the-art continual learning methods and 4 baselines.
- empirically scrutinize method strengths and weaknesses on three benchmarks
- study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented
- qualitatively compare methods in terms of required memory, computation time and storage.
- Three main group of continual learning
- Replay (raw data/ generate pseudo-samples)
- Rehearsal Methods: explicitly retrain on a limited subset of stored samples while training on new tasks. (prone to overfit)
- Constraint Optimization: key idea: only constrain new task updates to not interfere with previous tasks and achieved through projecting the estimated gradient direction on the feasible region outlined by previous task gradients through first order Taylor series approximation.
- Pseudo-labels: output of previous model(s) given random inputs are used to approximate previous task samples
- Regularization: avoids storing raw inputs, prioritizing privacy, and alleviating memory requirements. Introduce an extra regularization term in the loss function, consolidating previous knowledge
- Data-focused: knowledge distillation from a previous model (LwF)
- Prior-focused: estimate a distribution over the model parameters, used as prior when learning from new data: Elastic weight consolidation
- Parameter Isolation: dedicates different model parameters to each task, to prevent any possible forgetting (not-scalable)
- Replay (raw data/ generate pseudo-samples)
- Focus on task incremental classification (TP)
-
Cao, K., Brbic, M., & Leskovec, J. (2021). Open-world semi-supervised learning. arXiv preprint arXiv:2102.03526.
-
goal is to solve the class distribution mismatch between labeled and unlabeled data
-
open-world SSL: GCD generalizes novel class discovery and traditional (closed-world) SSL.
-
ORCA: introduces uncertainty adaptive margin mechanism to circumvent the bias towards seen classes caused by learning discriminative features for seen classes faster than for the novel classes.
- reduces the gap between intra-class variance of seen with respect to novel classes
- TP: Kinda GCD setting
-
does not need to know the number of novel classes ahead of time and can automatically discover them at the deployment time.
-
Related works: Robust SSL (reject unknown), NCD (cluster novel classes), GZST (requires class knowledge in prior)
-
Single stage Joint optimization
- Supervised objective with with uncertainty adaptive margin
- Pairwise objective (Pseudo label): Only Positive samples??
- Regularization term (match class distibution)
-
key insight in ORCA is to control intra-class variance of seen classes using uncertainty on unlabeled data
- the variance among: seen and unseen: clusters should be similar
- Utilize KL divergence and neuron statistics regularization.
- Ensure that discriminative representations for seen classes are not learned too fast compared to novel classes.
-
Perform self-labeling operation.
-
-
Choudhury, S., Laina, I., Rupprecht, C., & Vedaldi, A. (2021). Unsupervised part discovery from contrastive reconstruction. Advances in Neural Information Processing Systems, 34, 28104-28118.
-
Res.Gap.: representation learning at part level has received significantly less attention (most work focus on object and scene level)
-
Propose an unsup approach to object part discovery and segmentation
-
three contributions
- construct a proxy task through a set of objectives (encourages the model to learn a meaningful decomposition of the image into its parts) [CL]
- prior work argues for reconstructing or clustering pre-computed features as a proxy to parts
- this paper shows that: this alone is unlikely to find meaningful parts;
- because of their low resolution and the tendency of classification networks to spatially smear out information
- image reconstruction at the level of pixels can alleviate this problem, acting as a complementary cue
- the standard evaluation based on keypoint regression does not correlate well with segmentation quality
- introduce different metrics, NMI and ARI (better characterize the decomposition of objects into parts)
- given a collection of images of a certain object category (e.g., birds) and corresponding object masks, we want to learn to decompose an object into a collection of repeatable and informative parts.
- no universally accepted formal definition for what constitutes a “part”, the nature of objects and object parts is accepted as different
- (a) consistency to transformation (equivariance), (b) visual consistency (or self-similarity), and (c) distinctiveness among different parts.
- construct a proxy task through a set of objectives (encourages the model to learn a meaningful decomposition of the image into its parts) [CL]
-
-
Jia, X., Han, K., Zhu, Y., & Green, B. (2021). Joint representation learning and novel category discovery on single-and multi-modal data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 610-619).
- a generic, end-to-end framework to jointly learn a reliable representation and assign clusters to unlabelled data. - Propose to overcluster than the original unknown classe (U Cardinality is known) [**Well! Gives something to work with!!!!**] - Joint optimization of many Losses - CL (both instance and cluster [for known label]) - BCE (siamese network setup) [pseudo label] - Consistent MSE loss (different view of same data) - CE loss -
Fini, E., Sangineto, E., Lathuilière, S., Zhong, Z., Nabi, M., & Ricci, E. (2021). A unified objective for novel class discovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9284-9292).
- depart from this traditional multi-objective and introduce a UNified Objective function [UNO] for NCD - favoring synergy between supervised and unsupervised learning - multi-view self-labeling strategy generate pseudo-labels homogeneously with GT - overview figure 2 [multihead network (L and U data)] - replace multi-objective using the multitask setting. - look at the **gradient flow strategy** - similar idea of **swav** - dimension mismatch* in eq 4 and 5 - can be fixed by altering Y and L in the eq 4 - <embed src="https://mxahan.github.io/PDF_files/UNO.pdf" width="100%" height="850px"/> -
Zhong, Z., Fini, E., Roy, S., Luo, Z., Ricci, E., & Sebe, N. (2021). Neighborhood Contrastive Learning for Novel Class Discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10867-10875).
- New framework for NCD [NCL]
- i) a encoder trained on the L to generates representations (a generic query sample and its neighbors are likely to share the same class)
- retrieve and aggregate pseudo-positive pairs with CL
-
ii) propose to generate hard negatives by mixing L and U samples in the feature space.
- first idea: the local neighborhood of a query in the embedding space will contain samples most likely belong to the same semantic category (pseudo-+ve)
- numerous positives obtain a much stronger learning signal compared to the traditional CL with only two views
- first idea: the local neighborhood of a query in the embedding space will contain samples most likely belong to the same semantic category (pseudo-+ve)
- i) a encoder trained on the L to generates representations (a generic query sample and its neighbors are likely to share the same class)
- second idea: address the better selection of -ve to further improve CL
- related works: negative mining.
- Their approach [figure 3]
- related works: negative mining.
-
Well: add bunch of losses together for joint optimization.
-
kind of avoid false-ve in CL
-
Assumption of L intersection U = {}
-
- New framework for NCD [NCL]
-
Zhong, Z., Zhu, L., Luo, Z., Li, S., Yang, Y., & Sebe, N. (2021). Openmix: Reviving known knowledge for discovering novel visual categories in an open world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9462-9470).
- mix the unlabeled examples from an open set and the labeled examples from known classes
- non-overlapping labels and pseudo-labels are simultaneously mixed into a joint label distribution
- kinda data augmentation approach like MixUp
- generates training samples by incorporating both labeled and unlabeled samples
- Assumption: : 1) labeled samples of old classes are exactly clean, and 2) L intersection U = empty set.
- prevent the model from fitting on wrong pseudo-labels
- proposes simple baseline.
- effectively leveraging the labeled data during the unsupervised clustering in unlabeled data [unsupervised step described in section 3.1]
- compounds examples in two ways: 1) mix U examples with L samples; and 2) mix U examples with reliable anchors.
- mix the unlabeled examples from an open set and the labeled examples from known classes
-
Zhao, B., & Han, K. (2021). Novel visual category discovery with dual ranking statistics and mutual knowledge distillation. Advances in Neural Information Processing Systems, 34.
-
semantic partitions of unlabelled images (new classes) by leveraging a labelled dataset (contains different but relevant categories of images) [RS]
- two branch learning (one branch focusing on local part-level information and the other branch focusing on overall characteristics)
- dual ranking statistics on both branches to generate pseudo labels for training on the unlabelled data
- transfer knowledge from labelled data to unlabelled data
- dual ranking statistics on both branches to generate pseudo labels for training on the unlabelled data
- introduce a mutual KD method to allow information exchange and encourage agreement between the two branches for discovering new categories
- TP: Joint optimization of many many losses (eq 10)
-
-
Han, K., Rebuffi, S. A., Ehrhardt, S., Vedaldi, A., & Zisserman, A. (2021). Autonovel: Automatically discovering and learning novel visual categories. IEEE Transactions on Pattern Analysis and Machine Intelligence.
-
self-supervised learning to train the representation from scratch on the union of labeled and unlabeled data (avoid bias of labeled data) [low-level features]
-
ranking statistics to transfer the model’s knowledge of the labelled classes [high level features]
-
optimizing a joint objective function on the labelled and unlabelled subsets of the data
-
Enable estimating the number of classes
-
Utilization of average clustering accuracy (ACC) and Cluster validity index (CVI) [silohouette index]
-
-
Schott, L., von Kügelgen, J., Träuble, F., Gehler, P., Russell, C., Bethge, M., … & Brendel, W. (2021). Visual representation learning does not generalize strongly within the same domain. arXiv preprint arXiv:2107.08221.
-
Empirical paper to test if representation learning approaches correctly infer the generative factors of variation in simple datasets (visual tasks).
- To learn effective statistical relationships, the training data needs to cover most combinations of factors of variation (like shape, size, color, viewpoint, etc.) [exponential issues]
- large factor variation leads to out-of distribution.
- As soon as a factor of variation is outside the training distribution, models consistently predict previously observed value
- learning the underlying mechanisms behind the factors of variation should greatly reduce the need for training data and scale more with factors.
- underlying data generation process
- large factor variation leads to out-of distribution.
- TP: Four dataset with various factors of variations. [dSprites, Shapes3D, MPI3D, celebglow]
- shape, size, color, viewpoint, etc
- TP: models mostly struggle to learn the underlying mechanisms regardless of supervision signal and architecture.
- Experimented with different controllable factor of variations.
- Thoughts on assumption (inductive biases) for learning generalization
- Representation format: PCA
- Architectural bias: invariance and equivalence.
- Demonstrate empirical results by varying FoVs (6 in totals)
- Check for composition, interpolation, extrapolation, and decomposition (4.2)
- Modular performance (good on the in-distribution data)
- Check for composition, interpolation, extrapolation, and decomposition (4.2)
- Good insights for different cases (section 5 conclusion)
- Disentanglement helps on downstream task but not necessarily in the OOD cases
- empirically show that among a large variety of models, no tested model succeeds in generalizing to all our proposed OOD settings (extrapolation, interpolation, composition)
- Instead of extrapolating, all models regress the OOD factor towards the mean in the training set
- The performance generally decreases when factors are OOD regardless of the supervision signal and architecture
- To learn effective statistical relationships, the training data needs to cover most combinations of factors of variation (like shape, size, color, viewpoint, etc.) [exponential issues]
-
Reiterate the importance of the data. (Even gan fails to learn that)
-
-
Chen, G., Peng, P., Wang, X., & Tian, Y. (2021). Adversarial reciprocal points learning for open set recognition. arXiv preprint arXiv:2103.00953.
- Target: reduce the empirical classification risk on the labeled known data and the open space risk on the potential unknown data simultaneously.
- TP formulate the open space risk problem from multi-class integration perspective, and model the unexploited extra-class space with a novel concept Reciprocal Point
- ARPL: minimize the overlap of known and unknown distributions without loss of known classification accuracy by
- RP is learned by the extra-class space with the corresponding known class
- the confrontation among multiple known categories are employed to reduce the empirical risk.!!
- an adversarial margin constraint to reduce the open space risk by limiting the latent open space constructed by RP!!
- an instantiated adversarial enhancement method generate diverse and confusing training samples (To estimate the unknown distribution from open space) [using RP and known classes]
- ARPL: minimize the overlap of known and unknown distributions without loss of known classification accuracy by
- TP formulate the open space risk problem from multi-class integration perspective, and model the unexploited extra-class space with a novel concept Reciprocal Point
- SOTA problems: Figure 1
- argue that not only the known classes but also the potential unknown deep space should be modeled in the training
- Well how? - By RP: - RP: Whats not something. (Reciprocal of the prototypical learning) [figure 3]
- key Idea: finds the non-catness and tell cat if otherwise happens (nice), however, is it that easy?? computationally possible
- Example based solutions!!
- kinda one vs all setting!! (centre for all other classes)
- Well how? - By RP: - RP: Whats not something. (Reciprocal of the prototypical learning) [figure 3]
- argue that not only the known classes but also the potential unknown deep space should be modeled in the training
-
Related work: Classifier with rejection option. OOD, Prototype learning
-
Good problem formulation: The adversarial section constrain open space.
-
Algo 1 (IDEA), Algo 2 (implemntation details)
-
Gems in 3.4 section
-
Adversarial setup for generating confusion samples. [Architecture in figure 5]
-
TP: adds an extra entropy based terms with GAN G maximization.
-
Look into the experimentation of the batch normalization.
-
Somehow connected to the disentanglement settings.
- Target: reduce the empirical classification risk on the labeled known data and the open space risk on the potential unknown data simultaneously.
-
Vaze, Sagar, Kai Han, Andrea Vedaldi, and Andrew Zisserman. “Open-set recognition: A good closed-set classifier is all you need.” arXiv preprint arXiv:2110.06207 (2021).
- demonstrate that the ability of a classifier to make the ‘none-of-above’ decision is highly correlated with its accuracy on the closed-set classes
- RQ: whether a well-trained closed-set classifier can perform as well as recent algorithms
- TP: show that the open-set performance of a classifier can be improved by enhancing its closed-set accuracy
- TP: simentic shift benchmark??
- Interested related works: Out-of-Distribution (OOD) detection, novelty detection, anomaly detection, novel category discovery, novel feature discovery
-
Different Baseline: Maximum Softmax probability (MSP), ARPL: Reciprocal point learning, (varies on how to calculate the confidence score)
-
Kodama, Yuto, Yinan Wang, Rei Kawakami, and Takeshi Naemura. “Open-set Recognition with Supervised Contrastive Learning.” In 2021 17th International Conference on Machine Vision and Applications (MVA), pp. 1-5. IEEE, 2021.
- TP: Explicitly uses distance learning (CL!!) to obtain the feature space for the open-set problem
- Supcon, EVT to find the normality score.
- TP: Explicitly uses distance learning (CL!!) to obtain the feature space for the open-set problem
2020
-
Amini, A., Schwarting, W., Soleimany, A., & Rus, D. (2020). Deep evidential regression. Advances in Neural Information Processing Systems, 33, 14927-14937.
- Estimate a continuous target as well as its associated evidence in order to learn both aleatoric and epistemic uncertainty
- Place evidential priors over the original Gaussian likelihood function and training the NN to infer the hyperparameters of the evidential distribution
- Estimate a continuous target as well as its associated evidence in order to learn both aleatoric and epistemic uncertainty
-
Allen-Zhu, Z., & Li, Y. (2020). Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. arXiv preprint arXiv:2012.09816.
-
Liu, J., Lin, Z., Padhy, S., Tran, D., Bedrax Weiss, T., & Lakshminarayanan, B. (2020). Simple and principled uncertainty estimation with deterministic deep learning via distance awareness. Advances in Neural Information Processing Systems, 33, 7498-7512.
- RG: The practicality in real-time, industrial-scale applications of Bayesian neural networks and deep ensembles approaches to estimate the predictive uncertainty of a deep learning model are limited due to their heavy memory and inference cost.
- TP: study principled approaches to high-quality uncertainty estimation that require only a single deep neural network (DNN).
- formalizing the uncertainty quantification as a minimax learning problem
- identify distance awareness, i.e., the model’s ability to properly quantify the distance of a testing example from the training data manifold, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation
- propose Spectral-normalized Neural Gaussian Process (SNGP) that improves the distance-awareness ability of modern DNNs, by adding a weight normalization step during training and replacing the output layer with a Gaussian Process
-
Liang, S., Li, Y., & Srikant, R. (2017). Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690.
- propose ODIN, a simple and effective method that does not require any change to a pre-trained neural network
- Observation: using temperature scaling and adding small perturbations to the input can separate the softmax score distributions between ID and OOD images
- Equation 2 (input processing section: Key point) and 3 (threshold based OOD detection) describe overall approaches
- Idea from adversarial perturbation.
- propose ODIN, a simple and effective method that does not require any change to a pre-trained neural network
-
Ye, H. J., Lu, S., & Zhan, D. C. (2020). Distilling cross-task knowledge via relationship matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12396-12405).
- TP deals with reusing the knowledge from a cross-task teacher — two models are targeting non-overlapping label spaces
- emphasize that the comparison ability between instances acts as an essential factor threading knowledge across domains
- A local embedding-induced classifier from the teacher further supervises the student’s classification confidence
- decomposes the KD flow into branches for embedding and the top-layer classifier
- Kind of contrastive learning approaches.
- Teacher network helps in triplet sampling for CL
- instance wise contrastive learning setting for embedding learning (pairwise similarity)
- When architectural difference occurs the direct embedding distillation fails.
-
Wang, Z., Salehi, B., Gritsenko, A., Chowdhury, K., Ioannidis, S., & Dy, J. (2020, November). Open-world class discovery with kernel networks. In 2020 IEEE International Conference on Data Mining (ICDM) (pp. 631-640). IEEE.
- may not be scalable for large image dataset!
- Still cluster and retrain network expansion.
- Multi-stage Solution
- Alternative to spectral clustering!
- Network expansion idea from the continual learning
-
Han, K., Rebuffi, S. A., Ehrhardt, S., Vedaldi, A., & Zisserman, A. (2020). Automatically discovering and learning new visual categories with ranking statistics. arXiv preprint arXiv:2002.05714.
-
hypothesize that a general notion of what constitutes a “good class” can be extracted from labeled to Unlabeled
-
later paper worked on various ranking methods for unlabeled data.
-
utilize the metrics of deep transfer clustering.
-
very good visualization but kind of build on previous works.
-
- Chen, Guangyao, Limeng Qiao, Yemin Shi, Peixi Peng, Jia Li, Tiejun Huang, Shiliang Pu, and Yonghong Tian. “Learning open set network with discriminative reciprocal points.” In European Conference on Computer Vision, pp. 507-522. Springer, Cham, 2020.
- Reciprocal Point (RP), a potential representation of the extra-class space corresponding to each known category.
- sample is classified to known or unknown by the otherness with RP
- Reciprocal Point (RP), a potential representation of the extra-class space corresponding to each known category.
- Geng, Chuanxing, Sheng-jun Huang, and Songcan Chen. “Recent advances in open set recognition: A survey.” IEEE transactions on pattern analysis and machine intelligence 43, no. 10 (2020): 3614-3631.
- Very good terminologies to get
- Four types of class categories: Known known class (KKC), K Unknown C (KUC), UKC: provided side information, UUC
- Figure 2 demonstrate goal for OSR
- Four types of class categories: Known known class (KKC), K Unknown C (KUC), UKC: provided side information, UUC
- Very good terminologies to get
2019 and Earlier
-
Malinin, A., & Gales, M. (2018). Predictive uncertainty estimation via prior networks. Advances in neural information processing systems, 31.
- Dirichlet prior
- Uncertainty in predictive can result from uncertainty in model parameters, irreducible data uncertainty and uncertainty due to distributional mismatch between the test and training data distributions.
- Different actions might be taken depending on the source of the uncertainty (how to distinguish)
- TP: proposes a new framework for modeling predictive uncertainty called Prior Networks (PNs) which explicitly models distributional uncertainty
- PN allows distributional uncertainty to be treated as distinct from both data uncertainty and model uncertainty
- Model uncertainty, or epistemic uncertainty measures the uncertainty in estimating the model parameters given the training data - this measures how well the model is matched to the data. Model uncertainty is reducible as the size of training data increases.
- Data uncertainty, or aleatoric uncertainty is irreducible uncertainty which arises from the natural complexity of the data, such as class overlap, label noise, homoscedastic and heteroscedastic noise. Data uncertainty can be considered a ’known-unknown’ - the model understands (knows) the data and can confidently state whether a given input is difficult to classify (an unknown).
- Distributional uncertainty arises due to mismatch between the training and test distributions (also called dataset shift) - a situation which often arises for real world problems. Distributional uncertainty is an ’unknown-unknown’ - the model is unfamiliar with the test data and thus cannot confidently make predictions
- PN allows distributional uncertainty to be treated as distinct from both data uncertainty and model uncertainty
- PNs do this by parameterizing a prior distribution over predictive distributions. Focuses on uncertainty for classification and evaluates PNs on the tasks of identifying OOD samples and detecting misclassification
-
Hein, M., Andriushchenko, M., & Bitterwolf, J. (2019). Why relu networks yield high-confidence predictions far away from the training data and how to mitigate the problem. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 41-50).
- ReLU NN yield a piecewise linear classifier function produce almost always high confidence predictions far away from the training data
- propose a new robust optimization technique kinda adversarial training which enforces low confidence predictions for OOD
- ACET (section 4): easy pesy- enforce uniform distribution prediction for OOD data. (how to find OOD data!!)
-
Sensoy, M., Kaplan, L., & Kandemir, M. (2018). Evidential deep learning to quantify classification uncertainty. Advances in neural information processing systems, 31.
- Issues with class probabilities with SM: The eventual softmax-squashed multinomial likelihood is then maximized with respect to the neural net parameters
- noteworthy that the probabilistic interpretation of the cross-entropy loss is mere Maximum Likelihood Estimation (MLE).
- As being a frequentist technique, MLE is not capable of inferring the predictive distribution variance.
- Softmax is also notorious with inflating the probability of the predicted class as a result of the exponent employed on the neural net outputs?
- The consequence is then unreliable uncertainty estimations, as the distance of the predicted label of a newly seen observation is not useful for the conclusion besides its comparative value against other classes.
- noteworthy that the probabilistic interpretation of the cross-entropy loss is mere Maximum Likelihood Estimation (MLE).
- The output of a standard neural network classifier is a probability assignment over the possible classes for each sample. However, a Dirichlet distribution parametrized over evidence represents the density of each such probability assignment; hence it models second-order probabilities and uncertainty
- When an observation about a sample relates it to one of the K attributes, the corresponding Dirichlet parameter is incremented to update the Dirichlet distribution with the new observation. For instance, detection of a specific pattern on an image may contribute to its classification into a specific class. In this case, the Dirichlet parameter corresponding to this class should be incremented. This implies that the parameters of a Dirichlet distribution for the classification of a sample may account for the evidence for each class
- Comparison: (a) L2 corresponds to the standard deterministic neural nets with softmax output and weight decay, (b) Dropout refers to the uncertainty estimation model (c) Deep Ensemble, (d) FFG refers to the Bayesian neural net with the additive parametrization (e) MNFG refers to the structured variational inference method (f) EDL is the method TP propose
- Issues with class probabilities with SM: The eventual softmax-squashed multinomial likelihood is then maximized with respect to the neural net parameters
-
Chaudhry, A., Rohrbach, M., Elhoseiny, M., Ajanthan, T., Dokania, P. K., Torr, P. H., & Ranzato, M. A. (2019). On tiny episodic memories in continual learning. arXiv preprint arXiv:1902.10486.
- dubbed episodic memory, that stores few examples from previous tasks and then to replay these examples when training for future tasks
- empirically analyze the effectiveness of a very small episodic memory in a CL setup where each training example is only seen once
- Very simple/naive idea of external memory save for the past experiences [algo 1]
-
Javed, K., & White, M. (2019). Meta-learning representations for continual learning. Advances in neural information processing systems, 32.
- Propose OML, an objective that directly minimizes catastrophic interference by learning representations that accelerate future learning (?) and robust to forgetting under online updates in continual learning.
- learn naturally sparse representations that are more effective for online updating!!
- complementary to existing continual learning strategies, such as MER and GEM
- Algo 1 and 2: Key parts: easy to understand: Are they basically the same? WT biscuit?
- Algo 1: full data, algo 2: batch update with batch containing SINGLE sample [online]!! (only diff.)
- Sample efficient meta learning. Alternating update.
- Propose OML, an objective that directly minimizes catastrophic interference by learning representations that accelerate future learning (?) and robust to forgetting under online updates in continual learning.
-
Rao, D., Visin, F., Rusu, A., Pascanu, R., Teh, Y. W., & Hadsell, R. (2019). Continual unsupervised representation learning. Advances in Neural Information Processing Systems, 32.
- deal with non-stationary distributions by attempting to learn a series of tasks sequentially
- propose an approach (CURL) to tackle a more general problem that refer to unsupervised continual learning
- Gap: previous works focus on the supervised/RL setting.
- learning representations without any knowledge about task identity
- Explore abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled
- proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime,
- incorporates additional rehearsal-based techniques to deal with catastrophic forgetting
- (WHAT?) this is trivial. do they do anything to prevent CF in their original approaches.
- incorporates additional rehearsal-based techniques to deal with catastrophic forgetting
- TP: Graphical generative model and VAE approaches. (reconstructing raw data)
-
Aljundi, R., Lin, M., Goujaud, B., & Bengio, Y. (2019). Gradient based sample selection for online continual learning. Advances in neural information processing systems, 32.
- Formulate (replay-based) sample selection as a constraint reduction problem based on the constrained optimization view of continual learning.
- Active sample selection strategy
- goal is to select a fixed subset of constraints that best approximate the feasible region defined by the original constraints
- equivalent to maximizing the diversity of samples in the replay buffer with parameters gradient as the feature
- Heavy mathematical but interesting
- Related to Gradient Episodic Memory (GEM)
- Formulate (replay-based) sample selection as a constraint reduction problem based on the constrained optimization view of continual learning.
-
Zenke, F., Poole, B., & Ganguli, S. (2017, July). Continual learning through synaptic intelligence. In International conference on machine learning (pp. 3987-3995). PMLR.
- introduce intelligent synapses that bring some of this biological complexity into artificial neural networks
- Synaptic Framework
- developed a class of algorithms which keep track of an importance measure (reflects past credit for improvements of the task objective Lµ for task µ to individual synapses)
- Each synapse accumulates task relevant information over time, and exploits this information to rapidly store new memories without forgetting
- difficult to draw a clear line between a learning and recall phase in Conti. L.
- greatest gaps in the design of modern ANNs versus biological neural networks lies in the complexity of synapses
- study the role of internal synaptic dynamics to enable ANNs to learn sequences of classification tasks.
- Catastrophic forgetting can be largely alleviated by synapses with a more complex three-dimensional state space
- the synaptic state tracks the past and current parameter value, and maintains an online estimate of the synapse’s “importance” toward solving problems encountered in the past
- as the task changes, TP consolidate the important synapses by preventing them from changing in future tasks.
- Prior works: Architectural, Functional, Structural
- Gist: Equation 4, an extra regularization term.
- introduce intelligent synapses that bring some of this biological complexity into artificial neural networks
-
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., … & Hadsell, R. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13), 3521-3526.
- Elastic Weight consolidation (EWC): Figure 2 as explanation
- Equation three is all we need: Fisher information matrix regularization.
-
Lee, K., Lee, K., Lee, H., & Shin, J. (2018). A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31.
- softmax classifier are known to produce highly overconfident posterior distributions even for such abnormal samples
- obtain the class conditional Gaussian distributions w.r.t (low- and upper-level) features of the deep models under Gaussian discriminant analysis, which result in a confidence score based on the Mahalanobis distance.
- link for gaussian discriminant analysis
- Gap: prior methods have been evaluated for detecting either out-of-distribution or adversarial samples
- proposed method enjoys broader usage by applying it to class-incremental learning (in future??)
- Idea: measure the probability density of test sample on feature spaces of DNNs utilizing “generative” (distance-based) classifier concept
- assume that pre-trained features can be fitted well by a class-conditional Gaussian distribution since its posterior distribution can be shown to be equivalent to the softmax classifier under Gaussian discriminant analysis
-
Li, Z., & Hoiem, D. (2017). Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12), 2935-2947.

- Good utilization of sharpening to train LOSS_OLD
-
Asano, Y. M., Rupprecht, C., & Vedaldi, A. (2019). Self-labelling via simultaneous clustering and representation learning. arXiv preprint arXiv:1911.05371.
- Combining clustering and representation learning naively may leads to ill posed learning problems with degenerate solutions
- propose a novel principled MI based formulation to addresses these issues
- extends standard CE minimization to an optimal transport problem, which is solved efficiently by Sinkhorn-Knopp algorithm.
- Overcome DeepCluster Issue: combining inconventional representation learning with clustering: there exist degenerate solution.
-
Utilize equi-partition condition for the labels
- Combining clustering and representation learning naively may leads to ill posed learning problems with degenerate solutions
-
Quintanilha, I. M., de ME Filho, R., Lezama, J., Delbracio, M., & Nunes, L. O. (2018). Detecting Out-Of-Distribution Samples Using Low-Order Deep Features Statistics.
-
a simple ensembling of first and second order deep feature statistics (mean and standard deviation within feature) can differentiate ID and OOD.
-
Figure 1: Plug-and-play propose solution.

-
linear classifier over the neural activation stats.
-
-
Liu, Z., Miao, Z., Zhan, X., Wang, J., Gong, B., & Yu, S. X. (2019). Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2537-2546).
-
Aim: classify among majority and minority classes, generalize from a few known instances, and acknowledge novelty upon a never seen instance.
-
TP: OLTR learning from naturally distributed data and optimizing accuracy over a balanced test set of head, tail, and open classes
-
methodologies: 1. dynamic Meta Embedding. connected to Self-attention
-
overall figure 2
-
-
Bendale, A., & Boult, T. (2015). Towards open world recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1893-1902).
-
Oza, P., & Patel, V. M. (2019). C2ae: Class conditioned auto-encoder for open-set recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2307-2316).
- TO: an OSR algorithm using class conditioned auto-encoders with novel training and testing methodologies
- 2 steps: 1. closed-set classification and, 2. open-set identification
- utilize EVT to find the threshold for known/unknown.
- Encoder learns the first task following the closed-set classification training pipeline, decoder learns the second task by reconstructing conditioned on class identity
- TO: an OSR algorithm using class conditioned auto-encoders with novel training and testing methodologies
-
Scheirer, W. J., Rocha, A., Micheals, R. J., & Boult, T. E. (2011). Meta-recognition: The theory and practice of recognition score analysis. IEEE transactions on pattern analysis and machine intelligence, 33(8), 1689-1695.
-
Utilize EVT for OSR (rough note to start)
- figure 3 summarizes:
- matches the distribution with EVT distribution and check for tail cases.
- EVT is analogous to a CTL, but tells us what the distribution of extreme values should look like as we approach the limit
- Extreme value distributions are the limiting distributions that occur for the maximum (or minimum, depending on the data representation) of a large collection of random observations from an arbitrary distribution
- falls in one of the three exponential family format.
-
observation: most recognition systems, the distance or similarity scores are bounded from both above and below
-
takes the tail of these scores, which are likely to have been sampled from the extrema of their underlying portfolios, and fits a Weibull distribution to that data.
-
- figure 3 summarizes:
-
-
Bendale, A., & Boult, T. E. (2016). Towards open set deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1563-1572).
- Introduce OpenMax layer [alternative to softmax] to incorporate open set setting.
- Modify the activation weights before softmax function [eq 2, aglo 1,2]
- estimates the probability of an input being from an unknown class
- greatly reduces the number of obvious errors made by a deep network!!!
- provides bounded open space risk, thereby formally providing OSR solution
-
key element in detecting unknown probability is to adapt Meta-Recognition concepts in the networks’ penultimate layer activation patterns
- Utilize EVT to incorporate rejection probability.
- Introduce OpenMax layer [alternative to softmax] to incorporate open set setting.
-
Hsu, Y. C., Lv, Z., Schlosser, J., Odom, P., & Kira, Z. (2019). Multi-class classification without multi-class labels. arXiv preprint arXiv:1901.00544.
- a new strategy for multi-class classification (no class-specific labels) using pairwise similarity between examples
- present a probabilistic graphical model for it, and derive a loss function for DL
- generalizes to the supervised, unsupervised cross-task, and semi-supervised settings
- reduce the problem of classification to a meta problem (siamese network)
- has the vibe of student teacher model [MCL]
- pretty standard approach for forming a binary class from multi-class.
- has the vibe of student teacher model [MCL]
-
Hsu, Yen-Chang, Zhaoyang Lv, and Zsolt Kira. “Learning to cluster in order to transfer across domains and tasks.” arXiv preprint arXiv:1711.10125 (2017).
-
perform tx learning across domains and tasks, formulating it as a problem of learning to cluster [KCL]
-
TP: i) design a loss function to regularize classification with a constrained clustering loss (learn a clustering network with the transferred similarity metric)!!
- TP: ii) for cross-task learning (unsupervised clustering with unseen categories) propose a framework to reconstruct and estimate the no of semantic clusters
- utilize the pairwise information in a fashion similar to constrained clustering
- LCO: pairwise similarity (pre-contratstive set up: matching network)
- utilize the pairwise information in a fashion similar to constrained clustering
-
-
Han, K., Vedaldi, A., & Zisserman, A. (2019). Learning to discover novel visual categories via deep transfer clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8401-8409).
-
problem of discovering novel object categories in an image collection [DTC]
-
assumption: prior knowledge of related but different image classes
-
use such prior knowledge to reduce the ambiguity of clustering, and improve the quality of the newly discovered classes (how??)
- TP: i) Extend DEC ii) improve the algorithm by introducing a representation bottleneck, temporal ensembling, and consistency (how??) [a method to estimate the number of classes in the unlabelled data]
- ii) modification: account unlabeled data, include bottleneck, incorporate temporal ensemble and consistency.
- TP: o transfers knowledge from the known classes, using them as probes to diagnose different choices for the number of classes in the unlabelled subset.
- transfers knowledge from the known classes, using them as probes to diagnose different choices for the number of classes in the unlabelled subset.
- TP: i) Extend DEC ii) improve the algorithm by introducing a representation bottleneck, temporal ensembling, and consistency (how??) [a method to estimate the number of classes in the unlabelled data]
-
learn representation from labeled data and fine-tune using unlabeled data!!!
- Algorithm 1 [warm-up training, final training], algo 1 [estimate class no]
- learning model params and centre simultaneously.
- Algorithm 1 [warm-up training, final training], algo 1 [estimate class no]
-
-
Scheirer, Walter J., Anderson de Rezende Rocha, Archana Sapkota, and Terrance E. Boult. “Toward open set recognition.” IEEE transactions on pattern analysis and machine intelligence 35, no. 7 (2012): 1757-1772.
- “open set” recognition: incomplete world knowledge is present at training, and unknown classes can be submitted during testing
- TP: “1-vs-Set Machine,” which sculpts a decision space from the marginal distances of a 1-class or binary SVM with a linear kernel
- In classification, one assumes there is a given set of classes between which we must discriminate. For recognition, we assume there are some classes we can recognize in a much larger space of things we do not recognize
-
Yang, H. M., Zhang, X. Y., Yin, F., & Liu, C. L. (2018). Robust classification with convolutional prototype learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3474-3482).
- lack of robustness for CNN is caused by the softmax layer (discriminative and based on the assumption of closed world)
- TP: Proposes convolutional prototype learning (CPL)
- design multiple classification criteria to train
- prototypical loss as regularizers
- Looks like requires a lot of computations!
- Put a constraint: classes need to be inside a circle [prototype loss]!!
- How the heck it got connected to generative model !!
- TP: Proposes convolutional prototype learning (CPL)
- lack of robustness for CNN is caused by the softmax layer (discriminative and based on the assumption of closed world)