Self-Supervised Learning
2023
- Shwartz-Ziv, R., & LeCun, Y. (2023). To Compress or Not to Compress–Self-Supervised Learning and Information Theory: A Review. arXiv preprint arXiv:2304.09355.
- RG: The role of information theoretic information bottleneck is unclear in SSL context.
- TP: scrutinize various SSL approaches from an information theoretic perspective, introducing a unified framework that encapsulates SS information-theoretic learning problem
- weave together existing research into a cohesive narrative, delve into contemporary self-supervised methodologies, and spotlight potential research avenues and inherent challenges
- discuss the empirical evaluation of information-theoretic quantities and their estimation methods
- TP furnishes an exhaustive review of the intersection of information theory, self-supervised learning, and deep neural networks.
- Section 5: Optimizing Information in Deep Neural Networks: Challenges and Approaches
- Measuring the information in High dimensional spaces.
- Balestriero, R., Ibrahim, M., Sobal, V., Morcos, A., Shekhar, S., Goldstein, T., … & Goldblum, M. (2023). A cookbook of self-supervised learning. arXiv preprint arXiv:2304.12210.
- Origin of SSL:
- information restoration: masked image prediction, colorization,
- Temporal relationship in the video:
- Learning spatial context: RotNet, Jigsaw
- Grouping similar image together: k-mean clustering, mean-shift, optimal-transport
- Generative Model: autoencoder, RBM, GAN
- Multi-view invariance: modern methods.
- Deep metric learning family: SimCLR/NNCLR/Meanshift/SCL
- self-distillation family: BYOL/SimSIAM/DINO
- Canonical correlation analysis: VICReg/BarlowTwins/SWAV/W-MSE
- Origin of SSL:
- Cabannes, V., Bottou, L., Lecun, Y., & Balestriero, R. (2023). Active Self-Supervised Learning: A Few Low-Cost Relationships Are All You Need. arXiv preprint arXiv:2303.15256.
- generalize and formalize this principle through Positive Active Learning (PAL) where an oracle queries semantic relationships between samples
- unveils a theoretical learning framework beyond SSL, that can be extended to tackle supervised and semi-supervised depending on oracle
- provides algorithm to embed a priori knowledge, e.g. some observed labels, into any SSL losses without any change in the training.
- provides an active learning framework to bridge the gap between theory and practice of AL (!), based on simple-to-answer-by-nonexperts queries of semantic relationships between inputs.
- Research gap in SSL: combine the label information or any priori knowledge?
- TP: redefine existing SSL in terms of a similarity graph – nodes represent data samples and edges reflect known inter-sample relationships
- think about learning in terms of similarity graph: yields a spectrum on which SSL and supervised learning can be seen as two extremes
- TP: use a similarity graph to define the SSL and supervised training losses to reduce cost and expert requirement of active learning
- Active learning in SSL: what are similar and what not?
- strategize Positive Active Learning (PAL), and present some key analysis on the benefits of PAL over traditional active learning
- GEM paper of k-partitioned graphs
- supervised setting: C partitioned (C disconnected components)
- direct observation that VICReg is akin to Laplacian Eigenmaps or multidimensional scaling, SimCLR is akin to Cross-entropy and BarlowTwins is akin to Canonical Correlation Analysis [theorem 1]
- generalize and formalize this principle through Positive Active Learning (PAL) where an oracle queries semantic relationships between samples
-
Shwartz-Ziv, R., Balestriero, R., Kawaguchi, K., Rudner, T. G., & LeCun, Y. (2023). An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization. arXiv preprint arXiv:2303.00633.
-
Same paper of what do we maximize in SSL (paper from 2022)
- demonstrate how information-theoretic quantities can be obtained for deterministic networks as an alternative to the commonly used unrealistic stochastic networks assumption.
- relate the VICReg objective to mutual information maximization and use it to highlight the underlying assumptions of the objective.
- derive a generalization bound for VICReg, providing generalization guarantees for downstream tasks and present new SSL
-
2015
-
Dosovitskiy, Alexey, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. “Discriminative unsupervised feature learning with exemplar convolutional neural networks.” IEEE transactions on pattern analysis and machine intelligence 38, no. 9 (2015): 1734-1747.
-
Doersch, Carl, Abhinav Gupta, and Alexei A. Efros. “Unsupervised visual representation learning by context prediction.” In Proceedings of the IEEE international conference on computer vision, pp. 1422-1430. 2015.
-
Crop position learning pretext!
-
Figure 2 (problem formulation) and 3 (architectures) shows the key contribution
-
-
Tishby, Naftali, and Noga Zaslavsky. “Deep learning and the information bottleneck principle.” In 2015 IEEE Information Theory Workshop (ITW), pp. 1-5. IEEE, 2015.
-
Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. “Siamese neural networks for one-shot image recognition.” In ICML deep learning workshop, vol. 2. 2015.
- Original contrastive approach with two (either similar or dissimilarity) images [algorithmic]
-
Wang, Xiaolong, and Abhinav Gupta. “Unsupervised learning of visual representations using videos.” In Proceedings of the IEEE international conference on computer vision, pp. 2794-2802. 2015.
-
Visual tracking provides the supervision!!! [sampling method for CL]
-
Siamese-triplet networks: energy based max-margin loss
-
Experiments: VOC 2012 dataset (100k Unlabeled videos)
-
interesting loss functions (self note: please update the pdf files)
-
2016
-
Xie, Junyuan, Ross Girshick, and Ali Farhadi. “Unsupervised deep embedding for clustering analysis.” In International conference on machine learning, pp. 478-487. PMLR, 2016.
-
Deep Embedded Clustering (DEC) Learns (i) Feature representation (ii) cluster assignments
-
Experiment: Image and text corpora
-
Contribution: (a) joint optimization of deep embedding and clustering; (b) a novel iterative refinement via soft assignment (??); (c) state-of-the-art clustering results in terms of clustering accuracy and speed
-
target distribution properties: (1) strengthen predictions (i.e., improve cluster purity), (2) put more emphasis on data points assigned with high confidence, and (3) normalize loss contribution of each centroid to prevent large clusters from distorting the hidden feature space.
-
Computational complexity as iteration over large data samples
-
Assumptions and objectives: The underlying assumption of DEC is that the initial classifier’s high confidence predictions are mostly correct
-
Two metrics: NMI (normalized MI), and Generalizablity: L_tr / L_val
-
-
Joulin, Armand, Laurens Van Der Maaten, Allan Jabri, and Nicolas Vasilache. “Learning visual features from large weakly supervised data.” In European Conference on Computer Vision, pp. 67-84. Springer, Cham, 2016.
-
Sohn, Kihyuk. “Improved deep metric learning with multi-class n-pair loss objective.” In Proceedings of the 30th International Conference on Neural Information Processing Systems, pp. 1857-1865. 2016.
- Deep metric learning (solves the slow convergence for the contrastive and triple loss)
- what is the penalty??
-
How they compared the convergences
- This paper: Multi-class N-pair loss
- developed in two steps (i) Generalization of triplet loss (ii) reduces computational complexity by efficient batch construction (figrue 2) taking (N+1)xN examples!!
- This paper: Multi-class N-pair loss
-
Experiments on visual recognition, object recognition, and verification, image clustering and retrieval, face verification and identification tasks.
-
identify multiple negatives [section 3], efficient batch construction
- Deep metric learning (solves the slow convergence for the contrastive and triple loss)
-
Noroozi, Mehdi, and Paolo Favaro. “Unsupervised learning of visual representations by solving jigsaw puzzles.” In European conference on computer vision, pp. 69-84. Springer, Cham, 2016.
- Pretext tasks (solving jigsaw puzzle) - self-supervised
-
Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. “Shuffle and learn: unsupervised learning using temporal order verification.” In European Conference on Computer Vision, pp. 527-544. Springer, Cham, 2016.
- Pretext Task: a sequence of frames from a video is in the correct temporal order (figure 1) [sampling method for CL]
- Capture temporary variations
- Fusion and classification [not the CL directly]
-
experiment Net: CNN Based network, data: UCF101, HMDB51 & FLIC, MPII (pose Estimation)
- self note: There’s more.
- Pretext Task: a sequence of frames from a video is in the correct temporal order (figure 1) [sampling method for CL]
-
Oh Song, Hyun, Yu Xiang, Stefanie Jegelka, and Silvio Savarese. “Deep metric learning via lifted structured feature embedding.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4004-4012. 2016.
- Proposes a different loss function (Equation-3)
- Non-smooth and requires special data mining
- Solution: This paper: optimize upper bound of eq3, instead of mining use stochastic approach!!
- This paper: all pairwise combination in a batch!! O(m2)
- uses mini batch
- Not-random batch formation: Importance Sampling
- Hard-negative mining
-
Gradient finding in the algorithm-1, mathematical analysis
- Discusses one of the fundamental issues with contrastive loss and triplet loss!
- different batches puts same class in different position
-
Experiment: Amazon Object dataset- multiview .
- Proposes a different loss function (Equation-3)
2017
-
Qi, C., & Su, F. (2017, September). Contrastive-center loss for deep neural networks. In 2017 IEEE international conference on image processing (ICIP) (pp. 2851-2855). IEEE.
-
Randomized center selection, class assignment, and constrastive learning to enforce closeness between similar classes.
-
Eq 2 [loss function]
-
-
Santoro, Adam, David Raposo, David GT Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. “A simple neural network module for relational reasoning.” arXiv preprint arXiv:1706.01427 (2017).
-
Zhang, Richard, Phillip Isola, and Alexei A. Efros. “Split-brain autoencoders: Unsupervised learning by cross-channel prediction.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1058-1067. 2017.
- Extension of autoencoders to cross channel prediction [algorithmic]
- Predict one portion to other and vice versa + loss on full reconstruction.
- Two disjoint auto-encoders.
- Tried both the regression and classification loss
- Section 3 sums it up
- Cross-channel encoders
- Split-brain autoencoders.
- Cross-channel encoders
- Section 3 sums it up
- Extension of autoencoders to cross channel prediction [algorithmic]
-
Fernando, Basura, Hakan Bilen, Efstratios Gavves, and Stephen Gould. “Self-supervised video representation learning with odd-one-out networks.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3636-3645. 2017.
- Pretext tasks: Finding the odd-one (O3N) video using fusion. [sampling method for CL]
- Temporal odd one! Target: Regression task
-
Network: CNN with fusion methods.
- Experiments: HMDB51, UCF101
- Pretext tasks: Finding the odd-one (O3N) video using fusion. [sampling method for CL]
-
Denton, Emily L. “Unsupervised learning of disentangled representations from video.” In Advances in neural information processing systems, pp. 4414-4423. 2017.
-
Encoder-Decoder set up for the disentangled [disentanglement representation]
-
Hypothesis: Content (time invariant) and Pose (time variant)
-
Two Encoders for the pose and content; Concatenate the output for single Decoder
-
Introduce adversarial loss
-
Video generation conditioned on context, and pose modeling via LSTM.
-
2018
-
Károly, A. I., Fullér, R., & Galambos, P. (2018). Unsupervised clustering for deep learning: A tutorial survey. Acta Polytechnica Hungarica, 15(8), 29-53.
- NN: Self-organizing maps, Kohonen maps, Adaptive resonance theory, Autoencoders, Co-localization, Generative Models.
-
Aljalbout, Elie, Vladimir Golkov, Yawar Siddiqui, Maximilian Strobel, and Daniel Cremers. “Clustering with deep learning: Taxonomy and new methods.” arXiv preprint arXiv:1801.07648 (2018).
-
Three components: Main encoder networks (concerns with architecture, Losses, and cluster assignments)
-
Non-cluster loss: Autoencoder reconstruction losses
-
Various types of clustering loss (note)
-
Combine losses: Pretraining / jointly training / variable scheduleing
-
Cluster update: Jointly update with the network model / Alternating update with network models
-
Relevant methods: Deep Embedded Clustering (Xie et al, 2016), Deep Clustering Network (yang et al, 2016), Discriminatively Boosted Clustering (Li et al, 2017), ..
-
-
Belghazi, Mohamed Ishmael, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. “Mutual information neural estimation.” In International Conference on Machine Learning, pp. 531-540. 2018.
- present a Mutual Information Neural Estimator (MINE): linearly scalable with dimensionality and sample size, trainable through back-prop
- improve adversarially trained generative models and implement the Information Bottleneck, applying it to supervised classification
- Algorithm 1: Key (careful about the bar)
- present a Mutual Information Neural Estimator (MINE): linearly scalable with dimensionality and sample size, trainable through back-prop
-
Hjelm, R. Devon, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. “Learning deep representations by mutual information estimation and maximization.” arXiv preprint arXiv:1808.06670 (2018).
- locality of input knowledge and match prior distribution adversarially (DeepInfoMax)
-
Maximize input and output MI
- Experimented on Images
- Compared with VAE, BiGAN, CPC
- Experimented on Images
-
- Evaluate represenation by Neural Dependency Measures (NDM)
-
Global features (Anchor, Query) and Local features of the query (+), local feature map of random images
- locality of input knowledge and match prior distribution adversarially (DeepInfoMax)
-
Wu, Zhirong, Alexei A. Efros, and Stella X. Yu. “Improving generalization via scalable neighborhood component analysis.” In Proceedings of the European Conference on Computer Vision (ECCV), pp. 685-701. 2018.
-
SCNA (Modified version of the NCA approach)
-
Aim to reduce the computation complexity of the NCA by taking two assumptions
- Partial gradient update making the mini-batch gradient update possible - TP: Device a mechanism called augmented memory for the generalization. (a version of momentum update!) -
-
Caron, Mathilde, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. “Deep clustering for unsupervised learning of visual features.” In Proceedings of the European Conference on Computer Vision (ECCV), pp. 132-149. 2018.
- Cluster Deep features and make them pseudo labels. [fig 1]
- Cluster (k-means) for training CNN [Avoid trivial solution of all zeros!]
- Motivation from Unsupervised feature learning, self-supervised learning, generative model
- More
-
Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. “Representation learning with contrastive predictive coding.” arXiv preprint arXiv:1807.03748 (2018).
- Predicting the future [self-supervised task design]
- derive the concept of context vector (from earlier representation)
- use the context vector for future representation prediction.
- derive the concept of context vector (from earlier representation)
- TP: Great works with some foundation of CL
- probabilistic (AR) contrastive loss!!
- in latent space
- probabilistic (AR) contrastive loss!!
- Experiments on the speech, image, text and RL
- CPC (3 things) - Aka- InfoNCE (coining the term)
- compression, autoregressive and NCE
- CPC (3 things) - Aka- InfoNCE (coining the term)
-
Energy based like setup
-
Figure 4: about what they did!
-
- Predicting the future [self-supervised task design]
-
Wu, Zhirong, Yuanjun Xiong, Stella X. Yu, and Dahua Lin. “Unsupervised feature learning via non-parametric instance discrimination.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3733-3742. 2018.
-
non-parametric classifier via feature representation (Memory Bank)
- Memory bank stores instance features (used for kNN classifier)
- Dimention reduction: one of the key [algorithmic] contribution
- Experiments
- obj detect and image classification
- connect to
- selfsupervised learning (related works) and Metric learning (unsupervised fashion)
- NCE (to tackle class numbers) - [great idea, just contrast with everything else in E we get the classifier]
- instance-level discrimination, non-parametric classifier.
- compared with known example (non-param.)
- interesting setup section 3
- representation -> class (image itself) (compare with instance) -> loss function (plays the key role to distinguish)
- NCE from memory bank
- Monte carlo sampling to get the all contrastive normalizing value for denominator
- proximal parameter to ensure the smoothness for the representations {proximal regularization:}
- Memory bank stores instance features (used for kNN classifier)
-
-
Sermanet, Pierre, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, Sergey Levine, and Google Brain. “Time-contrastive networks: Self-supervised learning from video.” In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1134-1141. IEEE, 2018.
- Multiple view point [same times are same, different time frames are different], motion blur, viewpoint invariant
- Regardless of the viewpoint [same time same thing , same representation]
- Considered images [sampling method for CL]
- Representation is the reward
- TCN - a embedding {multitask embedding!}
-
imitation learning
-
PILQR for RL parts
- Huber-style loss
- Multiple view point [same times are same, different time frames are different], motion blur, viewpoint invariant
2019
-
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., & Kalantidis, Y. (2019). Decoupling representation and classifier for long-tailed recognition. arXiv preprint arXiv:1910.09217.
- decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition
- Findings (1) data imbalance might not be an issue in learning high-quality representations; (2) with representations learned with the simplest instance-balanced (natural) sampling, achieve strong long-tailed recognition ability by adjusting only the classifier.
- common long-tailed benchmarks like ImageNet-LT, Places-LT and iNaturalist (achieve sota with decoupling representation and classifier)
- Approach: first train models to learn representations with different sampling strategies (standard instance-based sampling, class-balanced sampling and their mixture). Next, we study three different basic approaches to obtain a classifier with balanced decision boundaries, on top of the learned representations. (re-training the parametric linear classifier in a class-balancing manner (i.e., re-sampling); non-parametric nearest class mean classifier, normalizing the classifier weights, which adjusts the weight magnitude directly to be more balanced by adding a temperature to modulate the normalization procedure.
- decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition
-
Wu, J., Long, K., Wang, F., Qian, C., Li, C., Lin, Z., & Zha, H. (2019). Deep comprehensive correlation mining for image clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8150-8159).
- TP DCCM
- incorporate other (three??) useful correlation! (as traditional approaches only utilizes the sample correlation)
- Instead of pairwise, pseudo-label supervision is proposed to investigate category information and learn discriminative features.
- features’ robustness to image transformation of input space is fully (!) explored- consistency loss!!
- The triplet mutual information among features is presented for clustering problem to lift the recently discovered instance-level deep MI to a triplet-level formation
- Correlation among different feature layers! (My idea: sharpening)
- Taxonomy:
- Pseudo-graph supervision: Pairwise matching (contrastive loss)
- Pseudo-label supervision: k-label partition and supervision (e.g. sinkhorn-knopp, knn)
-
Dwibedi, Debidatta, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. “Temporal cycle-consistency learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1801-1810. 2019.
- Temporal video alignment problem: the task of finding correspondences across multiple videos despite many factors of variation
- TP: Temporal cycle consistency losses (complementary to other methods [TCN, shuffle and learn])
- Dataset: Penn AR, Pouring dataset
- TP: Focus on temporal reasoning!! (metrics)
- learns representations by aligning video sequences of the same action
- Requires differentiable cycle-consistency losses
- TP: Focus on temporal reasoning!! (metrics)
-
- Figure 2: interesting but little hard to understand
-
Li, Xueting, Sifei Liu, Shalini De Mello, Xiaolong Wang, Jan Kautz, and Ming-Hsuan Yang. “Joint-task self-supervised learning for temporal correspondence.” arXiv preprint arXiv:1909.11895 (2019).
-
Xie, Qizhe, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V. Le. “Unsupervised data augmentation for consistency training.” arXiv preprint arXiv:1904.12848 (2019).
- TP: how to effectively noise unlabeled examples (1) and importance of advanced data augmentation (2)
- Investigate the role of noise injection and advanced data augmentation
- Proposes better data augmentation in consistency training: Unsupervised Data Augmentation (UDA)
- Experiments with vision and language tasks
-
Bunch of experiment with six language tasks and three vision tasks.
-
Consistency training as regularization.
-
UDA: Augment unlabeled data!! and quality of the noise for augmentations.
-
Noise types: Valid noise, Diverse noise, and Targeted Inductive biases
-
Augmentation types: RandAugment for image, backtranslating the language
-
Training techniques: confidence based masking, Sharpening Predictions, Domain relevance data filtering.
-
Interesting graph comparison under three assumption.
- TP: how to effectively noise unlabeled examples (1) and importance of advanced data augmentation (2)
-
Anand, Ankesh, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, and R. Devon Hjelm. “Unsupervised state representation learning in atari.” arXiv preprint arXiv:1906.08226 (2019).
-
Alwassel, Humam, Dhruv Mahajan, Bruno Korbar, Lorenzo Torresani, Bernard Ghanem, and Du Tran. “Self-supervised learning by cross-modal audio-video clustering.” arXiv preprint arXiv:1911.12667 (2019).
-
Sun, Chen, Fabien Baradel, Kevin Murphy, and Cordelia Schmid. “Learning video representations using contrastive bidirectional transformer.” arXiv preprint arXiv:1906.05743 (2019).
-
Han, Tengda, Weidi Xie, and Andrew Zisserman. “Video representation learning by dense predictive coding.” In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 0-0. 2019.
- Self-supervised AR (DPC)
- Learn dense coding of spatio-temporal blocks by predicting future frames (decrease with time!)
- Training scheme for future prediction (using less temporal data)
-
Care for both temporal and spatial negatives.
-
Look at their case for - the easy negatives (patches encoded from different videos), the spatial negatives (same video but at different spatial locations), and the hard negatives (TCN)
-
performance evaluated by Downstream tasks (Kinetics-400 dataset (pretrain), UCF101, HMDB51- AR tasks)
- Section 3.1 and 3.2 are core (contrastive equation - 5)
- Self-supervised AR (DPC)
-
Ye, Mang, Xu Zhang, Pong C. Yuen, and Shih-Fu Chang. “Unsupervised embedding learning via invariant and spreading instance feature.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6210-6219. 2019.
- Contrastive idea but uses siamese network.
-
Bachman, Philip, R. Devon Hjelm, and William Buchwalter. “Learning representations by maximizing mutual information across views.” arXiv preprint arXiv:1906.00910 (2019).
- Multiple view of shared context - Why MI (analogous to human representation, How??) - same understanding regardless of view - Whats the problem with others !!- Experimented with Imagenet
- Extension of local DIM in 3 ways (this paper calls it - augmented multi-scale DIM (AMDIM))
- Predicts features for independently-augmented views
- predicts features across multiple views
- Uses more powerful encoder
- Extension of local DIM in 3 ways (this paper calls it - augmented multi-scale DIM (AMDIM))
- Methods relevance: Local DIM, NCE, Efficient NCE computation, Data Augmentation, Multi-scale MI, Encoder, mixture based representation
- Experimented with Imagenet
-
Goyal, Priya, Dhruv Mahajan, Abhinav Gupta, and Ishan Misra. “Scaling and benchmarking self-supervised visual representation learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6391-6400. 2019.
-
Chen, Xinlei, Haoqi Fan, Ross Girshick, and Kaiming He. “Improved baselines with momentum contrastive learning.” arXiv preprint arXiv:2003.04297 (2020).
-
Tian, Yonglong, Dilip Krishnan, and Phillip Isola. “Contrastive multiview coding.” arXiv preprint arXiv:1906.05849 (2019).
-
Find the invariant representation
- Multiple view of objects (image) (CMC) - multisensor view or same object!!]
- Same object but different sensors (positive keys)
- Different object same sensors (negative keys)
- Experiment: ImageNEt, STL-10, two views, DIV2K cropped images
-
Positive pairs (augmentation)
-
Follow-up of Contrastive Predictive coding (no RNN but more generalized)
-
Compared with baseline: cross-view prediction!!
- Interesting math: Section 3 and experiment 4
- Mutual information lower bound Log(k = negative samples)- Lcontrastive
- Memory bank implementation
- Mutual information lower bound Log(k = negative samples)- Lcontrastive
-
-
Zhuang, Chengxu, Alex Lin Zhai, and Daniel Yamins. “Local aggregation for unsupervised learning of visual embeddings.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6002-6012. 2019.
-
Tschannen, Michael, Josip Djolonga, Paul K. Rubenstein, Sylvain Gelly, and Mario Lucic. “On mutual information maximization for representation learning.” arXiv preprint arXiv:1907.13625 (2019).
-
Löwe, Sindy, Peter O’Connor, and Bastiaan S. Veeling. “Putting an end to end-to-end: Gradient-isolated learning of representations.” arXiv preprint arXiv:1905.11786 (2019).
-
Tian, Yonglong, Dilip Krishnan, and Phillip Isola. “Contrastive representation distillation.” arXiv preprint arXiv:1910.10699 (2019).
-
Missed structural knowledge of the teacher network!!
- Cross modal distillation!!
- KD -all dimension are independent (intro 1.2)
- Capture the correlation/higher-order dependencies in the representation (how??).
- Maximize MI between teacher and student.
- KD -all dimension are independent (intro 1.2)
-
Three scenario considered [fig 1]
-
KD and representation learning connection (!!)
-
large temperature increases entropy [look into the equation! easy-pesy]
-
interesting proof and section 3.1 [great!]
-
Student takes query - matches with positive keys from teacher and contrast with negative keys from the teacher network.
-
Equation 20 is cross entropy (stupid notation)
-
Key contribution: New loss function: 3.4 eq21
-
-
Saunshi, Nikunj, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khandeparkar. “A theoretical analysis of contrastive unsupervised representation learning.” In International Conference on Machine Learning, pp. 5628-5637. 2019.
- present a framework for analyzing CL (is there any previous?) - introduce latent class!! shows generalization bound. - Unsupervised representation learning - TP: notion of latent classes (downstream tasks are subset of latent classes), rademacher complexity of the architecture! (limitation of negative sampling), extension! - CL gives representation learning with plentiful labeled data! TP asks this question. - Theoretical results to include in the works. - <embed src="https://mxahan.github.io/PDF_files/theory_cl.pdf" width="100%" height="850px"/> -
Anand, Ankesh, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, and R. Devon Hjelm. “Unsupervised state representation learning in atari.” arXiv preprint arXiv:1906.08226 (2019).
-
Kolesnikov, Alexander, Xiaohua Zhai, and Lucas Beyer. “Revisiting self-supervised visual representation learning.” In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1920-1929. 2019.
-
Insight about the network used for learning [experimentation]
-
Challenges the choice of different CNNs as network for vision tasks.
-
Experimentation with different architectures [ResNet, RevNet, VGG] and their widths and depths.
-
key findings : hat (1) lessons from architecture design in the fully supervised setting do not necessarily translate to the self-supervised setting; (2) contrary to previously popular architectures like AlexNet, in residual architectures, the final prelogits layer consistently results in the best performance; (3) the widening factor of CNNs has a drastic effect on performance of self-supervised techniques and (4) SGD training of linear logistic regression may require very long time to converge
-
pretext tasks for self-supervised learning should not be considered in isolation, but in conjunction with underlying architectures.
-
-
Hendrycks, Dan, Mantas Mazeika, Saurav Kadavath, and Dawn Song. “Using self-supervised learning can improve model robustness and uncertainty.” arXiv preprint arXiv:1906.12340 (2019).
- TP: self-supervision can benefit robustness in a variety of ways, including robustness to adversarial examples, label corruption, and common input corruptions (how is this new!!)
- Interesting problem and experiment setup for each of the problems
- Besides a collection of techniques allowing models to catch up to full supervision, SSL is used two in conjunction of providing strong regularization that improves robustness and uncertainty estimation
- TP: self-supervision can benefit robustness in a variety of ways, including robustness to adversarial examples, label corruption, and common input corruptions (how is this new!!)
2020
-
Zhan, X., Xie, J., Liu, Z., Ong, Y. S., & Loy, C. C. (2020). Online deep clustering for unsupervised representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6688-6697).
- RG: training schedule alternating between feature clustering and network update leads to unstable representations learning.
- propose Online Deep Clustering (ODC) that performs clustering and network update simultaneously rather than alternatingly??
- insight : the cluster centroids should evolve steadily in keeping the classifier stably updated
- design and maintain two dynamic memory modules (i) samples memory to store samples’ labels and features, (ii) centroids memory for centroids evolution
- break down the abrupt global clustering into steady memory update and batchwise label re-assignment. The process is integrated into network update iterations.
-
Wei, C., Wang, H., Shen, W., & Yuille, A. (2020). Co2: Consistent contrast for unsupervised visual representation learning. arXiv preprint arXiv:2010.02217.
- introduces a consistency regularization term into the current contrastive learning framework.
- addressing the problem of treating all as equal negatives (class collision problem)
- Figure 1 (b) summarizes the method.
- Equation 2,3,4 (very easy idea)
- takes the corresponding similarity of a positive crop as a pseudo label, and encourages consistency between these two similarities
- view this instance discrimination task from the perspective of semi-supervised learning.
- introduces a consistency regularization term into the current contrastive learning framework.
-
Cai, T. T., Frankle, J., Schwab, D. J., & Morcos, A. S. (2020). Are all negatives created equal in contrastive instance discrimination?. arXiv preprint arXiv:2010.06682.
- divided negatives by their difficulty for a given query
- studied which difficulty ranges were most important for learning useful representations (how?)
-
a small minority of negatives (hardest 5%—were) both necessary and sufficient for the downstream task to reach full accuracy
-
The hardest 0.1% of negatives are unnecessary and sometimes detrimental
-
Hypothesis: there may be unexploited opportunities to reduce CID computation for any particular query, only a small fraction of the negatives are necessary
- To compute the difficulty for a set of negatives given a particular query, the dot product between the normalized contrastive-space embedding of each negative with the normalized contrastive-space embedding of the query
- Hard negatives are more semantically similar to the query
- Some of the easiest negatives are both anti-correlated (dot prod -1) and semantically similar to the query
- only issue for cosine distance.
- Some negatives are consistently easy or hard across queries.
- Some of the easiest negatives are both anti-correlated (dot prod -1) and semantically similar to the query
- Hard negatives are more semantically similar to the query
- divided negatives by their difficulty for a given query
-
Sohoni, Nimit, Jared Dunnmon, Geoffrey Angus, Albert Gu, and Christopher Ré. “No subclass left behind: Fine-grained robustness in coarse-grained classification problems.” Advances in Neural Information Processing Systems 33 (2020): 19339-19352.
- Hidden stratification: unavailable subclass labels
- TP: GEORGE, a method to both measure and mitigate hidden stratification even when subclass labels are unknown.
- TP: estimate subclass labels for the training data via clustering techniques (Estimation)
- use these approximate subclass labels as a form of noisy supervision in a distributionally robust optimization objective (exploiting)
- TP: GEORGE, a method to both measure and mitigate hidden stratification even when subclass labels are unknown.
-
Paper construction: generative background for data labeling process [figure 2]
-
Reason of hidden stratification: Inherent hardness and Dataset imbalance
-
Method overview [figure 4]: includes two step training (i. training with classification, dimentional reduction of last layer and ii. fine tune.)
- Hidden stratification: unavailable subclass labels
-
Patacchiola, Massimiliano, and Amos Storkey. “Self-supervised relational reasoning for representation learning.” arXiv preprint arXiv:2006.05849 (2020).
- Relation network head instead of direct contrastivie loss [architectural][Pretext task design]
- differentiate from previous one in several ways:
- (i) TP use relational reasoning on unlabeled data (previously on unlabeled data);
- (ii) here TP focus on relations between different views of the same object (intra-reasoning) and between different objects in different scenes (inter-reasoning); [previously withing scene]
- (iii) in previous work training the relation head was the main goal, here is a pretext task for learning useful representations in the underlying backbone
- differentiate from previous one in several ways:
- Related works: pretext task, metric learning, CL, pseudo labeling, InfoMax,
-
Intra-inter reasoning increases mutual information.
- Easy-pesy loss functions to minimize (care about the sharping of the weight of the loss function!)
- Relation network head instead of direct contrastivie loss [architectural][Pretext task design]
-
Huang, Zhenyu, Peng Hu, Joey Tianyi Zhou, Jiancheng Lv, and Xi Peng. “Partially view-aligned clustering.” Advances in Neural Information Processing Systems 33 (2020).
-
Zhu, Benjin, Junqiang Huang, Zeming Li, Xiangyu Zhang, and Jian Sun. “EqCo: Equivalent Rules for Self-supervised Contrastive Learning.” arXiv preprint arXiv:2010.01929 (2020).
- Theoretical paper: Challenges the large number of negative samples [algorithmic]
- Though more negative pairs are usually reported to derive better results, Interpretation: it may be because the hyper-parameters in the loss are not set to the optimum according to different numbers of keys respectively
- Rule to set the hyperparameters
-
SiMo: Alternate for the InfoNCE
- EqCo: Concept of Batch Size (N) and Negative Sample number (K)
- CPC work follow-up
- the learning rate should be adjusted proportional to the number of queries N per batch
- linear scaling rule needs to be applied corresponding to N rather than K
- EqCo: Concept of Batch Size (N) and Negative Sample number (K)
-
SiMo: cancel the memory bank as rely on a few negative samples per batch. Instead, use the momentum encoder to extract both positive and negative key embeddings from the current batch.
- Theoretical paper: Challenges the large number of negative samples [algorithmic]
-
Miech, Antoine, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. “End-to-end learning of visual representations from uncurated instructional videos.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9879-9889. 2020.
-
Experiments with Dataset: HowTo100M (task progression) [video with narration]
-
This paper: (multi-instance learning) MIL-NCE (to address misalignment in video narration)!! HOW? Requires instructional videos! (video with text)
-
Video representation learning: shows effectiveness in four downstream tasks: AR (HMDB, UCF, Kinetics), action localization (Youtube8M, crosstask), action segmentation (COIN), Text-to-video retrieval (YouCook2, MSR-VTT).
-
TP: Learn video representation from narration only (instructional video)!
-
Related works: Learning visual representation from unlabeled videos. (ii) Multiple instance learning for video understanding (MIL) [TP: connect MCE with MIL]
-
Two networks in the NCE Calculation : [unstable targets!!]
-
Experiments: Network: 3D CNN
-
-
Xie, Zhenda, Yutong Lin, Zheng Zhang, Yue Cao, Stephen Lin, and Han Hu. “Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning.” arXiv preprint arXiv:2011.10043 (2020).
- Argue that instance level CL reaches suboptimal representation!
- Can we go better.
- Alternative to instance-level pretext learning - Pixel-level pretext learning!
- Pixel level pretext learning! pixel to propagation consistency!!
- Avail both backbone and head network! to reuse
- complementary to instance level CL
- How to define pixel level pretext tasks!
- Why instance-label is sub-optimal? How? Benchmarking!
- Dense feature learning
- Pixel level pretext learning! pixel to propagation consistency!!
- Application: Object detection (Pascal VOC object detection), semantic segmentation
- Pixel level pretext tasks
- Each pixel is a class!! what!!
- Features from same pixels are same !
- PixContrast: Training data collected in self-supervised manner
- requires pixel feature vector !
- Feature map is warped into the original image space
- Now closer pictures together and …. contrastive setup
- Learns spatially sensitive information
- Each pixel is a class!! what!!
- Pixel level pretext tasks
- Pixel-to-propagation consistency !! (pixpro)
- positive pair obtaining methods
- asymmetric pipeline
- Learns spatial smoothness information
- Pixel propagation module
- pixel to propagation consisency loss
- PPM block (Equation: 3,4): Figure 3
- Argue that instance level CL reaches suboptimal representation!
-
Piergiovanni, A. J., Anelia Angelova, and Michael S. Ryoo. “Evolving losses for unsupervised video representation learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 133-142. 2020.
- video representation learning! (generic and transfer) (ELo)
- Video object detection
- Zeroshot and fewshot AcRecog
- introduce concept of loss function evolving (automatically find optimal combination of loss functions capturing many (self-supervised) tasks and modalities)
- using an evolutionary search algorithm (!!)
- introduce concept of loss function evolving (automatically find optimal combination of loss functions capturing many (self-supervised) tasks and modalities)
-
Evaluation using distribution matching and Zipf’s law!
-
only outperformed by fully labeled dataset
- This paper: new unsupervised learning of video representations from unlabeled video data.
- multimodal, multitask, unsupervised learning
- Youtube dataset
- combination of single modal tasks and multi-modal tasks
- too much task! how they combined it!! Engineering problem
- evolutionary algorithm to solve these puzzle
- Power law constraints and KL divergence
- Evolutionary search for a loss function that automatically combines self-supervised and distillation task
- unsupervised representation evaluation metric based on power law distribution matching
- multimodal, multitask, unsupervised learning
- Multimodal task, multimodal distillation
- show their efficacy by the power distribution of video classes (zipf’s law)
- Figure 2:
- overwhelming of tasks! what if no commonalities.
- Hypo: Synchronized multi-modal data source should benefit representation learning
- Distillation losses between the multiple streams of networks + self supervised loss
- Methods
- Multimodal learning
- Evolving an unsupervised loss function
- [0-1] constraints
- zipfs distribution matching
- Fitness measurement - k-means clustering
- use smaller subset of data for representation learning
- Cluster the learned representations
- the activity classes of videos follow a Zipf distribution
- HMDB, AVA, Kinetics dataset, UCF101
- ELo methods with baseline weakly-supervised methods
- Self-supervised learning
- reconstruction (encoder-decoder) and prediction tasks (L2 distance minimization)
- Temporal ordering
- Multi-modal contrastive loss {maxmargin loss}
- ELo and ELo+Distillation
- This paper: new unsupervised learning of video representations from unlabeled video data.
-
- video representation learning! (generic and transfer) (ELo)
-
Chen, Ting, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. “Big self-supervised models are strong semi-supervised learners.” arXiv preprint arXiv:2006.10029 (2020).
-
Empirical paper
- unsupervised pretrain (task agnostic), semi-supervised learning (task dependent), fine-tuning
- Impact of Big (wide and deep) network
- More benefited from the unsupervised pretraining
- Big Network: Good for learning all the Representations
- Not necessarily require in one particular task - So we can leave the unnecessary information
- More improve by distillation after fine tuneing
- Impact of Big (wide and deep) network
-
Wow: Maximum use of works: Big network to learn representations, and fine-tune then distill the task (supervised and task specific fine-tune) to a smaller network
- Proposed Methods (3 steps) [this paper]
- Unsupervised pretraining (SimCLR v2)
- Supervised fine-tune using smaller labeled data
- Distilling with unlabeled examples from big network for transferring task-specific knowledge into smaller network
- This paper:
- Investigate unsupervised pretraining and selfsupervised fine-tune
- Finds: network size is important
- Propose to use big unsupervised_pretraining-fine-tuning network to distill the task-specific knowledge to small network.
- Figure 3 says all
- Investigate unsupervised pretraining and selfsupervised fine-tune
- Key contribution
- Big networks works best (in unsupervised pretraining - very few data fine-tune) althought they may overfit!!!
- Big model learns general representations, may not necessary when task-specific requirement
- Importance of multilayer transform head (intuitive because of the transfer properties!! great: since we are going away from metric dimension projection, so more general features)
-
Section 2: Methods (details from loss to implementation)
- Empirical study findings
- Bigger model are label efficient
- Bigger/Deeper Projection Heads Improve Representation Learning
- Distillation using unlabeled data improves semi-supervised learning
- Bigger model are label efficient
-
-
Gordon, Daniel, Kiana Ehsani, Dieter Fox, and Ali Farhadi. “Watching the world go by: Representation learning from unlabeled videos.” arXiv preprint arXiv:2003.07990 (2020).
- Multi-frame multi-pairs positive negative (single imgae)- instance discrimination
-
Tao, Li, Xueting Wang, and Toshihiko Yamasaki. “Self-supervised video representation learning using inter-intra contrastive framework.” In Proceedings of the 28th ACM International Conference on Multimedia, pp. 2193-2201. 2020.
-
Notion of intra-positive (augmentation, optical flow, frame differences, color of same frames)
-
Notion of intra-negative (frame shuffling, repeating)
-
Inter negative (irrelevant video clips - Different time or videos)
-
Two (Multi) Views (same time - positive keys) - and intra-negative
-
Figure 2 (memory bank approach)
-
Consider contrastive from both views.
-
-
Chen, Ting, and Lala Li. “Intriguing Properties of Contrastive Losses.” arXiv preprint arXiv:2011.02803 (2020).
- Generalize the CL loss to broader family of losses
- weighted sum of alignment and distribution loss
- Alignment: align under some transformation
- Distribution: Match a prior distribution
- weighted sum of alignment and distribution loss
- Experiment with weights, temperature, and multihead projection
- Study feature suppression!! (competing features)
- Impacts of final loss!
- Impacts of data augmentation
- Study feature suppression!! (competing features)
-
Suppression feature phenomena: Reduce unimportant features
- Experiments
- two ways to construct data
- Expand beyond the uniform hyperspace prior
- Can’t rely on logSumExp setting in NT-Xent loss
- Requires new optimization (Sliced Wasserstein distance loss)
- Algorithm 1
- Impacts of temperature and loss weights
- Feature suppression
- Target: Remove easy-to-learn but less transferable features for CL (e.g. Color distribution)
- Experiments by creating the dataset
- Digit on imagenet dataset
- RandBit dataset
- Experiments
- Generalize the CL loss to broader family of losses
-
Xiao, Tete, Xiaolong Wang, Alexei A. Efros, and Trevor Darrell. “What should not be contrastive in contrastive learning.” arXiv preprint arXiv:2008.05659 (2020).
- What if downstream tasks violates data augmentation (invariance) assumption!
- Requires prior knowledge of the final tasks
- This paper: Task-independent invariance
- Requires separate embedding spaces! (how much computation increases, redundant!)
- Surely, multihead networks and shared backbones
- new idea: Invariance to all but one augmentation !!
- Surely, multihead networks and shared backbones
- Requires separate embedding spaces! (how much computation increases, redundant!)
-
Pretext tasks: Tries to recover transformation between views
-
Contrastive learning: learn the invariant of the transformations
- Is augmentation helpful: Not always!
- rotation invariance removes the orientation senses! Why not keep both! disentanglement and the multitask!
- This paper: Multi embedding space (transfer the shared backbones and task specific heads)
- Each head is sensitive to all but one transformations
- LooC: (Leave-one-out Contrastive Learning)
- Multi augmentation contrastive learning
- view generation and embedded space
- Figure 2 (crack of jack)
- Good setup to apply the ranking loss function
- Careful with the notation (bad notation)
- instances and their augmentations!
- Is augmentation helpful: Not always!
- What if downstream tasks violates data augmentation (invariance) assumption!
-
Tschannen, Michael, Josip Djolonga, Marvin Ritter, Aravindh Mahendran, Neil Houlsby, Sylvain Gelly, and Mario Lucic. “Self-supervised learning of video-induced visual invariances.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13806-13815. 2020.
- Framework to learn image representations from non-curated videos in the wild by learning frame-, shot-, and video-level invariances
- benefit greatly from exploiting video-induced invariances,
-
Experiment with Youtube8M (3.7 M
- Scale-able to image and video data. (however requires frame label encoding!! what about video AR networks)
- Framework to learn image representations from non-curated videos in the wild by learning frame-, shot-, and video-level invariances
-
Ma, Shuang, Zhaoyang Zeng, Daniel McDuff, and Yale Song. “Learning Audio-Visual Representations with Active Contrastive Coding.” arXiv preprint arXiv:2009.09805 (2020).
-
Tao, Li, Xueting Wang, and Toshihiko Yamasaki. “Self-Supervised Video Representation Using Pretext-Contrastive Learning.” arXiv preprint arXiv:2010.15464 (2020).
-
Tasks and Contrastive setup connection (PCL)
-
hypersphere features spaces
-
Combine Pretext(some tasks, intra information)+Contrastive (similar/dissimilarity, inter-information) losses
-
Assumption: pretext and contrastive learning doing the same representation.
-
Loss function (Eq-6): Contrast (same body +head1)+pretext task (same body + head2)! - Joint optimization
-
Figure 1- tells the story
-
Three pretext tasks (3DRotNet, VCOP, VCP) - Experiment section
-
Both RGB and Frame difference
-
Downstrem tasks (UCF and HMDB51)
-
Some drawbacks at the discussion section.
-
-
-
Li, Junnan, Pan Zhou, Caiming Xiong, Richard Socher, and Steven CH Hoi. “Prototypical contrastive learning of unsupervised representations.” arXiv preprint arXiv:2005.04966 (2020).
- Addresses the issues of instance wise learning (?)
- issue 1: semantic structure missing
- claims to do two things
- Learn low-level features for instance discrimination
- encode semantic structure of the data
- prototypes as latent variables to help find the maximum-likelihood estimation of the network parameters in an Expectation-Maximization framework.
- E-step as finding the distribution of prototypes via clustering
- M-step as optimizing the network via contrastive learning
-
Offers new loss function ProtoNCE (Generalized InfoNCE)
- Show performance for the unsupervised representation learning benchmarking (?) and low-resolution transfer tasks
- Prototype: a representative embedding for a group of semantically similar instances
- prototype finding by standard clustering methods
- Prototype: a representative embedding for a group of semantically similar instances
-
Goal described in figure 1
- EM problem?
- goal is to find the parameters of a Deep Neural Network (DNN) that best describes the data distribution, by iteratively approximating and maximizing the log-likelihood function.
- assumption that the data distribution around each prototype is isotropic Gaussian
-
Related works: MoCo, Deep unsupervised Clustering: not transferable?
- Prototypical Contrastive Learning (PCL)
- See the math notes from section 3
- EM problem?
-
Figure 2 - Overview of methods
- Addresses the issues of instance wise learning (?)
-
Caron, Mathilde, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. “Unsupervised learning of visual features by contrasting cluster assignments.” arXiv preprint arXiv:2006.09882 (2020).
- SwAV (online algorithm) [swapped assignments between multiple vies of same image]
-
Contrastive learning, clustering
-
Predict cluster from different representation, memory efficiency!
- ‘code’ consistency between image and its transformation {target}
- similarity is formulated as a swapped prediction problem between positive pairs
- no negative examples
- the minibatch clustering methods implicitly prevent collapse of the representation space by encouraging samples in a batch to be distributed evenly to different clusters.
-
online code computation
-
Features and codes are learnt online
-
multi-crop: Smaller image with multiple views: Efficient calculation
-
validation: ImageNet linear evaluation protocol
-
Interested related work section
-
Key motivation: Contrastive instance learning
-
Partition constraint (batch wise normalization) to avoid trivial solution
-
Chen, Xinlei, and Kaiming He. “Exploring Simple Siamese Representation Learning.” arXiv preprint arXiv:2011.10566 (2020).
-
Not using Negative samples, large batch or Momentum encoder!!
-
Care about Prevention of collapsing to constant (one way is contrastive learning, another way - Clustering, or online clustering, BYOL)
-
Concepts in figure 1 (SimSiam method)
-
Stop collapsing by introducing the stop gradient operation.
- interesting section in 3
- Loss SimCLR (but differently ) [eq 1 and eq 2]
- Detailed Eq 3 and eq 4
- Empirically shown to avoid the trivial solution
- interesting section in 3
-
-
Morgado, Pedro, Nuno Vasconcelos, and Ishan Misra. “Audio-visual instance discrimination with cross-modal agreement.” arXiv preprint arXiv:2004.12943 (2020).
- learning audio and video representation [audio to video and video to audio!]
- How they showed its better??
- Exploit cross-modal agreement [what setup!] how it make sense!
-
consider in-sync audio video, proposed AVID (au-visu-instan-discrim)
- Experiments with UCF-101, HMDB-51
- Discussed limitation AVID & proposed improvement
- Optimization method - [dimentional reduction by LeCunn and NCE paper]
- Training procedure in section 3.2 AVID
- Cross modal agreement!! it groups (how?) similar videos [both audio and visual]
- Optimization method - [dimentional reduction by LeCunn and NCE paper]
- Discussed limitation AVID & proposed improvement
- Prior arts - binary task of audio-video alignment instance-based
- This paper: matches in the representation embedding domain.
-
AVID calibrated by formulating CMA??
- Figure 2: Variant of avids [summary of the papers]
- This people are first to do it!!
- Joint and Self AVID are bad in result! Cross AVID is the best for generalization in results!
- CMA - Extension of the AVID [used for fine tuning]
- section 4: Loss function extension with cross- AVID and why we need this?
- Figure 2: Variant of avids [summary of the papers]
- learning audio and video representation [audio to video and video to audio!]
-
Robinson, Joshua, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. “Contrastive Learning with Hard Negative Samples.” arXiv preprint arXiv:2010.04592 (2020).
- Sample good negative (difficult to distinguish) leads better represenation
- challenges: No label! unsupervised method! Control the hardness!
- enables learning with fewest instances and distance maximization.
-
Problem (1): what is true label? sol: Positive unlabeled learning !!!
-
Problem (2): Efficient sampling? sol: efficient importance sampling!!! (consider lack of dissimilarity information)!!!
-
Section 3 most important!
- section 4 interesting
- Sample good negative (difficult to distinguish) leads better represenation
-
Chuang, Ching-Yao, Joshua Robinson, Yen-Chen Lin, Antonio Torralba, and Stefanie Jegelka. “Debiased contrastive learning.” Advances in Neural Information Processing Systems 33 (2020).
-
Sample bias [negatives are actually positive! since randomly sampled]
-
need unbiased - improves vision, NLP and reinforcement tasks.
-
Related to Positive unlabeled learning
-
interesting results
-
-
Zhao, Nanxuan, Zhirong Wu, Rynson WH Lau, and Stephen Lin. “What makes instance discrimination good for transfer learning?.” arXiv preprint arXiv:2006.06606 (2020).
-
Metzger, Sean, Aravind Srinivas, Trevor Darrell, and Kurt Keutzer. “Evaluating Self-Supervised Pretraining Without Using Labels.” arXiv preprint arXiv:2009.07724 (2020).
-
Bhardwaj, Sangnie, Ian Fischer, Johannes Ballé, and Troy Chinen. “An Unsupervised Information-Theoretic Perceptual Quality Metric.” Advances in Neural Information Processing Systems 33 (2020).
-
Qian, Rui, Tianjian Meng, Boqing Gong, Ming-Hsuan Yang, Huisheng Wang, Serge Belongie, and Yin Cui. “Spatiotemporal contrastive video representation learning.” arXiv preprint arXiv:2008.03800 (2020).
-
unlabeled videos! video representation, pretext task! (CVRL)
-
simple idea: same video together and different videos differ in embedding space. (TCN works on same video)
-
Video SimCLR?
-
Inter video clips (positive negatives)
- method
- Simclr setup for video (InfoNCE loss)
- Video encoder (3D resnets)
- Temporal augmentation for same video (good for them but not Ubiquitous)
- Image based spatial augmentation (positive)
- Different video (negative)
- Downstream Tasks
- Action Classification
- Action Detection
- method
-
-
Wang, Tongzhou, and Phillip Isola. “Understanding contrastive representation learning through alignment and uniformity on the hypersphere.” In International Conference on Machine Learning, pp. 9929-9939. PMLR, 2020.
- How to contraint on these and they perform better? weighted loss
- Alignment (how close the positive features) [Epos[f(x)-f(y)]2]
- Uniformly [take all spaces in the hyperplane] [little complex but tangible 4.1.2]
- l_uniform loss definition [!!]
- Interpretation of 4.2 see our future paper !!
- cluster need to form spherical cap
- Theoretical metric for above two constraints??
- Congruous with CL
- gaussing RBF kernel e^{[f(x) -f(y)]^2} helps on uniform distribution achieving.
- Theoretical metric for above two constraints??
- Result figure-7 [interesting]
- Alignment and uniform loss
- How to contraint on these and they perform better? weighted loss
-
Xiong, Yuwen, Mengye Ren, and Raquel Urtasun. “LoCo: Local contrastive representation learning.” arXiv preprint arXiv:2008.01342 (2020).
-
Kalantidis, Yannis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. “Hard negative mixing for contrastive learning.” arXiv preprint arXiv:2010.01028 (2020).
-
TP (MoCHi): The effect of Hard negatives (how, definition?)
-
TP: feature level mixing for hard negatives (minimal computational overhead, momentum encoder) by synthesizing hard negatives (!!)
-
Related works: Mixup workshop
-
-
Grill, Jean-Bastien, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch et al. “Bootstrap your own latent: A new approach to self-supervised learning.” arXiv preprint arXiv:2006.07733 (2020).
-
Unsupervised Representation learning in a discriminative method. (BOYL)
-
Alternative of contrastive learning methods (as CL depends on batch size, image augmentation method, memory bank, resilient). [No negative examples]
-
Online and Target network. [Augmented image output in online network should be close to main image in target network.] What about all zeros! (Empirically slow moving average helps to avoid that)
-
Motivation [section 3 method]
-
similarity constraint between positive keys are also enforced through a prediction problem from an online network to an offline momentum-updated network
- BYOL tries to match the prediction from an online network to a randomly initialised offline network. This iterations lead to better representation than those of the random offline network.
- By continually improving the offline network through the momentum update, the quality of the representation is bootstrapped from just the random initialised network
-
All about architecture! [encoder, projection, predictor and loss function]
-
Works only with batch normalization - else mode collapse
- More criticism
-
-
Qi, Di, Lin Su, Jia Song, Edward Cui, Taroon Bharti, and Arun Sacheti. “Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data.” arXiv preprint arXiv:2001.07966 (2020).
-
vision pre-training /cross modal pretraining
-
New data collection (LAIT)
- pretraining (see the loss functions)
- Image/text from same context? (ITM)
- Missing pixel detection?
- Masked object Classification (MOC)
- Masked region feature regression (MRFR)
- Masked Language Models
- Fine tune Tasks
- Binary classification losses
- Multi-class classification losses
- Triplet loss
- pretraining (see the loss functions)
-
Multistage pretraining
- Experimented with VQA and others. image language
-
-
Purushwalkam, Senthil, and Abhinav Gupta. “demystifying contrastive self-supervised learning: Invariances, augmentations and dataset biases.” arXiv preprint arXiv:2007.13916 (2020).
- object detection and classification
- quantitative experiment to Demystify CL gains! (reason behind success)
- Observation1: MOCO and PIRL (occlusion invariant)
- but Fails to capture viewpoint
- gain from object-centric dataset - imagenet!
- Propose methods to leverage learn from unstructured video (viewpoint invariant)
- Observation1: MOCO and PIRL (occlusion invariant)
- quantitative experiment to Demystify CL gains! (reason behind success)
-
Utility of systems: How much invarinces the system encodes
-
most contrastive setup - occlusion invariant! what about viewpoint invariant?
- Related works
- Pretext tasks
- Video SSL
- Understanding SSRL
- Mutual information
- This work - Why CL is useful
- study two aspects: (invariances encoding & role of dataset)
- Pretext tasks
- Demystifying Contrastive SSL
- what is good Representation? Utilitarian analysis: how good the downstream task is?
- What about the insights? and qualitative analysis?
- Measuring Invariances
- What invariance do we need? - invariant to all transformation!!
- Viewpoint change, deformation, illumination, occlusion, category instance
- Metrics: Firing representation, global firing rate, local firing rate, target conditioned invariance, representation invariant score.
- Experimental dataset
- occlusion (GOR-10K), viewpoint+instance invariance (Pascal3D+)
- image and video careful augmentation
- What invariance do we need? - invariant to all transformation!!
- what is good Representation? Utilitarian analysis: how good the downstream task is?
-
- object detection and classification
-
Ermolov, Aleksandr, Aliaksandr Siarohin, Enver Sangineto, and Nicu Sebe. “Whitening for self-supervised representation learning.” arXiv preprint arXiv:2007.06346 (2020).
- New loss function (why? and where it works?) W-MSE
- Generalization of the BYOL approach?
- No negative examples (the scatters are preserved)
- Whitening feature is the key: Cholesky decomposition to find Whitening matrix and Backprogation
- Triangular decomposition of covariance matrix and inversing.
-
Whitening operation (scattering effect)
- New loss function (why? and where it works?) W-MSE
-
Ebbers, Janek, Michael Kuhlmann, and Reinhold Haeb-Umbach. “Adversarial Contrastive Predictive Coding for Unsupervised Learning of Disentangled Representations.” arXiv preprint arXiv:2005.12963 (2020).
-
video deep infomax: UCF101 dataset
-
Local and global features:
-
self note: go over this
-
-
Devon, R. “Representation Learning with Video Deep InfoMax.” arXiv preprint arXiv:2007.13278 (2020).
- DIM: prediction tasks between local and global features.
- For video (playing with sampling rate of the views)
- DIM: prediction tasks between local and global features.
-
Liang, Weixin, James Zou, and Zhou Yu. “Alice: Active learning with contrastive natural language explanations.” arXiv preprint arXiv:2009.10259 (2020).
-
Contrastive natural language!!
-
Experiments - (bird classification and Social relationship classifier!!)
- key steps
- run basic Classifier
- fit multivariate gaussian for all class (embedding!!), and find b pair of classes with lowest JS divergence.
- contrastive query to machine understandable form (important and critical part!!). [crop the most informative parts and retrain.]
- neural arch. morphing!! (heuristic and interesting parts) [local, super classifier and attention mechanism!]
- key steps
-
-
Ma, Shuang, Zhaoyang Zeng, Daniel McDuff, and Yale Song. “Learning Audio-Visual Representations with Active Contrastive Coding.” arXiv preprint arXiv:2009.09805 (2020).
-
Park, Taesung, Alexei A. Efros, Richard Zhang, and Jun-Yan Zhu. “Contrastive Learning for Unpaired Image-to-Image Translation.” arXiv preprint arXiv:2007.15651 (2020).
-
Contrastive loss (Same patch of input - output are +ve and rest of the patches are -ve example) [algorithmic]
-
Trains the encoder parts more! (Fig 1, 2) ; Decoders train only on adversarial losses.
-
Contribution in loss (SimCLR) kinda motivation
-
-
Guo, Daniel, Bernardo Avila Pires, Bilal Piot, Jean-bastien Grill, Florent Altché, Rémi Munos, and Mohammad Gheshlaghi Azar. “Bootstrap Latent-Predictive Representations for Multitask Reinforcement Learning.” arXiv preprint arXiv:2004.14646 (2020).
-
Notation Caution. Representation learning [latent space for observe and history]
-
States to future latent observation to future state.
-
Latent embedding of history.
-
Alternative for Deep RL
- Experiments
- DMLab-30
- Compared for PopArt-IMPALA (RNN) with DRAW, Pixel-control, Contrastive predictive control.
- DMLab-30
-
Partially observable environments and Predictive representation.
-
Learn agent state by predictive representation.
-
RNN compresses history from the observations and actions; History as input for new decision making
- Interesting section 3!
-
-
Tian, Yonglong, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. “What makes for good views for contrastive learning.” arXiv preprint arXiv:2005.10243 (2020).
-
Multi-view in-variance
-
What is invariant?? (shared information between views)
-
balance to share the information we need in view!!
- Questions
- Knowing task what will be the view??!
- generate views to control the MI
-
Maximize task related shared information, minimize nuisance variables. (InfoMin principle)
-
Contributions (4 - method, representation and task-dependencies, ImageNet experimentation)
- Figure 1: summary.
- Optimal view encoder.
- Sufficient (careful notation overloaded! all info there), minimal sufficient (someinfo dropped), optimal representation (4.3)- only task specific information retrieved
- Optimal view encoder.
- InfoMin Principle: views should have different background noise else min encoder reduces the nuisance variable info. (proposition 4.1 with constraints.)
-
suggestion: Make contrastive learning hard
-
Figure 2: interesting. [experiment - 4.2]
-
Figure 3: U-shape MI curve.
-
section 6: different views and info sharing.
-
-
-
Lu, Jiasen, Vedanuj Goswami, Marcus Rohrbach, Devi Parikh, and Stefan Lee. “12-in-1: Multi-task vision and language representation learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10437-10446. 2020.
-
MTL + Dynamic “stop and go” schedule. [multi-modal representation learning]
-
ViLBERT base architecture.
-
-
Misra, Ishan, and Laurens van der Maaten. “Self-supervised learning of pretext-invariant representations.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6707-6717. 2020.
-
Pre-training method [algorithmic]
-
Pretext learning with transformation invariant + data augmentation invariant
- See the loss functions
- Tries to retain small amount of the transformation properties too !!
- Use contrastive learning (See NCE)
- Maximize MI
- Utilizes extra head on the features.
- See the loss functions
-
Motivation from predicting video frames
-
Experiment of jigsaw pretext learning
- Hypothesis: Representation of image and its transformation should be same
- Use different head for image and jigsaw counterpart of that particular image.
- Motivation for learning some extra things by different head network
- Use different head for image and jigsaw counterpart of that particular image.
-
Noise Contrastive learning (contrast with other images)
-
As two head so two component of contrastive loss. (One component to dampen memory update.)
-
Implemented on ResNet
-
PIRL
-
-
-
Srinivas, Aravind, Michael Laskin, and Pieter Abbeel. “Curl: Contrastive unsupervised representations for reinforcement learning.” arXiv preprint arXiv:2004.04136 (2020).
-
Chen, Ting, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. “A simple framework for contrastive learning of visual representations.” arXiv preprint arXiv:2002.05709 (2020).
-
Truely simple! (SimCLR) [algorithmic]
-
Two transfers for each image and representation
-
Same origin image should be more similar than the others.
-
Contrastive (negative) examples are from image other than that.
-
A nonlinear projection head followed by the representation helps.
-
-
Asano, Yuki M., Mandela Patrick, Christian Rupprecht, and Andrea Vedaldi. “Labelling unlabelled videos from scratch with multi-modal self-supervision.” arXiv preprint arXiv:2006.13662 (2020).
-
clustering method that allows pseudo-labelling of a video dataset without any human annotations, by leveraging the natural correspondence between the audio and visual modalities
-
[Multi-Modal representation learning]
-
-
Patrick, Mandela, Yuki M. Asano, Ruth Fong, João F. Henriques, Geoffrey Zweig, and Andrea Vedaldi. “Multi-modal self-supervision from generalized data transformations.” arXiv preprint arXiv:2003.04298 (2020).
- [Multi-Modal representation learning]
-
Khosla, Prannay, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. “Supervised contrastive learning.” arXiv preprint arXiv:2004.11362 (2020).
- [Algorithmic]
-
He, Kaiming, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. “Momentum contrast for unsupervised visual representation learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729-9738. 2020.
-
Dynamic dictionary with MA encoder [Algorithmic] Contribution
-
(query) encoder and (key) momentum encoder.
- The update of key encoder in a momentum fashion
- Query updated by back propagation
-
Algorithm [1] is the Core: A combination of end-end & the Memory bank
-
key and query match but the queue would not match!
- Momentum parametric dependencies - Start with the key and query encoder as the Same - key updates slowly, query updates with SGD.
-
-
Huynh, Tri, Simon Kornblith, Matthew R. Walter, Michael Maire, and Maryam Khademi. “Boosting Contrastive Self-Supervised Learning with False Negative Cancellation.” arXiv preprint arXiv:2011.11765 (2020).
- False negative Problem!! (detail analysis) [sampling method for CL]
- Aim: Boosting results
-
Methods to Mitigate false negative impacts (how? what? how much impact! significant means?? what are other methods?)
-
Hypothesis: Randomly taken negative samples (leaked negative)
- Overview
- identify false negative (how?): Finding potential False negative sample [3.2.3]
- Then false negative elimination and false negative attraction
- Contributions
- applicable on top of existing cont. learning
- Overview
- False negative Problem!! (detail analysis) [sampling method for CL]
-
Lee, Jason D., Qi Lei, Nikunj Saunshi, and Jiacheng Zhuo. “Predicting what you already know helps: Provable self-supervised learning.” arXiv preprint arXiv:2008.01064 (2020).
- Highly theoretical paper.
- TP: is to investigate the statistical connections between the random variables of input features and downstream labels
- Two important notion for the tasks: i) Expressivity (does the ssl good enough) ii) Sample complexity (reduce the complexity of sampling)
- TP: is to investigate the statistical connections between the random variables of input features and downstream labels
- TP: analysis on the reconstruction based SSL
-
section 3 describes the paper summary. (connected to simsiam: Section 6
-
Discusses about conditional independence (CI) condition of the samples w.r.t the labels
-
- Highly theoretical paper.
-
Dwibedi, Debidatta, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. “Counting out time: Class agnostic video repetition counting in the wild.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10387-10396. 2020.
- Countix Dataset for video repeatation count. (part of Kinetics dataset)
- annotated with segments of repeated actions and corresponding counts.
-
Per-frame embedding and similarity!! (RepNet)
-
Compared with benchmark: PERTUBE and QUVA
-
Not really a self-supervised set up, rather a multitask setup.
- Propose to create synthetic dataset by frame repeatation and reversal! Camera motion augmentation (Augmentation)
- Countix Dataset for video repeatation count. (part of Kinetics dataset)
-
Appalaraju, Srikar, Yi Zhu, Yusheng Xie, and István Fehérvári. “Towards Good Practices in Self-supervised Representation Learning.” arXiv preprint arXiv:2012.00868 (2020).
-
Tries to unravel the mysteries behind CL (!!)
- Empirical analysis: provide practice/insight tips
- Why data augmentation and adding projection head works in CL??
- not true in the supervised setting!!
- Why data augmentation and adding projection head works in CL??
-
Design choice and good practice boost CL representation!
- This paper: Focuses (empirical analysis) on three of the key points
- (i) Importance of MLP heads (key factor)
- Requires non-linear projection head on top (fc and ReLU)
- (i) Importance of MLP heads (key factor)
-
(ii) semantic label shift problems by data augmentation: breakdown of class boundaries in strong augmentations
- (iii) Investigate on Negative Samples: Quality and Quantity
-
-
Han, Tengda, Weidi Xie, and Andrew Zisserman. “Self-supervised co-training for video representation learning.” arXiv preprint arXiv:2010.09709 (2020).
-
visual only selfsupervised Representation learning!! [sampling method for CL]
-
new form of supervised CL (adding semantic positive to instance based Infor NCE loss)!! HOW? {explanation in figure 1}
-
co-training scheme with infoNCE loss!! (Explore complementary information from different views
- evaluating the quality of learned representations (two downstream tasks: action recognition and video retrieval)
- Question of “is instance discrimination is best??” - NO
- hard positves! oracle experiment (UberNCE!)
- CoCLR!! mining positive samples of data. (TCN extension by adding another modality, different network for each modality! how it is trained? Dynamic objective!!)
- Question of “is instance discrimination is best??” - NO
- Focused more on sampling procedure
-
Experimented with RGB and FLOW network (aim to improve their representation)
-
Related works: Visual-only supervised learning, Multi-modal self-supervised learning, Co-training Paired networks and Video action recognition
-
InfoNCE and UberNCE differs in sampling positives
-
CoCLR algorithm (Initialization: flow and RGB net trained individually, Alternation: mine hard positive based on others Eq 3,4)
-
Dataset: UCF101, Kinetics-400, HMDB51
-
-
2021
-
Li, T., Wang, L., & Wu, G. (2021). Self supervision to distillation for long-tailed visual recognition. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 630-639).
- address the long-tailed classes by soft-label (self) distillation based fine-tuning.
- Existing alternatives: class re-balanced training (may cause overfit), multistage training
- Figure 1: Interesting perspective of soft-labeling and class re-balanced training.
- Method: ssl feature learning, intermediate soft-label generation (smoothening labels), Joint training with self-distillation (both hard and soft labeling) [eq 5].
- Experimented dataset: ImageNet-LT, CIFAR100-LT, and iNaturalist 2018
- address the long-tailed classes by soft-label (self) distillation based fine-tuning.
-
Liu, H., HaoChen, J. Z., Gaidon, A., & Ma, T. (2021). Self-supervised learning is more robust to dataset imbalance. arXiv preprint arXiv:2110.05025.
- off-the-shelf selfsupervised representations are already more robust to class imbalance
- towards understanding the robustness of SSL, hypothesize that SSL learns richer features from frequent data: it may learn label-irrelevant-but-transferable features that help classify the rare classes and downstream tasks
- empirically validate this intuition by visualizing the features on a semi-synthetic dataset
- devise a re-weighted regularization technique that consistently improves the SSL representation quality on imbalanced datasets
-
Zhang, S., Zhu, F., Yan, J., Zhao, R., & Yang, X. (2021). Zero-cl: Instance and feature decorrelation for negative-free symmetric contrastive learning. In International Conference on Learning Representations.
- To prevent collapse, TP develop two novel methods by decorrelating on different dimensions on the instance embedding stacking matrix, i.e., Instance-wise (ICL) and Feature-wise (FCL) Contrastive Learning
- ICL: instance wise whitening? previous use whitening transformation to reduce the information redundancy on feature-wise.
- Zero-CL mainly enjoys three advantages:
- Negative free in symmetric architecture.
- By whitening transformation, the correlation of the different features is equal to zero, alleviating information redundancy.
- Zero-CL remains original information to a great extent after transformation, improves the accuracy against other whitening transformations
- Extensive experimental results on CIFAR-10/100 and ImageNet
- Related works: Instance wise or feature wise according to dimension.
- IW: neg-pos: SimCLR, InfoNCE, MoCo, BYOL
- FW: Barlow Twin, VICReg
- To prevent collapse, TP develop two novel methods by decorrelating on different dimensions on the instance embedding stacking matrix, i.e., Instance-wise (ICL) and Feature-wise (FCL) Contrastive Learning
-
Bulat, A., Sánchez-Lozano, E., & Tzimiropoulos, G. (2021, June). Improving memory banks for unsupervised learning with large mini-batch, consistency and hard negative mining. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1695-1699). IEEE.
-
Why do we require improvement? how to measure it?
-
3 improvements to the vanilla memory bank-based formulation which brings massive accuracy gains (3 obvious things!!)
- Large mini-batch
- Consistency
- Hard negative mining: devise a novel nearest neighbor approach for improving the memory bank (treat them as +VE)
- Merge them together!!
-
Methods: Large mini-batch with multiple augmentations, Consistency loss across the representations
-
New representation: average of the augmented representations
- \[\text{Memory Update } f_i = m\hat{f}_i + (1-m)\sum_{k=0}^K\frac{1}{K}f_i^k\\ \mathcal{L}_{consist} = \sum_{k=1}^K\sum_{j\neq k}KL(p(i|x_i^k)||p(i|x_i^j))\]
-
Offline hard negative mining to collapse memory (figure 2b)
- NMI metrics
-
-
Zhao, X., Vemulapalli, R., Mansfield, P. A., Gong, B., Green, B., Shapira, L., & Wu, Y. (2021). Contrastive learning for label efficient semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10623-10633).
- pretrain the network using a pixel-wise!!, label-based!! contrastive loss, and then fine-tune it using the cross-entropy loss
-
increases intra-class compactness and inter-class separability
- RW: Region-based loss i.e. region MI loss, affinity field loss
- Applied in label space but CL in feature space.
- TP: SCL setup for Semantic Segmentation
- MTL setup: Joint optimization.
- pixel-wise CL: within-image, across image (SCL)
- RW: Region-based loss i.e. region MI loss, affinity field loss
-
- pretrain the network using a pixel-wise!!, label-based!! contrastive loss, and then fine-tune it using the cross-entropy loss
-
Wang, P., Han, K., Wei, X. S., Zhang, L., & Wang, L. (2021). Contrastive learning based hybrid networks for long-tailed image classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 943-952).
- explore effective SCL strategies to learn better image representations from imbalanced data to boost the classification accu.
- propose a novel hybrid network structure (SCL loss and a CE loss)
- progressively transited from feature learning to the classifier learning as better features make better classifier (how are you sure of it)
- Explore two variant, i) SC ii) prototypical SC (PSC)
-
PSC overcome the memory issue by taking an prototype for classes
- Head classes (more example for few classes) and long-tail (few example for many classes)
- Existing solutions: data re-sampling, loss re-weighting, margin modification, data augmentation.
- decoupling the representation and classifier into two stages
- TP: follow a curriculum to progressively transit the learning from feature learning to classifier learning.
- MTL but utilize the adaptive weights between them.
- Propose PSC and extention of PSC - MPSC loss.
- Overall architecture figure 2
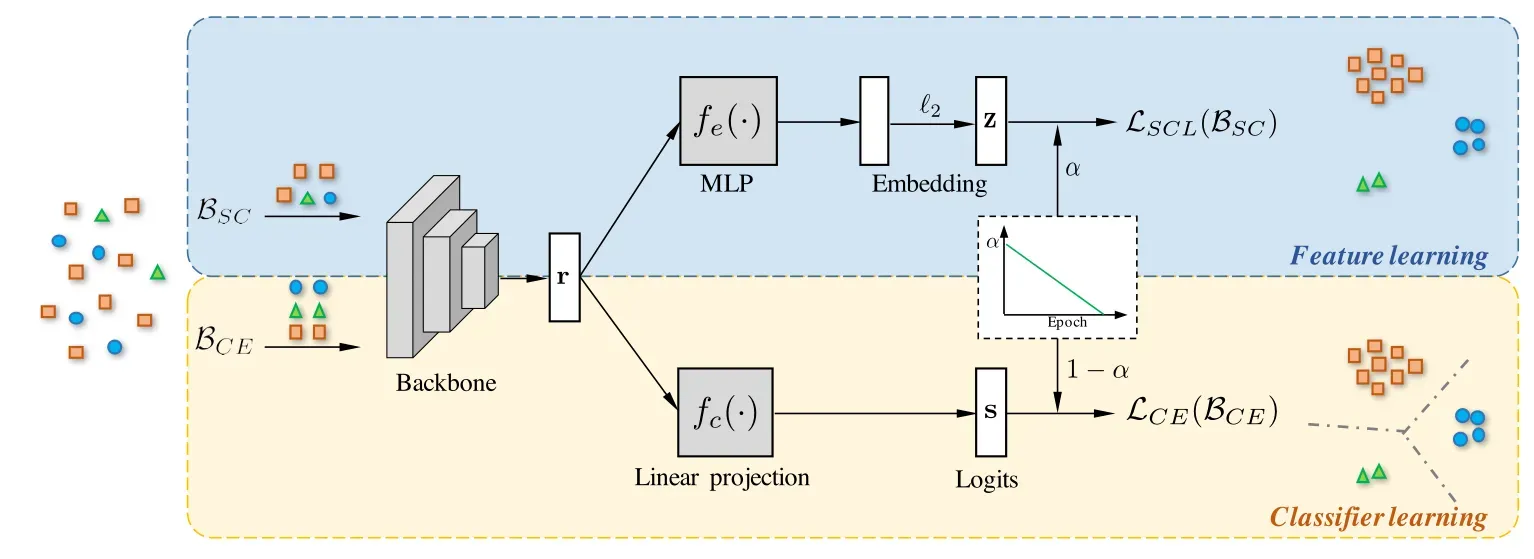
-
- explore effective SCL strategies to learn better image representations from imbalanced data to boost the classification accu.
-
Li, T., Fan, L., Yuan, Y., He, H., Tian, Y., Feris, R., … & Katabi, D. (2020). Making contrastive learning robust to shortcuts. arXiv preprint arXiv:2012.09962.
-
contrastive learning is susceptible to feature suppression
- TP: analyze the objective function of contrastive learning and formally prove that it is vulnerable to feature suppression.
- present predictive contrastive learning (PCL), a framework for learning unsupervised representations that are robust to feature suppression
- force the learned representation to predict the input, prevent it from discarding important information
- simple features are contrastive enough to separate +ve samples from -ve samples, CL might learn such simple (or simpler) features even if irrelevant to the tasks of interest, and other more relevant features are suppressed.
- addresses this problem by designing handcrafted data augmentations that eliminate the irrelevant features
- propose predictive contrastive learning (PCL) as a training scheme that prevents feature suppression
- predict the input, such as inpainting, colorization, or autoencoding.
- Helps to overcome the feature suppression issues.
- similar to auto-encoder but with contrastive flavour.
- predict the input, such as inpainting, colorization, or autoencoding.
-
-
Zhao, L., Wang, Y., Zhao, J., Yuan, L., Sun, J. J., Schroff, F., … & Liu, T. (2021). Learning view-disentangled human pose representation by contrastive cross-view mutual information maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12793-12802).
- Similar idea as our MV work but requires pose and view data
- Camera view augmentation (3D camera data requirement)
- Multiview 2D pose and produce pose estimation.
- Equation 6 clarifies somethings
- Produce view and pose estimation.
- Image domain instead of video domain.
- Camera view augmentation (3D camera data requirement)
- Evaluate our performance on single-shot cross-view action recognition
- Similar idea as our MV work but requires pose and view data
-
Li, R., Zhang, Y., Qiu, Z., Yao, T., Liu, D., & Mei, T. (2021). Motion-Focused Contrastive Learning of Video Representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 2105-2114).
- RQ: how important is the motion particularly for self-supervised video representation learning.
- TP: motion-centered CL (MCL) [kind of augmentation approach]! compose a duet??
- i) MCL capitalizes on optical flow based data augmentations. ii) aligns gradient maps of the CNN layers to optical flow maps from S, T and ST perspectives (incorporate motion information in feature).
- 1) leveraging motion information in achieving DatAug, and 2) taking motion into account in optimizing learning
- Experiment: R(2+1)D models, UCF and kinetics dataset.
- i) MCL capitalizes on optical flow based data augmentations. ii) aligns gradient maps of the CNN layers to optical flow maps from S, T and ST perspectives (incorporate motion information in feature).
- Motion estimation and motion-focused video augmentation.
- optical flow (TV-L1 based) based motion estimation.
- using gradinent in the loss function {match with the flow estimation.}
- Whats the motivation? (only 2% accuracy finally)
- Why we want average gradient to be equal to motion map?
- What if no motion at all (lying activities)
- Diba, Ali, Vivek Sharma, Reza Safdari, Dariush Lotfi, Saquib Sarfraz, Rainer Stiefelhagen, and Luc Van Gool. “Vi2clr: Video and image for visual contrastive learning of representation.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1502-1512. 2021.
- Joint video and image representation learning (kinda new data sampling approach for CL)
- Experiment: action recog, object detection, image.
- C center NCE loss for joint representation [requires tricky computation]
- Concat representation of both and pass through more MLP for Centre loss
- Kinda cluster loss.
- Joint video and image representation learning (kinda new data sampling approach for CL)
-
Nan, Guoshun, Rui Qiao, Yao Xiao, Jun Liu, Sicong Leng, Hao Zhang, and Wei Lu. “Interventional video grounding with dual contrastive learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2765-2775. 2021.
-
[Video Understanding]
-
Gap: models may suffer from spurious correlations between the language and video features due to the dataset selection bias
-
TP: used some form of causal inference (Interventional video grounding) based on Structural causal model
-
a dual CL approach (DCL) to better align the text and video i) query and video clips, and the ii) between start/end frames of a target moment and the others within a video [figure 2 - trivial approach]
-
- Wang, Yu, Jingyang Lin, Jingjing Zou, Yingwei Pan, Ting Yao, and Tao Mei. “Improving Self-supervised Learning with Automated Unsupervised Outlier Arbitration.” Advances in Neural Information Processing Systems 34 (2021).
- Chanllanges the instance label DA for selfsupervised
- argue that the existing DA for positive views naturally introduces out-of-distribution (OOD) samples that undermine the downstream tasks.
- introduce a lightweight latent variable model UOTA, targeting the view sampling issue for SSL
- adaptively searches for the most important sampling region to produce views, and provides viable choice for outlier-robust SSL
- explore the potential OOD noise issue for SSL approaches.
- Chanllanges the instance label DA for selfsupervised
-
Zimmermann, Roland S., Yash Sharma, Steffen Schneider, Matthias Bethge, and Wieland Brendel. “Contrastive learning inverts the data generating process.” In International Conference on Machine Learning, pp. 12979-12990. PMLR, 2021.
-
prove that feedforward models trained with objectives belonging to the commonly used InfoNCE family learn to implicitly invert the underlying generative model of the observed data - proofs make certain statistical assumptions about the generative model, however, hold empirically even if these assumptions are severely violated
-
highlights a fundamental connection between CL, generative modeling, and nonlinear ICA
-
-
Cui, Jiequan, Zhisheng Zhong, Shu Liu, Bei Yu, and Jiaya Jia. “Parametric contrastive learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 715-724. 2021.
- Application scenario: Unbalanced classes
- SupCon setting
-
Supervised contrastive learning.
- tackle long-tailed recognition
- Too much complex paper for then.
- Application scenario: Unbalanced classes
-
Kuang, Haofei, Yi Zhu, Zhi Zhang, Xinyu Li, Joseph Tighe, Sören Schwertfeger, Cyrill Stachniss, and Mu Li. “Video Contrastive Learning with Global Context.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3195-3204. 2021.
-
Why we require the global context though?? what is even global context??
- TP: video-level CL method based on segments to formulate positive pairs
- Key contribution: uniformly divide the video into several segments, and randomly pick a clip from each segment (anchor) and randomly pick a clip from each segment again to form the positive tuple
- a temporal order regularization term (enforce the inherent video sequential structure)
- Key contribution: uniformly divide the video into several segments, and randomly pick a clip from each segment (anchor) and randomly pick a clip from each segment again to form the positive tuple
- Video-level contrastive learning (VCLR) - Well! they contrast within contrast!! (although different head for losses)
- applied to dataset with notion of global and local tasks. - Segment losses: Frame shuffling reformulated as classification problem -
-
Zhong, Huasong, Jianlong Wu, Chong Chen, Jianqiang Huang, Minghua Deng, Liqiang Nie, Zhouchen Lin, and Xian-Sheng Hua. “Graph contrastive clustering.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9224-9233. 2021.
- Well they use some sort of supervised information about latent classes.
- Not directly the instance contrastive approach.
-
representation: a graph Laplacian based contrastive loss is proposed (discriminative and clustering-friendly features).
- assignment: a novel graph-based contrastive learning strategy is proposed (compact clustering assignments.)
-
Overview in Figure 2
-
However Heavy computations
-
- Well they use some sort of supervised information about latent classes.
-
Wang, Jingyu, Zhenyu Ma, Feiping Nie, and Xuelong Li. “Progressive self-supervised clustering with novel category discovery.” IEEE Transactions on Cybernetics (2021).
-
Parameter-insensitive anchor-based graph obtained from balanced K-means and hierarchical K-means
-
a novel representative point selected strategy based on a semisupervised framework
-
Something to do with the laplacian!! and its decomposition.
-
related to OSR
-
-
Li, Yunfan, Peng Hu, Zitao Liu, Dezhong Peng, Joey Tianyi Zhou, and Xi Peng. “Contrastive clustering.” In 2021 AAAI Conference on Artificial Intelligence (AAAI). 2021.
- One stage online clustering method (CC) [instance and cluster label contrast]
- TP: reveal that the row and column of the feature matrix intrinsically correspond to the instance and cluster representation
- TP: Similar to Multitask network setup
- Figure 1: Explains the idea
-
PQ: why don’t they use the entropy loss!! (making single node go up)
- Two different projection head (instance [row] and cluster label [column])
- Figure 2: Methods overview.
- Two different projection head (instance [row] and cluster label [column])
-
NMI metric for clustering
- One stage online clustering method (CC) [instance and cluster label contrast]
-
HaoChen, Jeff Z., Colin Wei, Adrien Gaidon, and Tengyu Ma. “Provable guarantees for self-supervised deep learning with spectral contrastive loss.” Advances in Neural Information Processing Systems 34 (2021).
-
Proposes graph theoretic based spectral contrastive losses (figure 1: a great starting point)
-
Section 3.3: Details the theoretical guarantee on spectral contrastive loss.
-
-
Jahanian, Ali, Xavier Puig, Yonglong Tian, and Phillip Isola. “Generative models as a data source for multiview representation learning.” arXiv preprint arXiv:2106.05258 (2021).
-
RQ: why bother using dataset when you have generator!! (used no real-data)
- off-the-shelf image generator to get multiview data
- Requires careful sampling and training method (!!!)
- Hypothesis: Generator (a organized copy of compressed dataset)
- Requires careful sampling and training method (!!!)
-
We provide an exploratory study of representation learning in the setting of synthetic data sampled from pre-trained generative models:
-
Assumption Generator is able to get a good multiview data (sufficient capable generator)
-
Findings: i) CL can be naturally extended to learning from generative samples (different “views” of the data are created via transformations in the model’s latent space) ii) further can be combined with data augmentation iii) sub-logarithmic performance improvement with generator
-
Interesting related work section
-
Figure 1: summary
-
Key analysis on how to make latent tx to get multiview data. i) gaussian approaches, ii) steered latent views
-
-
Islam, Ashraful, Chun-Fu Richard Chen, Rameswar Panda, Leonid Karlinsky, Richard Radke, and Rogerio Feris. “A broad study on the transferability of visual representations with contrastive learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8845-8855. 2021.
-
TP: comprehensive study on the transferability of learned representations of different contrastive approaches for linear evaluation, full-network transfer, and few-shot recognition
-
Experiment: 12 downstream datasets from different domains, and object detection tasks on MSCOCO and VOC0712
-
Results shows the great transferability of the SSL (expected)
-
Good terminology: Self-SupCon (augmented version) and SupCon (different instances)
-
-
Graf, Florian, Christoph Hofer, Marc Niethammer, and Roland Kwitt. “Dissecting supervised constrastive learning.” In International Conference on Machine Learning, pp. 3821-3830. PMLR, 2021.
-
Discusses the problem of class collapse when minimal loss is attained
-
TP address the question whether there are fundamental differences (between softmax and supcon loss) in the sought-for representation geometry in the output space of the encoder at minimal loss.
- Insight-1. both losses attain their minimum once the representations of each class collapse to the vertices of a regular simplex, inscribed in a hypersphere. (theoretical)
- reaching a close-to-optimal state typically indicates good generalization performance.
- Insight-2. Supcon works superlinearly and Softmax works linearly. (empirical)
-
-
Fu, Daniel Yang, Mayee F. Chen, Michael Zhang, Kayvon Fatahalian, and Christopher Ré. “The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning.” (2021).
- modification to supervised contrastive (SupCon) loss that prevents class collapse (keeps strata) by uniformly pulling apart individual points from the same class.
- SupCon losses information. (collapse the strata information), not good for the downstream tasks.
- Enforces one embedding per class: a regular simplex inscribed in hypersphere.
- Proposes L_{spread} loss [a slight modification of L_{sc}] to preserve the strata in embedding space.
- SupCon losses information. (collapse the strata information), not good for the downstream tasks.
-
Hypothesis: Rarer and distinct strata are further away from common strata. (nice idea, in a unsupervised setup what is even important??) : has entropy flavour.
- modification to supervised contrastive (SupCon) loss that prevents class collapse (keeps strata) by uniformly pulling apart individual points from the same class.
-
Shah, Anshul, Suvrit Sra, Rama Chellappa, and Anoop Cherian. “Max-Margin Contrastive Learning.” arXiv preprint arXiv:2112.11450 (2021).
- Addresses the slow convergence of contrastive methods (uses SVM objective)
-
by selecting negative examples using SVM methods (maximizes the boundary)
- TP: simplification of SVM for alleviating computations and maximizing boundaries for hard negatives (MMCL)
- Essentially a hard-negative mining problem!! (quality over quantity)
- TP: Propose to separate the embedding using powerful SVM classifier.
- One vs all fashion detection!!!
- TP: simplification of SVM for alleviating computations and maximizing boundaries for hard negatives (MMCL)
-
-
Experiment with vision, video, S3D network, tanh kernel.
- Addresses the slow convergence of contrastive methods (uses SVM objective)
-
Bardes, Adrien, Jean Ponce, and Yann LeCun. “Vicreg: Variance-invariance-covariance regularization for self-supervised learning.” arXiv preprint arXiv:2105.04906 (2021).
- TP: Variance-Invariance-Covariance Regularization (how to avoid collapse)
- Applies two regularization term separately with the embeddings : term (1) maintains the variance of each embedding dimension above a threshold, term (2) decorrelates each pair of variables.
- Key contribution: Loss function (triple objective)
-
Related works: prevent collapse by i) Contrastive methods / vector quantization (Simclr, MoCo, memory bank, etc) , ii) Information maximization (prevents information collapse).
-
Great intuition however, requires good sampling. [invariant mean between embeddings, variance of embeddings over a batch > th, covariance between a pair in batches → 0]
-
Requires asymmetric stop gradient (no weight sharing between two branches: allow mutlimodal)
-
As always interesting related work section. [related to decorrelation of barlow twin]
-
Network setup: Encoder and Expander [(1) eliminate the information by which the two representations differ, (2) expand the dimension in a non-linear fashion so that decorrelating the embedding variables will reduce the dependencies (not just the correlations) between the variables of the representation vector]
- TP: Variance-Invariance-Covariance Regularization (how to avoid collapse)
-
Ayush, Kumar, Burak Uzkent, Chenlin Meng, Kumar Tanmay, Marshall Burke, David Lobell, and Stefano Ermon. “Geography-aware self-supervised learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10181-10190. 2021.
- training methods that exploit the spatio-temporal structure (!) of remote sensing data (!!). [application to satellite dataset]
-
- MT: Can we also contrast based on that (disentangled)
- Experiments: Functional Mop of the world (fMoW)benchmark, Geo-tagged imagenet dataset. Arch: ResNet
- Hypothesis: Existance of remote sensing data’s geo-located and multiple images of the same location over time.
- representations to be invariant to subtle variations over time (object detection or semantic segmentation) [task 1: contrastive]
- representations that reflect geographical information (useful in remote sensing tasks) [task 2: meta-data prediction]
-
- TP: Combine two loss function specialized in remote sensing image dataset.
- training methods that exploit the spatio-temporal structure (!) of remote sensing data (!!). [application to satellite dataset]
-
Das, Srijan, and Michael S. Ryoo. “ViewCLR: Learning Self-supervised Video Representation for Unseen Viewpoints.” arXiv preprint arXiv:2112.03905 (2021).
- View generator (3d geometric transformations): Learnable augmentation for pretext task (maximizing viewpoint similarities).
- Aim: Generalize over unseen camera viewpoints. Camera invariant features
- learnable augmentation to induce viewpoint (by VG) changes while for self-supervised representation.
- Aim: Generalize over unseen camera viewpoints. Camera invariant features
- Dataset: NTU RGB+D and NUCLA, MOCO for instance discrimination. (New PRETraining!!), arch: S3D, Evaluation: Cross subject and cross setting protocol.
- View generator (3d geometric transformations): Learnable augmentation for pretext task (maximizing viewpoint similarities).
-
Hua, Tianyu, Wenxiao Wang, Zihui Xue, Sucheng Ren, Yue Wang, and Hang Zhao. “On feature decorrelation in self-supervised learning.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9598-9608. 2021.
-
analysis the collapse issues (looks detail of complete and dimensional collapse: figure 1)
-
Verification of collapse (!!) by standardizing variance.
- Reveal connection between dimensional collapse and strong correlation. (where??) [dimension collapse is indicated by strong correlation among the features]
- Performance gain by feature decorrelation
- TP: Proposes decorrelated Batch normalization layer
- Earlier findings: BN in projection layer avoids vanishing variances (complete collapse).
- TP: Proposes decorrelated Batch normalization layer
- Performance gain by feature decorrelation
- Main read: Section 3 is interesting to read (some key findings)- may be transcribed to work.
- Multiply the features by whitening matrix (precision matrix)
- Reveal connection between dimensional collapse and strong correlation. (where??) [dimension collapse is indicated by strong correlation among the features]
-
-
Desai, Karan, and Justin Johnson. “Virtex: Learning visual representations from textual annotations.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11162-11173. 2021.
-
Chen, Kai, Lanqing Hong, Hang Xu, Zhenguo Li, and Dit-Yan Yeung. “MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving.” arXiv preprint arXiv:2108.12178 (2021).
-
TP: Two issues: (1) define positive samples for cross-view consistency ? (2) measure similarity in multi-instance circumstances ?
-
Experiments data: WayMo, SODA10M
-
Global consistency to local consistency?
- basic assumption of instance discrimination: different views of the same image should be consistent in the feature space
- what about multi-instance in a single image (realistic case)!!!
- definition of positive samples is definitely needed to extend cross-view consistency framework to multi-instance circumstances. (multiple things in single image)
- Methods: Uses IoU as proxy for data and Noise. (les IoU - More Noise)
- Remove global pooling (counter the multiple instance collapse)
- Well, very complex loss function!
- basic assumption of instance discrimination: different views of the same image should be consistent in the feature space
-
Related works: VirTex, ConVIRT, ICMLM (proof of concept)
- <embed src="https://mxahan.github.io/PDF_files/multisiam.pdf" width="100%" height="850px"/> -
-
Yang, Ceyuan, Zhirong Wu, Bolei Zhou, and Stephen Lin. “Instance localization for self-supervised detection pretraining.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3987-3996. 2021.
- Propose a new self-supervised tasks : Instance Localization. [self-supervised task design]
- Put image crop into another and try to predict using RPN!! -
Wang, Feng, and Huaping Liu. “Understanding the behaviour of contrastive loss.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2495-2504. 2021.
- Studies the impact of the temperature in loss function (uniformity and temperature).
- How to ensure tolerant for semantic similar examples [uniformity tolerance dilemma]
- This paper: studies hardness aware properties (parameter in loss function).
- Studies the impact of the temperature in loss function (uniformity and temperature).
-
Pan, Tian, Yibing Song, Tianyu Yang, Wenhao Jiang, and Wei Liu. “Videomoco: Contrastive video representation learning with temporally adversarial examples.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11205-11214. 2021.
- TP: adversarial learning as a temporal data augmentation strategy to improve feature representations.
- The output of ConvLSTM predicts the importance of each frame and drops some of them.
- C3D architecture as our encoder.
- An extra generator to kinda get hard negative query and temporal decay for the keys.
- TP: adversarial learning as a temporal data augmentation strategy to improve feature representations.
-
Xu, Jiarui, and Xiaolong Wang. “Rethinking Self-supervised Correspondence Learning: A Video Frame-level Similarity Perspective.” arXiv preprint arXiv:2103.17263 (2021).
-
Liu, Xiao, Fanjin Zhang, Zhenyu Hou, Li Mian, Zhaoyu Wang, Jing Zhang, and Jie Tang. “Self-supervised learning: Generative or contrastive.” IEEE Transactions on Knowledge and Data Engineering (2021).
- Another Survey Paper
- summarize them into three main categories according to their objectives: generative, contrastive, and generative-contrastive (adversarial).
- collect related theoretical analysis on SSL to provide deeper thoughts on why self-supervised learning works
-
Akbari, Hassan, Linagzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. “Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text.” arXiv preprint arXiv:2104.11178 (2021).
-
Sordoni, Alessandro, Nouha Dziri, Hannes Schulz, Geoff Gordon, Philip Bachman, and Remi Tachet Des Combes. “Decomposed Mutual Information Estimation for Contrastive Representation Learning.” In International Conference on Machine Learning, pp. 9859-9869. PMLR, 2021.
-
Yang, Mouxing, Yunfan Li, Zhenyu Huang, Zitao Liu, Peng Hu, and Xi Peng. “Partially view-aligned representation learning with noise-robust contrastive loss.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1134-1143. 2021.
- Partially view alignment Problem (PVP)???
- Objective: aligning data and learning representation (why it is important??) - TP: Propose noise robust Contrastive loss to eliminate False negative {related to learning with noisy labels, any evidence on this?} - New definition of noisy labels (why, is it valid?) [false negative pair as noisy label! ] - Experiment: 10 SOTA classification and clustering tasks! - Two assumption on Data: Completeness (contains all views [partially data-missing problem]) and Consistency (no false negative/positive [partial view alignment problem]) of views. - Proposed modified distance loss for the negative pairs. - <embed src="https://mxahan.github.io/PDF_files/partially_view_aligned.pdf" width="100%" height="850px"/> -
Dave, Ishan, Rohit Gupta, Mamshad Nayeem Rizve, and Mubarak Shah. “TCLR: Temporal Contrastive Learning for Video Representation.” arXiv preprint arXiv:2101.07974 (2021).
- temporal CL framework!!- (why?) - two novel loss functions
- (local-local): non-overlapping of same videos!!
- (global-local): increase temporal diversity!!
- NCE based loss function formulation.
- Interesting way to sample local and global (why is it necessary???) [figure 2, 3, and 4]
- Architecture: 3D ResNet-18 - temporal CL framework!!- (why?) - two novel loss functions
-
Tian, Yuandong, Xinlei Chen, and Surya Ganguli. “Understanding self-supervised learning dynamics without contrastive pairs.” arXiv preprint arXiv:2102.06810 (2021).
- Theoretical: Why non-contrastive (without negative pairs) methods do not collapse (BYOL, SimSiam by using extra predictors/stop-gradient)
- TP: DirectPred (Directly sets the linear predictor based on the statistics of its inputs, without gradient training)
- motivated by theoretical study of the nonlinear learning dynamics of non-contrastive SSL in simple linear networks
- yields conceptual insights into how non-contrastive SSL methods learn, how they avoid representational collapse, and impact of multiple factors, like predictor networks, stop-gradients, exponential moving averages, and weight decay
- Empirical impacts of multiple hyperparams: i) EMA/momentum encoder ii) predictor optimality and LR iii) Weight decay (good ablation studies) [**section 3.2**] - [**Essential part of non-contrastive SSL: existance of the predictor and the stop-gradient**] - TP directPred: thereby avoiding complicated predictor dynamics and initialization issues by using PCA and setting predictor weight [*section 4*]. - Th 1: ((Weight decay promotes balancing of the predictor and online networks), Th 2: (The stop-gradient signal is essential for success.) - <embed src="https://mxahan.github.io/PDF_files/Understanding_SSL_without_negative.pdf" width="100%" height="850px"/> - Theoretical: Why non-contrastive (without negative pairs) methods do not collapse (BYOL, SimSiam by using extra predictors/stop-gradient)
-
Caron, Mathilde, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. “Emerging properties in self-supervised vision transformers.” arXiv preprint arXiv:2104.14294 (2021).
-
DINO: knowledge Distillation with NO labels (Figure 2, Algorithm 1)
- Self-supervised learning with ViT
- Observations: (i) T features contain explicit information (!!!) about the semantic segmentation of an image
- explicit information: scene layout, object boundaries (directly accessible)
- Performs basic k-NN without any supervision.
- Observations: (i) T features contain explicit information (!!!) about the semantic segmentation of an image
- Cross entropy loss (sharpening and centering requires to avoid collapse)
- Experiments: Architecture (i) ViT and (ii) ResNet - <embed src="https://mxahan.github.io/PDF_files/Dino.pdf" width="100%" height="850px"/> -
-
Tan, Hao, Jie Lei, Thomas Wolf, and Mohit Bansal. “VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning.” arXiv preprint arXiv:2106.11250 (2021).
-
Tian, Yonglong, Olivier J. Henaff, and Aaron van den Oord. “Divide and Contrast: Self-supervised Learning from Uncurated Data.” arXiv preprint arXiv:2105.08054 (2021).
- Effects of contrastive learning from larger, less-curated image datasets such as YFCC
- Finds a large difference in the resulting representation quality
-
because (hypothesis) distribution shift in image class (less relevant negative to learn)
- TP: new approach DnC (divide and contrast) - alternate between CL and cluster based hard negative mining
- Methods: Train individual models on subset and distill them into single model
- Application Scope: less curated data to train! Aim: attempts to recover local consistency.
- The distillation parts requires k+1 networks!
- what if: the networks reaches different embedding in each running (from scratch!)
- How come predicting both simultaneously makes sense?
- TP: new approach DnC (divide and contrast) - alternate between CL and cluster based hard negative mining
-
- Experiment dataset: JFT-300, YFCC100M, 95M Flickr
- Effects of contrastive learning from larger, less-curated image datasets such as YFCC
-
-
Zheltonozhskii, Evgenii, Chaim Baskin, Avi Mendelson, Alex M. Bronstein, and Or Litany. “Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels.” arXiv preprint arXiv:2103.13646 (2021).
- warm-up obstacle: the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels.!!
-
SoTA depends on warm-up stage where standard supervised training is performed using the full (noisy) training set
- TP: contrast to divide (C2D)
- benefit: drastically reducing the warm-up stage’s susceptibility to noise level, shortening its duration, and increasing extracted feature quality
- TP: contrast to divide (C2D)
-
- warp-up stages!! Current works focus on warm up length only! requires optimal warm-up length! or relying on external dataset! TP: Self-supervised pretraining! - TP: firstly perform simclr, then proceed with standard LNL algorithm (: ELR+ and DivideMix!!)
- warm-up obstacle: the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels.!!
-
Huang, Lianghua, Yu Liu, Bin Wang, Pan Pan, Yinghui Xu, and Rong Jin. “Self-supervised Video Representation Learning by Context and Motion Decoupling.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13886-13895. 2021.
- a method that explicitly decouples motion supervision from context bias through a carefully designed pretext task
- (i) Context matching (CL between key frame (how to find it?? - Random frame selection) and video clips) & Motion Prediction (estimate motion features in the future & also a regularizer)
- Architecture: Shared backbone and separate head for the tasks
- Figure 2: says all: Two target for the V-network (context {top, extracted from image} & motion {bottom, derived using the motion vectors?})
- Related works: representation learning, AR in compressed videos, Motion prediction - Experiments: - Networks: Video backbone: C3D, R(2+1)D-26 and R3D-26 (V, video), shallow R2D-10 (I, context), and R3D-10 (video). - Data: UCF, Kinetics, HMDB51, with augmentation (same for one example), hard negatives, - a method that explicitly decouples motion supervision from context bias through a carefully designed pretext task
-
Feichtenhofer, Christoph, Haoqi Fan, Bo Xiong, Ross Girshick, and Kaiming He. “A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3299-3309. 2021.
- A large-scale study on unsupervised spatiotemporal representation learning from videos
- Generalize image based method into space-time. (e.g. crop [image] to clip [video])
- Provides many empirical results
- A large-scale study on unsupervised spatiotemporal representation learning from videos
-
Hénaff, Olivier J., Skanda Koppula, Jean-Baptiste Alayrac, Aaron van den Oord, Oriol Vinyals, and João Carreira. “Efficient Visual Pretraining with Contrastive Detection.” arXiv preprint arXiv:2103.10957 (2021).
- Tackles the computational complexity of the self-supervised learning
- By providing new objective (extract rich information from each image!! ) named Contrastive Detection (Figure 2)
- Two variants: SimCLR and the BYOL
- Knowledge tx across the dataset
- Heuristic mask on image and train!
- Of the shelf unsupervised/human annotators [external methods]
- Pull the features spaces close!!
- maximizes the similarity of object-level features across augmentations.
- Result 5x less pretraining
- Compared with SEER!!
- Experiment with imagenet to COCO dataset
- By providing new objective (extract rich information from each image!! ) named Contrastive Detection (Figure 2)
- This paper: Special Data augmentation scheme - Tackles the computational complexity of the self-supervised learning
-
Goyal, Priya, Mathilde Caron, Benjamin Lefaudeux, Min Xu, Pengchao Wang, Vivek Pai, Mannat Singh et al. “Self-supervised pretraining of visual features in the wild.” arXiv preprint arXiv:2103.01988 (2021).
- SEER and connection to few shot learning
- RQ: pretraining extremely large collection of uncurated, unlabeled images for good achievement?
- Solution: Continuous learning in a self-supervised manner! (online fashion training)
- RQ: pretraining extremely large collection of uncurated, unlabeled images for good achievement?
- TP: pretrain high capacity model (RegNet Architecture!! 700M params) on billions images! using SwAV approaches with large BS. - Results: One of the best model!! both on curated and uncarated data.
- Related works: Scale on large uncurated images. (also scaling the network - Good Reads) - Results on finetuning large models, low shot learning and transfer learning. - Ablation studies: Model architecture, scaling the training data, scaling the self-supervised model head - SEER and connection to few shot learning
-
Zbontar, Jure, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. “Barlow Twins: Self-Supervised Learning via Redundancy Reduction.” arXiv preprint arXiv:2103.03230 (2021).
- Tries to avoid trivial solution (by new objective function, cross-correlation matrix)!!
- A new loss function
-
Same images ~ augmentation representations are distorted version of each other.
-
Motivation: Barlows Redundancy-reduction principle
- Pair of identical neurons
- Just WOW: The hell the idea is!!
- Intriguingly avoids trivial solutions
- Should require large batch size
- Just WOW: The hell the idea is!!
-
Figure 1 & algorithm 1: Crack of all jack
-
BOYL follow up works
- Contrastive learning
- Either Negative examples
- Or architectural constraint/ Asymmetric update
- Motivated from Barlow-twin (redundancy-reduction principle) 1961!
- H. Barlow hypothesized that the goal of sensory processing is to recode highly redundant sensory inputs into a factorial code (a code with statistically independent components).
- propose new loss function: tries to make the cross-correlation matrix computed from twin representations as close to the identity matrix as possible
- Advantages: Not required Asymmetric update or large batch size
- Methods description
- What is Barlow twins
- connection to Information bottleneck (IB)
- Implementation details
- What is Barlow twins
- Result
- Linear and Semi-supervised Evalution of imagenet
- Transfer learning
- Object detection and segmentation
- Ablation study
- Variation of Loss function
- Impacts of Batch Size
- Outperformed by Large BS with BYOL and SimCLR
- network selection impacts
- projection head importance
- Importance of the data augmentation
- Discussion (interesting)
- Comparison with Prior Art
- InfoNCE
- Comparison with Prior Art
- Contrastive learning
- Tries to avoid trivial solution (by new objective function, cross-correlation matrix)!!
-
Tsai, Yao-Hung Hubert, Martin Q. Ma, Muqiao Yang, Han Zhao, Louis-Philippe Morency, and Ruslan Salakhutdinov. “Self-supervised representation learning with relative predictive coding.” arXiv preprint arXiv:2103.11275 (2021).
-
Liu, Yang, Keze Wang, Haoyuan Lan, and Liang Lin. “Temporal Contrastive Graph for Self-supervised Video Representation Learning.” arXiv preprint arXiv:2101.00820 (2021).
- Graph Neural Network And Contrastive Learning - Video frame shuffling
-
Bulat, Adrian, Enrique Sánchez-Lozano, and Georgios Tzimiropoulos. “Improving memory banks for unsupervised learning with large mini-batch, consistency and hard negative mining.” arXiv preprint arXiv:2102.04442 (2021).
- Improvement for the memory bank based formulation (whats the problem??)
- TP: (I) Large mini-batch: Multiple augmentation! (II) Consistency: Not negative enforce! The heck? how to prevent collapse? (III) Hard Negative Mining
- Results: Improve the vanilla memory bank! Evidence!! Dataset experimentation!
- Exploration: With Batch Size and visually similar instances (is the argument 2 is valid?) - Contribution 2 seems important! - Each image is augmented k times: More data augmentation! - Interesting way to put the negative contrastive parts to avoid collapse (eq 3) - Experiments: Seen testing categories (CIFAR, STL), & unseen testing categories (Stanford Online Product). ResNet-18 as baseline model - <embed src="https://mxahan.github.io/PDF_files/Improving_MB.pdf" width="100%" height="850px"/> - Improvement for the memory bank based formulation (whats the problem??)
-
Dwibedi, Debidatta, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. “With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations.” arXiv preprint arXiv:2104.14548 (2021).
- Positive from other instance (instead of augmented version of same image!)
- positive sampling: Nearest neighbor in the latent space (NNCLR) [this covers both same samples and Nearest neighbor in the latent spaces] - Benefit: Less reliant on complex data augmentation (empirical results) - Experiments: semi-sup benchmark, tx-learning benchmark - Training: figure 1 (support set similar to memory bank but only provides positive samples) - Similarity across previously seen objects! (tricky implementation)! Initialization!! - Figure 2: details and key difference with others! (requires support set!) - <embed src="https://mxahan.github.io/PDF_files/NNCLR.pdf" width="100%" height="850px"/> -
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. “Learning transferable visual models from natural language supervision.” arXiv preprint arXiv:2103.00020 (2021).
- CLIP (contrastive learning from language image pretraining)
- RQ: Can we reduce the necessity for requiring additional labelled data!
- TP: predict caption and the images (!self-supervised task) [self-supervised task design]
- Learning image representation from the text
- Result matches SOTA
- TP: predict caption and the images (!self-supervised task) [self-supervised task design]
- Related works: VirTex, ICMLM, ConVIRT
-
Tosh, Christopher, Akshay Krishnamurthy, and Daniel Hsu. “Contrastive learning, multi-view redundancy, and linear models.” In Algorithmic Learning Theory, pp. 1179-1206. PMLR, 2021.
- TP: Theory for contrastive learning in the multi-view setting, where two views of each datum are available.
- learned representations are nearly optimal on downstream prediction tasks whenever the two views provide redundant information about the label.
- what is redundant information!! := whenever the best linear prediction of the label on each individual view is nearly as good as the best linear prediction of the label when both views are used together.
- learned representations are nearly optimal on downstream prediction tasks whenever the two views provide redundant information about the label.
- TP: Theory for contrastive learning in the multi-view setting, where two views of each datum are available.
-
Teng, Jiaye, Weiran Huang, and Haowei He. “Can pretext-based self-supervised learning be boosted by downstream data? a theoretical analysis.” arXiv preprint arXiv:2103.03568 (2021).
- Highly theoretical paper.
- whether we can make the CI (conditional independence) condition hold by using downstream data to refine the unlabeled data to boost self-supervised learning [Not always true though it seems intuitive]
- Shows some result to prove the counter intuitive results (Hence focusing the importance of the conditional independence)
- Can we make the CI condition hold with the help of downstream data to boost self-supervised learning? (as CI rearly helds)
- Validate self-supervised approach (not to used fine-tune data during pretraining)
- whether we can make the CI (conditional independence) condition hold by using downstream data to refine the unlabeled data to boost self-supervised learning [Not always true though it seems intuitive]
- Highly theoretical paper.
-
Ren, Xuanchi, Tao Yang, Yuwang Wang, and Wenjun Zeng. “Do Generative Models Know Disentanglement? Contrastive Learning is All You Need.” arXiv preprint arXiv:2102.10543 (2021).
-
Jing, Li, Pascal Vincent, Yann LeCun, and Yuandong Tian. “Understanding Dimensional Collapse in Contrastive Self-supervised Learning.” arXiv preprint arXiv:2110.09348 (2021).
- Discusses about dimension collapse ( the embedding vectors end up spanning a lower-dimensional subspace instead of the entire available embedding space.)
- key findings.
- along the feature direction where data augmentation variance is larger than the data distribution variance, the weight collapses. (strong augmentation along feature dimensions)
- even if the covariance of data augmentation has a smaller magnitude than the data variance along all dimensions, the weight will still collapse due to the interplay of weight matrices at different layers known as implicit regularization. (implicit regularization driving models toward low-rank solutions)
- key findings.
- looks into the covariance matrix (their eigen decomposition; some eigenvalues become zeros) to measure dimensional collapse - Theoretically justify the importance of the projection layers.
- TP: proposed DirectCLR (uses direct Optimization on the representation layer by selecting a subsection of the layer for loss calculation. remove the requirement of trainable projection. ) - Discusses about dimension collapse ( the embedding vectors end up spanning a lower-dimensional subspace instead of the entire available embedding space.)
-
Sordoni, Alessandro, Nouha Dziri, Hannes Schulz, Geoff Gordon, Philip Bachman, and Remi Tachet Des Combes. “Decomposed Mutual Information Estimation for Contrastive Representation Learning.” In International Conference on Machine Learning, pp. 9859-9869. PMLR, 2021.
-
Ryali, Chaitanya K., David J. Schwab, and Ari S. Morcos. “Leveraging background augmentations to encourage semantic focus in self-supervised contrastive learning.” arXiv preprint arXiv:2103.12719 (2021).
- This Paper: Image augmentation regarding the subject and background relationship - “background Augmentation” [sampling method for CL]
- How they separate the subject background in the first places!! What prior knowledge!!
-
May use different existing methods!!
- Augmentation Scheme: Another data engineering
- Used with methods like BYOL, SwAV, MoCo to push SOTA forward
- Figure 1: Shows all
- Augmentation Scheme: Another data engineering
- This Paper: Image augmentation regarding the subject and background relationship - “background Augmentation” [sampling method for CL]
-
Tosh, Christopher, Akshay Krishnamurthy, and Daniel Hsu. “Contrastive estimation reveals topic posterior information to linear models.” Journal of Machine Learning Research 22, no. 281 (2021): 1-31.
-
Ericsson, Linus, Henry Gouk, Chen Change Loy, and Timothy M. Hospedales. “Self-Supervised Representation Learning: Introduction, Advances and Challenges.” arXiv preprint arXiv:2110.09327 (2021).
- Provides a good workflow for selfsupervised Learning
-
extractor function, classifer function, pretext output function (good terminology)
- (Four pretext): masked prediction, transformation prediction, instance discrimination, and clustering
- Masked prediction: context can be used to infer some types of missing information in the data if the domain is well-modeled.
- (Four pretext): masked prediction, transformation prediction, instance discrimination, and clustering
-
- Provides a good workflow for selfsupervised Learning
2022
-
Wang, H., Guo, X., Deng, Z. H., & Lu, Y. (2022). Rethinking minimal sufficient representation in contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16041-16050).
- Supervision information for one view comes from the other view, CL approximately obtains the minimal sufficient representation which contains the shared information and eliminates the non-shared information between views - risk of over-fitting to the shared information between views - cannot be guaranteed that all task-relevant information is shared between views (TP proves it) - How to capture the non-shared tasks!!?? revert input from the representation may be.
- propose to increase the MI between the representation and input as regularization to introduce more task-relevant information
- two implementations to increase MI. 1. reconstructs the input 2. relies on the high-dimensional MI estimate
- Eq 14 and 15: alternative to increase MI between input-representation with re parametrization trick.
-
Govindarajan, H., Sidén, P., Roll, J., & Lindsten, F. (2022, September). DINO as a von Mises-Fisher mixture model. In The Eleventh International Conference on Learning Representations.
- DINO and its derivatives, such as iBOT, can be interpreted as a mixture model of von Mises-Fisher components.
- propose DINO-vMF, that adds appropriate normalization constants when computing the cluster assignment probabilities.
- More stable than DINO for larger ViT-Base model.
- added one extra term (normalization of vMF distribution C_p(k)) with the dino equation: equation 6 and 7
- the normalization term as it depends on the temperature and hard to predict.
- mixture model is beneficial in terms of better image representations
-
Chuang, C. Y., Hjelm, R. D., Wang, X., Vineet, V., Joshi, N., Torralba, A., … & Song, Y. (2022). Robust contrastive learning against noisy views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16670-16681).
- CL relies on an assumption that positive pairs share certain underlying information about an instance.
- But what if this assumption is violated? CL produces suboptimal representations in the presence of noisy views
- TP: propose a new contrastive loss function that is robust against noisy views (RINCE: robust InfoNCE)
- provide rigorous theoretical justifications by
- show connections to robust symmetric losses for noisy binary classification
- establish a new contrastive bound for mutual information maximization based on the Wasserstein distance measure
- completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss
- the q can be thought of temperature parameter
- provide rigorous theoretical justifications by
- Figure 3: loss and gradient visualization. interesting
- Symmetric loss functions are robust against noisy labels in binary classification
- CL relies on an assumption that positive pairs share certain underlying information about an instance.
-
Balestriero, R., & LeCun, Y. (2022). Contrastive and non-contrastive self-supervised learning recover global and local spectral embedding methods. arXiv preprint arXiv:2205.11508.
- RG: SSL theoretical foundations are limited, method-specific, and fail to provide principled design guidelines to practitioners
- TP: propose a unifying framework under the helm of spectral manifold learning to address those limitations
- demonstrate that VICReg, SimCLR, BarlowTwins et al. correspond to eponymous spectral methods such as Laplacian Eigenmaps, Multidimensional Scaling et al
- (i) the closed-form optimal representation for each method
- (ii) the closed-form optimal network parameters in the linear regime for each method
- (iii) the impact of the pairwise relations used during training on each of those quantities and on downstream task performances
- (iv) theoretical bridge between contrastive and non-contrastive methods towards global and local spectral embedding methods
- (i) if the pairwise relation is aligned with the downstream task, any SSL method can be employed successfully and will recover the supervised method, but in the low data regime, VICReg’s invariance hyperparameter should be high;
- (ii) if the pairwise relation is misaligned with the downstream task, VICReg with small invariance hyper-parameter should be preferred over SimCLR or BarlowTwins.
- SSL places itself in-between supervised and unsupervised learning as it does not require labels but does require knowledge of what makes some samples semantically close to others.
- SSL relies on inputs and inter-sample relations (X, G) that indicate semantic similarity akin to weak-supervision used in metric learning
- a more fundamental and principled understanding of SSL mostly take one of the three following approaches:
- (i) studying the training dynamics and optimization landscapes in a linear network regime e.g. validating some empirically found tricks as necessary conditions for stable gradient dynamics
- (ii) studying the role of individual SSL components separately e.g. the projector and predictor networks
- (iii) developing novel SSL criteria that often combine multiple interpretable objectives that a SSL model must fulfill
-
Li, W., Kong, M., Yang, X., Wang, L., Huo, J., Gao, Y., & Luo, J. (2022). A Unified Framework for Contrastive Learning from a Perspective of Affinity Matrix. arXiv preprint arXiv:2211.14516.
- TP: Unified the contrastive losses from the affinity matrix (similarity matrix) between embedding (figure 1)
- three variants, i.e., SimAffinity, SimWhitening and SimTrace
- Propose novel simple symmetric loss: Accelerate training and alleviate false negative problem!
- SimTrace avoid the mode collapse by maximizing the whitened affinity matrix trace without relying on asymmetry designs or stop-gradients.
- Roughly classified into four categories: (1) standard CL with an InfoNCE like MoCo and SimCLR; (2) non-contrastive methods with only positive pairs, such as BYOL and SimSiam; (3) whitening regularization: W-MSE and VICReg; and (4) consistency regularization based methods
- TP: Unified the contrastive losses from the affinity matrix (similarity matrix) between embedding (figure 1)
-
Yeh, C. H., Hong, C. Y., Hsu, Y. C., Liu, T. L., Chen, Y., & LeCun, Y. (2022, November). Decoupled contrastive learning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI (pp. 668-684). Cham: Springer Nature Switzerland.
- Decouple negative and positive components from the InfoNCE losses
- Section 3 describes all
- Proposition 1: shows that the InfoNCE gradient is weighted by coupled positive and negative terms
- Describes some short coming of such coupling
- Proposition 2: decouple by removing positive contribution from the denominators.
- Proposition 1: shows that the InfoNCE gradient is weighted by coupled positive and negative terms
- Section 3 describes all
- My thoughts: It removes the idea of probabilistic interpretation of InfoNCE loss???
- Decouple negative and positive components from the InfoNCE losses
-
Jang, M., & Chung, S. Y. (2022). Few-Example Clustering via Contrastive Learning. arXiv preprint arXiv:2207.04050.’
- Novel algorithm (!) that perform CL to cluster few examples
- (1) generation of candidate cluster assignments, (pre-trained network)
- (2) contrastive learning for each cluster assignment (fine-tune)
- (3) selection of the best candidate (choose the candidate with the smallest training loss in the early stage of learning??)
- Interesting Learning Curve??
- hypothesis: contrastive learner with the ground-truth cluster assignment is trained faster than the others
- small-loss criterion to find clean examples (clean data)
- Inspired from what a network learn first?
- Experiment: mini-ImageNet and CUB-200-2011
- Focus on High-dimensional, Low Sample Size (HDLSS)
- Novel algorithm (!) that perform CL to cluster few examples
-
Bardes, A., Ponce, J., & LeCun, Y. (2022). VICRegL: Self-Supervised Learning of Local Visual Features. arXiv preprint arXiv:2210.01571.
- TP explore the fundamental trade-off between producing a global feature with invariance properties (classification) , and producing set of local features (detection and segmentation).
- VicReg applied to global and local (two identical branches of CNN)
- local feature vectors are attracted to each other if their
- L2 -distance is below a threshold
- or their relative locations are consistent with a known geometric tx between the two input images (Nice)
- Related Works (GEMS): Global Features (invariant to various views), Local Features (a set of local features that describe small parts of the image, mask based approaches): Segmentation tasks
- Extra consistency term to cover the local features (top-$\gamma$ matching)
- Location based matching (Shift between two shifted images)
- Feature based matching for the Nearest Neighborhood pixels (addresses the impact of global pooling) of the augmented version
- capture long-range interactions not captured by location-based matching (as not from the same location of seed images)
- What if background is captured!!! (background with the object!)
- Top-\gamma to avoid such extremes
- Shwartz-Ziv, R., Balestriero, R., & LeCun, Y. (2022). What Do We Maximize in Self-Supervised Learning?. arXiv preprint arXiv:2207.10081.
- Examine VICReg learning methods to provide an information-theoretical understanding of their construction
- Demonstrate how information-theoretic quantities can be obtained for a deterministic network (alternative to prior works)
- VICReg can be (re)discovered from first principles and its assumptions about data distribution
- opening new avenues for theoretical and practical understanding of SSL and transfer learning.
-
Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., & Wu, Y. (2022). Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917.
- Combination of two losses (Contrastive and captioning loss)
- MT: Contain a flavour of information theoretic losses.
- Attention mechanism: utilization of cross attention (image to text)
- Combination of two losses (Contrastive and captioning loss)
-
Pokle, A., Tian, J., Li, Y., & Risteski, A. (2022). Contrasting the landscape of contrastive and non-contrastive learning. arXiv preprint arXiv:2203.15702.
-
via a combination of empirical and theoretical results, we provide evidence that non-contrastive methods based on data augmentation can lead to substantially worse representations.
-
the non-contrastive loss has a prevalence of bad optima that are not collapsed (in neither way, complete or dimension collapse)
-
prove that the training dynamics can remedy this situation—however, crucially tied to a careful choice of a predictor network model architecture.
-
-
Zhang, C., Zhang, K., Zhang, C., Pham, T. X., Yoo, C. D., & Kweon, I. S. (2022). How does simsiam avoid collapse without negative samples? a unified understanding with self-supervised contrastive learning. arXiv preprint arXiv:2203.16262.
- Refute SimSiam claims and introduce vector decomposition for analyzing the collapse based on the gradient analysis of the l2-normalized representation
- unified perspective on how negative samples and SimSiam alleviate collapse
-
SSL methods learn an encoder with augmentation-invariant representation
-
center vector gradient helps prevent collapse via the de-centering effect and its residual gradient achieves de-correlation which also alleviates collapse
- Towards simplifying the predictor we have also found that a single bias layer is sufficient for preventing collapse
- Refute SimSiam claims and introduce vector decomposition for analyzing the collapse based on the gradient analysis of the l2-normalized representation
-
Shen, K., Jones, R. M., Kumar, A., Xie, S. M., HaoChen, J. Z., Ma, T., & Liang, P. (2022, June). Connect, not collapse: Explaining contrastive learning for unsupervised domain adaptation. In International Conference on Machine Learning (pp. 19847-19878). PMLR.
- CL pre-training learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods.
- CL does not learn domain-invariant features, diverging from UDA intuitions.
- CL learn features vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information.
- find that a UDA is out-of-the-box contrastive pre-training on source and target unlabeled data, followed by fine-tuning on source labeled data
- Simple findings: CL keeps everything separated, sufficient for downstream tasks.
- That is where it comes connect this but not to collapse them.
-
Assumption and definition of class domain connectivity (figure 1)
- Connected the graph theory [section 4.2]: Good read.
- discusses the importance of augmentation strengths.
- CL pre-training learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods.
-
Assran, M., Caron, M., Misra, I., Bojanowski, P., Bordes, F., Vincent, P., … & Ballas, N. (2022). Masked Siamese Networks for Label-Efficient Learning. arXiv preprint arXiv:2204.07141.
- matches the representation of an image view containing randomly masked patches to the original unmasked image (occlusion invariant) [MSN]
- Siamese Network with masked augmentation!!
- Pretext task for Network: Vision transformer [data sampling approach]
- Low-shot detection
- Loss function (cross entropy with Mean entropy maximization regularization)
- Joint-embedding architecture avoids reconstruction
- TP leverages the idea of mask-denoising while avoiding pixel and token-level reconstruction
- matches the representation of an image view containing randomly masked patches to the original unmasked image (occlusion invariant) [MSN]
-
Karim, Nazmul, Mamshad Nayeem Rizve, Nazanin Rahnavard, Ajmal Mian, and Mubarak Shah. “UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning.” arXiv preprint arXiv:2203.14542 (2022).
- SOTA: To combat label noise, : i) label correction and ii) sample separation
- employ sort of sample selection mechanism to select a possibly clean data subset
- an off-the-shelf semi-supervised learning method is used for training where rejected samples are treated as unlabeled data.
- Issues: TP shows that current selection methods disproportionately select samples from easy (fast learnable) classes and create class imbalance. [close claim with LeCunn’s DA paper [2022]]
- TP: UNICON: noble! sample selection method, robust to high label noise
- a JS divergence based uniform selection mechanism (no probabilistic modelling or hyperparameter tuning)
- Figure 1 could be more efficient !! just use two of them and a loop.
- Class layer and CL projection layer in parallel.
- Computational issues! divergence for all the samples!!
- Section 4.1 reveals all.
- a JS divergence based uniform selection mechanism (no probabilistic modelling or hyperparameter tuning)
- More of a Semi-sup paper, CL part is auxiliary. [anyways]
- SOTA: To combat label noise, : i) label correction and ii) sample separation
-
Hoffmann, David T., Nadine Behrmann, Juergen Gall, Thomas Brox, and Mehdi Noroozi. “Ranking Info Noise Contrastive Estimation: Boosting Contrastive Learning via Ranked Positives.” arXiv preprint arXiv:2201.11736 (2022).
- TP: New loss function: Ranking Info Noise Contrastive Estimation (RINCE) (modified InfoNCE losses)
- preserved the ranked ordering of the InfoNCE loss. (not all negatives are equal)
- Okay: Now how?: Does it use the supervised information!!!
- Requires a strong notion of hierarchical positive sets!!
- Very irritating formulation [equation 5] - learn to avoid such
- Variation of temperature allows ranking (weight of the losses)
- Application: Class similarities and gradual changes in video (!!)
- Okay: Now how?: Does it use the supervised information!!!
- preserved the ranked ordering of the InfoNCE loss. (not all negatives are equal)
- TP: New loss function: Ranking Info Noise Contrastive Estimation (RINCE) (modified InfoNCE losses)
- Lee, Yoonho, Huaxiu Yao, and Chelsea Finn. “Diversify and Disambiguate: Learning From Underspecified Data.” arXiv preprint arXiv:2202.03418 (2022).
- DivDis: Two stage framework (learn diverse hypothesis [pretraining] and Disambiguate by selecting one of these hypothesis [fine tune])
- Loss function of diversify is interesting
-
Goyal, Priya, Quentin Duval, Isaac Seessel, Mathilde Caron, Mannat Singh, Ishan Misra, Levent Sagun, Armand Joulin, and Piotr Bojanowski. “Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision.” arXiv preprint arXiv:2202.08360 (2022).
- Utilized Uncurated Image data across the globe [LOL! GPU please] (fair!! group): Jokes: Guys be fair in GPU usage.
- Dense 10 Million model params
- 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets
-
obvious result: the more data the better
- key findings: self-supervised learning on random internet data leads to models that are more fair, less biased and less harmful
- Utilized Uncurated Image data across the globe [LOL! GPU please] (fair!! group): Jokes: Guys be fair in GPU usage.
-
Saunshi, Nikunj, Jordan Ash, Surbhi Goel, Dipendra Misra, Cyril Zhang, Sanjeev Arora, Sham Kakade, and Akshay Krishnamurthy. “Understanding Contrastive Learning Requires Incorporating Inductive Biases.” arXiv preprint arXiv:2202.14037 (2022).
-
Argues that requires to include inductive biases of function class and training algorithm to explain the success of CL with previous attempts (augmentation and loss function.) [algorithmic]
- Key findings: ignoring the architecture and the training algorithm can make the current theoretical analyses of contrastive learning vacuous
- Theoretical result: incorporating inductive biases of the function class (ResNet/VGGNet) allows contrastive learning to work with less stringent conditions compared to prior analyses
- different function classes and algorithms (SGD/ADAM) behave very differently on downstream tasks,
- Some outcoms
- Is the contrastive loss indeed a good indicator of downstream performance? No
- Do augmentations overlap sufficiently enough in practice to explain the success of contrastive learning? NO
- Can contrastive learning succeed even when there is little to no overlap? YES
- Three key terms:
- i) Function class sensitivity (encoder architecture and optimization)
- ii) Brittleness of transfer (sometime CL loss reduction cause detrimental impact)
- iii) The disjoint augmentation regime: (when augmentation distribution do not overlap it may lead to false sense of security [may not work for downstream task, especially using linear classifier head]) figure 1.
- Details in section 3 example
- Easy but interesting theory in lemma 4.1
- if augmentation distribution is disjoint then even if contrastive loss is low, the downstream classification loss can be high.
- Key findings: ignoring the architecture and the training algorithm can make the current theoretical analyses of contrastive learning vacuous
-
-
Lee, Hyungtae, and Heesung Kwon. “Self-supervised Contrastive Learning for Cross-domain Hyperspectral Image Representation.” arXiv preprint arXiv:2202.03968 (2022).
- Method: Contrative learning for Hyperspectral image
- uses a property of Hyperspectral: same area’s image are in same class
- Network: Cross-Domain CNN
- Method: Contrative learning for Hyperspectral image
-
Baevski, Alexei, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. “Data2vec: A general framework for self-supervised learning in speech, vision and language.” arXiv preprint arXiv:2202.03555 (2022).
- TP: target for generalized SSL
- core idea is to predict latent representations of the full input data based on a masked view of the input in a self distillation (Transformer architecture)
- data2vec predicts contextualized latent representations that contain information from the entire input
-
Masked prediction with latent target representation.
-
Methods: 1. transformer architecture (Vit-B for vision tasks, ) 2. Masking input 3. Training target
-
Interesing discussion and ablation studies section.
- TP: target for generalized SSL
2014 and previous
- Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26.
- Optimal transport distances are a fundamental family of distances for probability measure
- appealing theoretical properties, excellent performance in retrieval tasks and intuitive formulation
- propose a new family of optimal transport distances that look at transport problems from a maximum entropy perspective
- smooth the classic optimal transport problem with an entropic regularization term, and show that the resulting optimum is also a distance which can be computed through Sinkhorn’s matrix scaling algorithm
- when probability space is a metric space, optimal transport distances, earth mover’s (EMD), define a powerful geometry to compare probabilities.
- Prob. metric Space: distance between two point is a probability distribution function
- Optimal transport distances are a fundamental family of distances for probability measure
- Goldberger, Jacob, Geoffrey E. Hinton, Sam Roweis, and Russ R. Salakhutdinov. “Neighbourhood components analysis.” Advances in neural information processing systems 17 (2004).
- Non-parametric classification model (Early projection)
- application: Dimensional reduction and metric learning.
-
Simple metric based learning (projection and check distance with the same group):
-
The neighborhood class instance should be closure.
- The non-similar instance should be projected far away.
- Non-parametric classification model (Early projection)
-
Divvala, Santosh K., Ali Farhadi, and Carlos Guestrin. “Learning everything about anything: Webly-supervised visual concept learning.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3270-3277. 2014.
- a fully-automated approach for learning extensive models for a wide range of variations (e.g. actions, interactions, attributes and beyond) within any concept
-
Hadsell, Raia, Sumit Chopra, and Yann LeCun. “Dimensionality reduction by learning an invariant mapping.” In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), vol. 2, pp. 1735-1742. IEEE, 2006.
- Algorithm 1: distance based loss optimization [algorithmic]
-
Bromley, Jane, J. W. Bentz, L. Bottou, I. Guyon, Y. LeCun, C. Moore, E. Sackinger, and R. Shah. “Signature Verification using a “Siamese” Time Delay Neural Network.” Int.]. Pattern Recognit. Artzf Intell 7 (1993).
-
Gold in old
-
Siamese network early application for hand writing
-
- Becker, Suzanna, and Geoffrey E. Hinton. “Self-organizing neural network that discovers surfaces in random-dot stereograms.” Nature 355, no. 6356 (1992): 161-163.
- G. W. Taylor, I. Spiro, C. Bregler, and R. Fergus, ‘‘Learning invariance through imitation,’’ in Proc. CVPR, Jun. 2011, pp. 2729–2736, doi:10.1109/CVPR.2011.5995538
- Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
- Gutmann, Michael, and Aapo Hyvärinen. “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models.” In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 297-304. 2010.
-
Weinberger, Kilian Q., John Blitzer, and Lawrence K. Saul. “Distance metric learning for large margin nearest neighbor classification.” In Advances in neural information processing systems, pp. 1473-1480. 2006.
- Triplet loss proposal